VideoVAE+: Large Motion Video Autoencoding with Cross-modal Video VAE
{kind=link}
Abstract
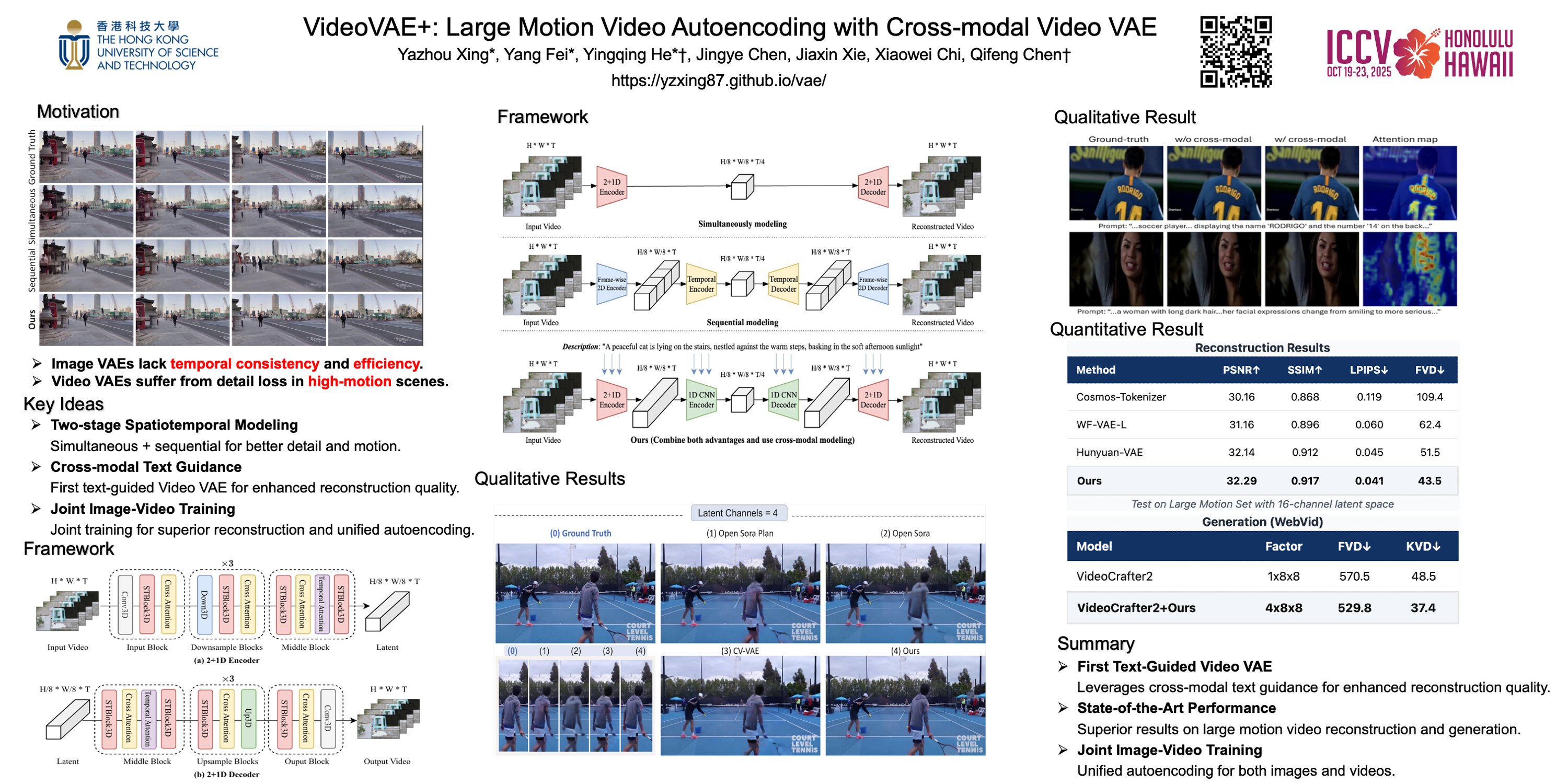
Learning a robust video Variational Autoencoder (VAE) is essential for reducing video redundancy and facilitating efficient video generation. Directly applying image VAEs to individual frames in isolation results in temporal inconsistencies and fails to compress temporal redundancy effectively. Existing works on Video VAEs compress temporal redundancy but struggle to handle videos with large motion effectively. They suffer from issues such as severe image blur and loss of detail in scenarios with large motion. In this paper, we present a powerful video VAE named VideoVAE+ that effectively reconstructs videos with large motion. First, we investigate two architecture choices and propose our simple yet effective architecture with better spatiotemporal joint modeling performance. Second, we propose to leverage the textual information in existing text-to-video datasets and incorporate text guidance during training. The textural guidance is optional during inference. We find that this design enhances the reconstruction quality and preservation of detail. Finally, our models achieve strong performance compared with various baseline approaches in both general videos and large motion videos, demonstrating its effectiveness on the challenging large motion scenarios.