|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Large-scale text-to-image diffusion models have achieved remarkable success in image generation, thereby driving the development of stylized image generation technologies. Recent studies introduce style information by empirically replacing specific features in attention block with style features. However, the relationship between features and style remains unclear. In this paper, we systematically analyze the relationship between features in attention blocks and style. By quantifying the distribution discrepancy induced by style variations using the Wasserstein distance, we find that features in self-attention blocks exhibit high sensitivity to style compared to features in cross-attention blocks. Our analysis provides valuable insights into the contribution of different features to style. Based on our findings, we propose a novel Wasserstein Style Distribution Transform (WSDT) method, which generates stylized images by transforming the distribution of style-sensitive features to align with that of style features. WSDT applies channel adaptive distribution transform to ensure that information not related to the style is not introduced. Our approach is simple yet efficient, optimization-free, and can be seamlessly integrated into attention-based text-to-image diffusion models. Extensive experiments demonstrate the effectiveness of our approach in stylized image generation tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 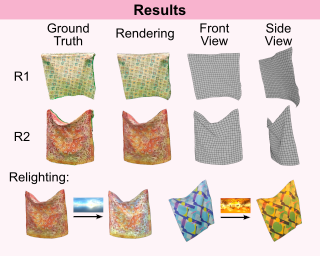
Abstract
The reconstruction of three-dimensional dynamic scenes is a well-established yet challenging task within the domain of computer vision. In this paper, we propose a novel approach that combines the domains of 3D geometry reconstruction and appearance estimation for physically based rendering and present a system that is able to perform both tasks for fabrics, utilizing only a single monocular RGB video sequence as input. In order to obtain realistic and high-quality deformations and renderings, a physical simulation of the cloth geometry and differentiable rendering are employed. In this paper, we introduce two novel regularization terms for the 3D reconstruction task that improve the plausibility of the reconstruction. In comparison with the most recent methods in the field, we have reduced the error in the 3D reconstruction by a factor of $2.64$ while requiring a medium runtime of $30$ min per scene. Furthermore, the optimized motion achieves sufficient quality to perform an appearance estimation of the deforming object, recovering sharp details from this single monocular RGB video.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In this paper, we present a generalizable method for 3D surface reconstruction from raw point clouds or pre-estimated 3D Gaussians by 3DGS from RGB images. Unlike existing coordinate-based methods which are often computationally intensive when rendering explicit surfaces, our proposed method, named **RayletDF**, introduces a new technique called raylet distance field, which aims to directly predict surface points from query rays. Our pipeline consists of three key modules: a raylet feature extractor, a raylet distance field predictor, and a multi-raylet blender. These components work together to extract fine-grained local geometric features, predict raylet distances, and aggregate multiple predictions to reconstruct precise surface points. We extensively evaluate our method on multiple public real-world datasets, demonstrating superior performance in surface reconstruction from point clouds or 3D Gaussians. Most notably, our method achieves exceptional generalization ability, successfully recovering 3D surfaces in a single-forward pass across unseen datasets in testing.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Quad meshes play a crucial role in computer graphics applications, yet automatically generating high-quality quad meshes remains challenging. Traditional quadrangulation approaches rely on local geometric features and manual constraints, often producing suboptimal mesh layouts that fail to capture global shape semantics. We introduce NeuFrameQ, a novel learning-based framework for scalable and generalizable mesh quadrangulation via frame field prediction. We first create a large-scale dataset of high-quality quad meshes with various shapes to serve as priors of domain knowledge. Empowered by this dataset, we employ a connectivity-agnostic learning approach that operates on point clouds with normals, enabling robust processing of complex mesh geometries. By decomposing frame field prediction into direction regression and magnitude estimation tasks, we effectively handle the ill-posed nature in frame field estimation. We also employ the polyvector representation and computing mechanism in both tasks to handle the inherent ambiguities in frame field representation. Extensive experiments demonstrate that NeuFrameQ produces high-quality quad meshes with superior semantic alignment, also for geometries derived from neural fields. Our method significantly advances the state of the art in automatic quad mesh generation, bridging the gap between neural content creation and production-ready geometric assets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Modeling human-scene interactions (HSI) is essential for understanding and simulating everyday human behaviors. Recent approaches utilizing generative modeling have made progress in this domain; however, they are limited in controllability and flexibility for real-world applications. To address these challenges, we propose reformulating the HSI modeling problem as Scene-aware Motion In-betweening---a more tractable and practical task. We introduce SceneMI, a framework that supports several practical applications, including keyframe-guided character animation in 3D scenes and enhancing the motion quality of imperfect HSI data. SceneMI employs dual scene descriptors to comprehensively encode global and local scene context. Furthermore, our framework leverages the inherent denoising nature of diffusion models to generalize on noisy keyframes.Experimental results demonstrate SceneMI's effectiveness in scene-aware keyframe in-betweening and generalization to the real-world GIMO dataset, where motions and scenes are acquired by noisy IMU sensors and smartphones. We further showcase SceneMI's applicability in HSI reconstruction from monocular videos.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Understanding 3D cell shape is crucial in biomedical research, where morphology serves as a key indicator of disease, cellular state, and drug response. However, existing 3D point cloud classification models often lack interpretability, making it difficult to extract biologically meaningful insights. To address this, we propose PointMIL, an inherently interpretable point cloud classifier using Multiple Instance Learning (MIL). Unlike other methods that rely on global interpretations, PointMIL simultaneously improves accuracy of point cloud-based classifier backbones and provides fine-grained, point-specific explanations, pinpointing the most informative regions of 3D shapes, without requiring $\textit{post-hoc}$ analysis. We demonstrate PointMIL on two publicly available datasets of biological cells showing state-of-the-art mACC (97.3\%) and F1 (97.5\%) on the IntrA biomedical dataset. Additionally, we introduce a novel dataset of drug-treated cancer cells (Morph3DCell), to show PointMIL's ability to reveal the morphological effects of drug treatments at a fine-grained level, with implications for drug discovery and mechanism-of-action prediction. Beyond biomedical applications, we show that PointMIL also offers quality interpretations and improves the classification accuracy on standard shape benchmarks such as ModelNet40 and ScanObjectNN, demonstrating its generalisation to broader 3D object recognition tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Geometric consistency, i.e. the preservation of neighbourhoods, is a natural and strong prior in 3D shape matching. Geometrically consistent matchings are crucial for many downstream applications, such as texture transfer or statistical shape modelling. Yet, in practice, geometric consistency is often overlooked, or only achieved under severely limiting assumptions (e.g.~a good initialisation). In this work, we propose a novel formalism for computing globally optimal and geometrically consistent matchings between 3D shapes which is scalable in practice. Our key idea is to represent the surface of the source shape as a collection of cyclic paths, which are then consistently matched to the target shape. Mathematically, we construct a hyper product graph (between source and target shape), and then cast 3D shape matching as a minimum-cost circulation flow problem in this hyper graph, which yields global geometrically consistent matchings between both shapes. We empirically show that our formalism is efficiently solvable and that it leads to high-quality results.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 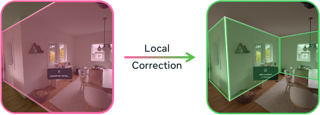
Abstract
We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 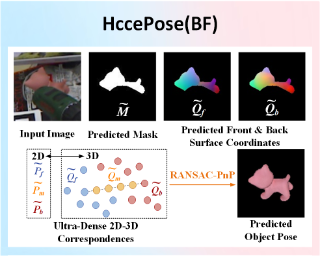
Abstract
In pose estimation for seen objects, a prevalent pipeline involves using neural networks to predict dense 3D coordinates of the object surface on 2D images, which are then used to establish dense 2D-3D correspondences. However, current methods primarily focus on more efficient encoding techniques to improve the precision of predicted 3D coordinates on the object's front surface, overlooking the potential benefits of incorporating the back surface and interior of the object. To better utilize the full surface and interior of the object, this study predicts 3D coordinates of both the object's front and back surfaces and densely samples 3D coordinates between them. This process creates ultra-dense 2D-3D correspondences, effectively enhancing pose estimation accuracy based on the Perspective-n-Point (PnP) algorithm. Additionally, we propose Hierarchical Continuous Coordinate Encoding (HCCE) to provide a more accurate and efficient representation of front and back surface coordinates. Experimental results show that, compared to existing state-of-the-art (SOTA) methods on the BOP website, the proposed approach outperforms across seven classic BOP core datasets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Video Anomaly Detection (VAD) is a challenging task due to the variability of anomalous events and the limited availability of labeled data. Under the Weakly-Supervised VAD (WSVAD) paradigm, only video-level labels are provided during training, while predictions are made at the frame level. Although state-of-the-art models perform well on simple anomalies (e.g., explosions), they struggle with complex real-world events (e.g., shoplifting). This difficulty stems from two key issues: (1) the inability of current models to address the diversity of anomaly types, as they process all categories with a shared model, overlooking category-specific features; and (2) the weak supervision signal, which lacks precise temporal information, limiting the ability to capture nuanced anomalous patterns blended with normal events. To address these challenges, we propose Gaussian Splatting-guided Mixture of Experts (GS-MoE), a novel framework that employs a set of expert models, each specialized in capturing specific anomaly types. These experts are guided by a temporal Gaussian splatting loss, enabling the model to leverage temporal consistency and enhance weak supervision. The Gaussian splatting approach encourages a more precise and comprehensive representation of anomalies by focusing on temporal segments most likely to contain abnormal events. The predictions from these specialized experts are integrated through a …
|
|
Highlight
|
Kaleidoscopic Background Attack: Disrupting Pose Estimation with Multi-Fold Radial Symmetry Textures
Poster
[ Exhibit Hall I ] 
Abstract
Camera pose estimation is a fundamental computer vision task that is essential for applications like visual localization and multi-view stereo reconstruction. In the object-centric scenarios with sparse inputs, the accuracy of pose estimation can be significantly influenced by background textures that occupy major portions of the images across different viewpoints. In light of this, we introduce the Kaleidoscopic Background Attack (KBA), which uses identical segments to form discs with multi-fold radial symmetry. These discs maintain high similarity across different viewpoints, enabling effective attacks on pose estimation models even with natural texture segments. Additionally, a projected orientation consistency loss is proposed to optimize the kaleidoscopic segments, leading to significant enhancement in the attack effectiveness. Experimental results show that adversarial kaleidoscopic backgrounds optimized by KBA can effectively attack various camera pose estimation models.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We introduce UnrealZoo, a rich collection of 100 photo-realistic 3D virtual worlds built on Unreal Engine, designed to reflect the complexity and variability of open worlds with scales up to $16 km^2$ landscapes. Additionally, we offer a rich variety of playable entities including humans, animals, robots, and vehicles for embodied AI. We extend UnrealCV with optimized Python APIs and tools for data collection, environment augmentation, distributed training, and benchmarking, achieving significant improvements in the efficiency of rendering and communication, to support advanced applications, such as multi-agent interactions. Our experimental evaluation across complex navigation and tracking tasks reveals two key insights: first, the substantial benefits of the diversity of environments for developing generalizable reinforcement learning (RL) agents; second, the persistent challenges that current embodied agents face in open-world settings. These challenges include transferring to a new embodiment at test time, managing latency in closed-loop control systems for dynamic environments, and effectively reasoning about complex 3D spatial structures in unstructured terrain. UnrealZoo thus provides both a powerful testing ground and a pathway toward more capable embodied AI systems for real-world deployment.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 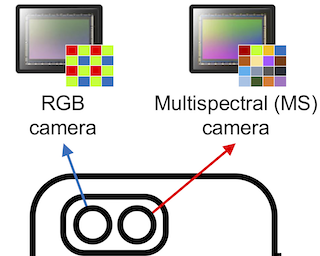
Abstract
Multispectral (MS) images capture detailed scene information across a wide range of spectral bands, making them invaluable for applications requiring rich spectral data. Integrating MS imaging into multi-camera devices, such as smartphones, has the potential to enhance both spectral applications and RGB image quality. A critical step in processing MS data is demosaicing, which reconstructs color information from the mosaic MS images captured by the camera. This paper proposes a method for MS image demosaicing specifically designed for dual-camera setups where both RGB and MS cameras capture the same scene. Our approach leverages co-captured RGB images, which typically have higher spatial fidelity, to guide the demosaicing of lower-fidelity MS images. We introduce the Dual-camera RGB-MS Dataset -- a large collection of paired RGB and MS mosaiced images with ground-truth demosaiced outputs -- that enables training and evaluation of our method. Experimental results demonstrate that our method achieves state-of-the-art accuracy compared to existing techniques.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Diffusion models like Stable Diffusion have become prominent in visual synthesis tasks due to their powerful customization capabilities. However, these capabilities also introduce significant security risks, such as deepfakes and copyright infringement. To mitigate these risks, a class of methods known as protective perturbation emerged, which prevents image misuse by injecting imperceptible adversarial noise.On the other hand, purification methods can effectively remove the protective perturbation, thereby exposing images again to the risk of malicious forgery.In this work, we formalize the anti-purification task, highlighting the challenges that existing approaches can not address properly, and propose a solution named **AntiPure**.AntiPure is robust against the "purification-customization'' workflow, owing to the two types of proposed guidance: 1) Patch-wise Frequency Guidance, which reduces the model’s influence over high-frequency components in the purified image, and 2) Erroneous Timestep Guidance, which disrupts the model’s denoising strategy across different timesteps.With additional guidance, AntiPure embeds imperceptible perturbation patterns resistant to purification, achieving effective output distortion after customization. Experiments show that our approach achieves minimal perceptual discrepancy, maximal distortion, and robust performance, outperforming current protective perturbation methods within the purification-customization workflow.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In recent years, it has been found that “grandmother cells” in the primary visual cortex (V1) of macaques can directly recognize visual input with complex shapes. This inspires us to examine the value of these cells in promoting the research of medical image segmentation. In this paper, we design a Similarity Memory Prior Network (Sim-MPNet) for medical image segmentation. Specifically, we propose a Dynamic Memory Weights–Loss Attention (DMW-LA), which matches and remembers the category features of specific lesions or organs in medical images through the similarity memory prior in the prototype memory bank, thus helping the network to learn subtle texture changes between categories. DMW-LA also dynamically updates the similarity memory prior in reverse through Weight-Loss Dynamic (W-LD) update strategy, effectively assisting the network directly extract category features. In addition, we propose the Double-Similarity Global Internal Enhancement Module (DS-GIM) to deeply explore the internal differences in the feature distribution of input data through cosine similarity and euclidean distance. Extensive experiments on four public datasets show that Sim-MPNet has better segmentation performance than other state-of-the-art methods. Our code is available on https://anonymous.4open.science/r/Sim-MPNet.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Vision-language tracking aims to locate the target object in the video sequence using a template patch and a language description provided in the initial frame. To achieve robust tracking, especially in complex long-term scenarios that reflect real-world conditions as recently highlighted by MGIT, it is essential not only to characterize the target features but also to utilize the context features related to the target. However, the visual and textual target-context cues derived from the initial prompts generally align only with the initial target state. Due to their dynamic nature, target states are constantly changing, particularly in complex long-term sequences. It is intractable for these cues to continuously guide Vision-Language Trackers (VLTs). Furthermore, for the text prompts with diverse expressions, our experiments reveal that existing VLTs struggle to discern which words pertain to the target or the context, complicating the utilization of textual cues. In this work, we present a novel tracker named ATCTrack, which can obtain multimodal cues Aligned with the dynamic target states through comprehensive Target-Context feature modeling, thereby achieving robust tracking. Specifically, (1) for the visual modality, we propose an effective temporal visual target-context modeling approach that provides the tracker with timely visual cues. (2) For the textual …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Event cameras rely on motion to obtain information about scene appearance. In other words, for event cameras, motion and appearance are seen both or neither, which are encoded in the output event stream. Previous works consider recovering these two visual quantities as separate tasks, which does not fit with the nature of event cameras and neglects the inherent relations between both tasks. In this paper, we propose an unsupervised learning framework that jointly estimates optical flow (motion) and image inten-sity (appearance), with a single network. Starting from the event generation model, we newly derive the event-based photometric error as a function of optical flow and image intensity, which is further combined with the contrast maximization framework, yielding a comprehensive loss function that provides proper constraints for both flow and intensity estimation. Exhaustive experiments show that our model achieves state-of-the-art performance for both optical flow (achieves 20% and 25% improvement in EPE and AE respectively in the unsupervised learning category) and intensity estimation (produces competitive results with other baselines, particularly in high dynamic range scenarios). Last but not least, our model achieves shorter inference time than all the other optical flow models and many of the image reconstruction models, while they …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 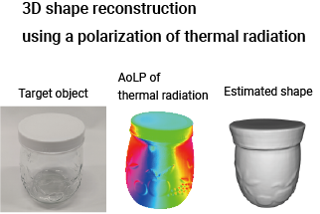
Abstract
This paper introduces a novel method for detailed 3D shape reconstruction utilizing thermal polarization cues. Unlike state-of-the-art methods, the proposed approach is independent of illumination, material properties, and heating processes. In this paper, we formulate a general theory of polarization observation and show that long-wave infrared (LWIR) polarimetric imaging is free from the ambiguities that affect visible polarization analyses. Subsequently, we propose a method for recovering detailed 3D shapes using thermal polarimetric images, showing that our approach effectively reconstructs fine details on heterogeneous materials and outperforms existing techniques.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 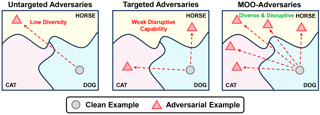
Abstract
Adversarially robust knowledge distillation transfers the robustness of a large-scale teacher model to a lightweight student while preserving natural performance. However, foundation Vision-Language Models (VLMs) also demand the transfer of zero-shot inference capabilities. We find that standard robust distillation using untargeted adversarial examples fails to transfer out-of-distribution (zero-shot) robustness, as these adversaries primarily push inputs away from their original distribution, exploring a limited portion of the teacher’s decision space and miss more diverse failure modes. A natural solution is to generate multiple targeted adversaries that traverse diverse paths across decision boundaries. Thus, these adversaries probe a broader region of the teacher’s decision surface. However, naive targeted adversary optimization often converges to local optima within a single category’s decision region, limiting the diversity. To address this, we propose a Multi-Objective Optimization (MOO)-based adversarial distillation framework that transfers robustness from large VLMs to lightweight ones by exploiting adversaries with two main objectives: misclassification and category-level adversarial diversity. Theoretically, we show that optimizing for diversity mitigates adversarial collapse into local optima, ensuring adversaries span multiple decision regions and capture the teacher’s generalizable robust features. Extensive experiments demonstrate the superiority of our method over state-of-the-art adversarial learning across diverse scenarios.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 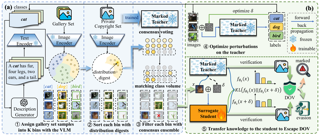
Abstract
Modern over-parameterized deep models are highly data-dependent, with large scale general-purpose and domain-specific datasets serving as the bedrock for rapid advancements. However, many datasets are proprietary or contain sensitive information, making unrestricted model training problematic. In the open world where data thefts cannot be fully prevented, Dataset Ownership Verification (DOV) has emerged as a promising method to protect copyright by detecting unauthorized model training and tracing illicit activities. Due to its diversity and superior stealth, evading DOV is considered extremely challenging. However, this paper identifies that previous studies have relied on oversimplistic evasion attacks for evaluation, leading to a false sense of security. We introduce a unified evasion framework, in which a teacher model first learns from the copyright dataset and then transfers task-relevant yet identifier-independent domain knowledge to a surrogate student using an out-of-distribution (OOD) dataset as the intermediary. Leveraging Vision-Language Models and Large Language Models, we curate the most informative and reliable subsets from the OOD gallery set as the final transfer set, and propose selectively transferring task-oriented knowledge to achieve a better trade-off between generalization and evasion effectiveness. Experiments across diverse datasets covering eleven DOV methods demonstrate our approach simultaneously eliminates all copyright identifiers and significantly outperforms …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Multi-task learning (MTL) trains deep neural networks to optimize several objectives simultaneously using a shared backbone, which leads to reduced computational costs, improved data efficiency, and enhanced performance through cross-task knowledge sharing. Although recent gradient manipulation techniques seek a common descent direction to benefit all tasks, conventional empirical loss minimization still leaves models prone to overfitting and gradient conflicts. To address this, we introduce a novel MTL framework that leverages weight perturbation to regulate gradient norms. thus improve generalization. By carefully modulating weight perturbations, our approach harmonizes task-specific gradients, reducing conflicts and encouraging more robust learning across tasks. Theoretical insights reveal that controlling the gradient norm through weight perturbation directly contributes to better generalization. Extensive experiments across diverse applications demonstrate that our method significantly outperforms existing gradient-based MTL techniques in terms of task performance and overall model robustness.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Recently, open-vocabulary semantic segmentation has garnered growing attention. Most current methods leverage vision-language models like CLIP to recognize unseen categories through their zero-shot capabilities. However, CLIP struggles to establish potential spatial dependencies among scene objects due to its holistic pre-training objective, causing sub-optimal results. In this paper, we propose a DEnoising learning framework based on the Diffusion model for Open-vocabulary semantic Segmentation, called DEDOS, which is aimed at constructing the scene skeleton. Motivation stems from the fact that diffusion models incorporate not only the visual appearance of objects but also embed rich scene spatial priors. Our core idea is to view images as labels embedded with "noise"—non-essential details for perceptual tasks—and to disentangle the intrinsic scene prior from the diffusion feature during the denoising process of the images. Specifically, to fully harness the scene prior knowledge of the diffusion model, we introduce learnable proxy queries during the denoising process. Meanwhile, we leverage the robustness of CLIP features to texture shifts as supervision, guiding proxy queries to focus on constructing the scene skeleton and avoiding interference from texture information in the diffusion feature space. Finally, we enhance spatial understanding within CLIP features using proxy queries, which also serve as an interface …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We present a method for Sparse view reconstruction with surface element splatting that runs within 2 minutes on a consumer grade GPU. While few methods address sparse radiance field learning from noisy or unposed sparse cameras, shape recovery remains relatively underexplored in this setting. Several radiance and shape learning test-time optimization methods address the sparse posed setting by learning data priors or using combinations of external monocular geometry priors. Differently, we propose an efficient and simple pipeline harnessing a single recent 3D foundation model. We leverage its various task heads, notably point maps and camera initializations to instantiate a bundle adjusting 2D Gaussian Splatting (2DGS) model, and image correspondences to guide camera optimization midst 2DGS training. Key to our contribution is a novel formulation of splatted color variance along rays, which can be computed efficiently. Reducing this moment in training leads to more accurate shape reconstructions. We demonstrate stat-of-the-art performances in the sparse uncalibrated setting in reconstruction and novel view Benchmarks based on established multi-view datasets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Human motion modeling traditionally separates motion generation and estimation into distinct tasks with specialized models. Motion generation models focus on creating diverse, realistic motions from inputs like text, audio, or keyframes, while motion estimation models aim to reconstruct accurate motion trajectories from observations like videos. Despite sharing underlying representations of temporal dynamics and kinematics, this separation limits knowledge transfer between tasks and requires maintaining separate models. We present GENMO, a unified Generalist Model for Human Motion that bridges motion estimation and generation in a single framework. Our key insight is to reformulate motion estimation as constrained motion generation, where the output motion must precisely satisfy observed conditioning signals. Leveraging the synergy between regression and diffusion, GENMO achieves accurate global motion estimation while enabling diverse motion generation. We also introduce an estimation-guided training objective that exploits in-the-wild videos with 2D annotations and text descriptions to enhance generative diversity. Furthermore, our novel architecture handles variable-length motions and mixed multimodal conditions (text, audio, video) at different time intervals, offering flexible control. This unified approach creates synergistic benefits: generative priors improve estimated motions under challenging conditions like occlusions, while diverse video data enhances generation capabilities. Extensive experiments demonstrate GENMO's effectiveness as a generalist framework …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We present MeshLLM, a novel framework that leverages large language models (LLMs) to understand and generate text-serialized 3D meshes. Our approach addresses key limitations in existing methods, including the limited dataset scale when catering to LLMs' token length and the loss of 3D structural information during mesh serialization. We introduce a Primitive-Mesh decomposition strategy, which divides 3D meshes into structurally meaningful subunits. This enables the creation of a large-scale dataset with 1500k+ samples, almost 50x larger than previous methods, which aligns better with the LLM scaling law principles. Furthermore, we propose inferring face connectivity from vertices and local mesh assembly training strategies, significantly enhancing the LLMs' ability to capture mesh topology and spatial structures. Experiments show that MeshLLM outperforms the state-of-the-art LLaMA-Mesh in both mesh generation quality and shape understanding, highlighting its great potential in processing text-serialized 3D meshes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 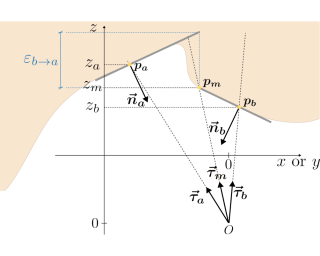
Abstract
Recovering a 3D surface from its surface normal map, a problem known as normal integration, is a key component for photometric shape reconstruction techniques such as shape-from-shading and photometric stereo. The vast majority of existing approaches for normal integration handle only implicitly the presence of depth discontinuities and are limited to orthographic or ideal pinhole cameras. In this paper, we propose a novel formulation that allows modeling discontinuities explicitly and handling generic central cameras. Our key idea is based on a local planarity assumption, that we model through constraints between surface normals and ray directions. Compared to existing methods, our approach more accurately approximates the relation between depth and surface normals, achieves state-of-the-art results on the standard normal integration benchmark, and is the first to directly handle generic central camera models.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
WonderPlay is a novel framework integrating physics simulation with video generation for generating action-conditioned dynamic 3D scenes from a single image. Our hybrid generative simulator first uses a physics solver to simulate coarse 3D dynamics, which subsequently conditions a video generator to produce a video with finer, more realistic motion. The generated video is then used to update the simulated dynamic 3D scene, closing the loop between the physics solver and the video generator. This approach enables intuitive user control to be combined with the accurate dynamics of physics-based simulators and the expressivity of diffusion-based video generators. Experimental results demonstrate that WonderPlay enables users to interact with various scenes of diverse content, including cloth, sand, snow, liquid, smoke, elasticity, and rigid bodies -- all using a single image input. Code will be made public.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 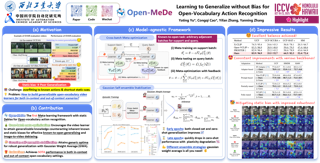
Abstract
Leveraging the effective visual-text alignment and static generalizability from CLIP, recent video learners adopt CLIP initialization with further regularization or recombination for generalization in open-vocabulary action recognition in-context. However, due to the static bias of CLIP, such video learners tend to overfit on shortcut static features, thereby compromising their generalizability, especially to novel out-of-context actions. To address this issue, we introduce $\textbf{Open-MeDe}$, a novel Meta-optimization framework with static Debiasing for Open-vocabulary action recognition. From a fresh perspective of generalization, Open-MeDe adopts a meta-learning approach to improve $\textbf{known-to-open generalizing}$ and $\textbf{image-to-video debiasing}$ in a cost-effective manner. Specifically, Open-MeDe introduces a cross-batch meta-optimization scheme that explicitly encourages video learners to quickly generalize to arbitrary subsequent data via virtual evaluation, steering a smoother optimization landscape. In effect, the free of CLIP regularization during optimization implicitly mitigates the inherent static bias of the video meta-learner. We further apply self-ensemble over the optimization trajectory to obtain generic optimal parameters that can achieve robust generalization to both in-context and out-of-context novel data. Extensive evaluations show that Open-MeDe not only surpasses state-of-the-art regularization methods tailored for in-context open-vocabulary action recognition but also substantially excels in out-of-context scenarios.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Remote Photoplethysmography (rPPG) enables non-contact extraction of physiological signals, providing significant advantages in medical monitoring, emotion recognition, and face anti-spoofing. However, the extraction of reliable rPPG signals is hindered by motion variations in real-world environments, leading to entanglement issue. To address the challenge, we employ the Generalizable Gaussian Model (GGM) to disentangle geometry and chroma components with 4D Gaussian representations. Employing the GGM for robust rPPG estimation is non-trivial. Firstly, there are no camera parameters in the dataset, resulting in the inability to render video from 4D Gaussian. The ``4D virtual camera'' is proposed to construct extra Gaussian parameters to describe view and motion changes, giving the ability to render video with the fixed virtual camera parameters. Further, the chroma component is still not explicitly decoupled in 4D Gaussian representation. Explicit motion modeling (EMM) is designed to decouple the motion variation in an unsupervised manner. Explicit chroma modeling (ECM) is tailored to decouple specular, physiological, and noise signals, respectively. To validate our approach, we expand existing rPPG datasets to include various motion and illumination interference scenarios, demonstrating the effectiveness of our method in real-world settings. The code will be available after acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 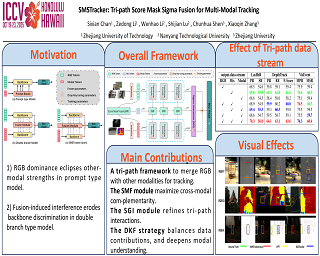
Abstract
Multi-modal object tracking has emerged as a significant research focus in computer vision due to its robustness in complex environments, such as exposure variations, blur, and occlusions. Despite the fact that existing studies integrate supplementary modal information into pre-trained RGB trackers through visual prompt mechanisms, this exhibits a critical limitation: they inherently prioritize RGB information as the dominant modality, thereby underutilizing the complementary information of alternative modal.To address this fundamental limitation, we present SMSTracker, an innovative tri-path score mask sigma fusion framework for multi-modal tracking, including three key modules. Firstly, we design a tri-path Score Mask Fusion (SMF) module to evaluate and quantify the reliability of each modality, allowing optimal exploitation of complementary features between modalities. Secondly, we introduce a pioneering Sigma Interaction (SGI) module to facilitate a sophisticated fusion of modal features across tri-branches, representing the first application of Sigma point-based feature interaction in object tracking tasks. Furthermore, we advance a Drop Key Fine-tuning (DKF) strategy to address the inherent challenge of unequal data contribution in multi-modal learning scenarios, thereby enhancing the model's capacity for comprehensive multi-modal information processing.Finally, extensive experiments on RGB+Thermal, RGB+Depth, and RGB+Event datasets demonstrate the significant performance improvements achieved by SMSTracker over existing state-of-the-art methods. …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Text-based person search aims to retrieve specific individuals across camera networks using natural language descriptions. However, current benchmarks often exhibit biases towards common actions like walking or standing, neglecting the critical need for identifying abnormal behaviors in real-world scenarios. To meet such demands, we propose a new task, text-based person anomaly search, locating pedestrians engaged in both routine or anomalous activities via text. To enable the training and evaluation of this new task, we construct a large-scale image-text Pedestrian Anomaly Behavior (PAB) benchmark, featuring a broad spectrum of actions, e.g., running, performing, playing soccer, and the corresponding anomalies, e.g., lying, being hit, and falling of the same identity. The training set of PAB comprises 1,013,605 synthesized image-text pairs of both normalities and anomalies, while the test set includes 1,978 real-world image-text pairs. To validate the potential of PAB, we introduce a cross-modal pose-aware framework, which integrates human pose patterns with identity-based hard negative pair sampling. Extensive experiments on the proposed benchmark show that synthetic training data facilitates the fine-grained behavior retrieval, and the proposed pose-aware method arrives at 84.93% recall@1 accuracy, surpassing other competitive methods.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Evacuation simulations are vital for improving safety, pinpointing risks, and refining emergency protocols. However, no existing methods can simulate realistic, personalized, and online 3D evacuation motions. In this paper, aligned with the sensory-decision-motor (SDM) flow of the human brain, we propose an online SDM-united 3D evacuation simulation framework with a 3D-adaptive Social Force Model and a proxemics-aware personalization method. Additionally, we introduce Part-level Force Visualization to assist in evacuation analysis. We experimentally validate that our framework supports online personalized dynamic path planning and behaviors throughout the evacuation process, and is compatible with uneven terrain. Visually, our method generates evacuation results that are more realistic and plausible, providing enhanced insights for evacuation strategy development. The code will be released for research purposes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 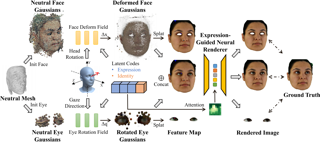
Abstract
Gaze estimation encounters generalization challenges when dealing with out-of-distribution data. To address this problem, recent methods use neural radiance fields (NeRF) to generate augmented data. However, existing methods based on NeRF are computationally expensive and lack facial details. 3D Gaussian Splatting (3DGS) has become the prevailing representation of neural fields. While 3DGS has been extensively examined in head avatars, it faces challenges with accurate gaze control and generalization across different subjects. In this work, we propose GazeGaussian, the first high-fidelity gaze redirection method that uses a two-stream 3DGS model to represent the face and eye regions separately. Leveraging the unstructured nature of 3DGS, we develop a novel representation of the eye for rigid eye rotation based on the target gaze direction. To enable synthesis generalization across various subjects, we integrate an expression-guided module to inject subject-specific information into the neural renderer. Comprehensive experiments show that GazeGaussian outperforms existing methods in rendering speed, gaze redirection accuracy, and facial synthesis across multiple datasets. The code will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Understanding radiologists' eye movement during Computed Tomography (CT) reading is crucial for developing effective interpretable computer-aided diagnosis systems. However, CT research in this area has been limited by the lack of publicly available eye-tracking datasets and the three-dimensional complexity of CT volumes. To address these challenges, we present the first publicly available eye gaze dataset on CT, called CT-ScanGaze. Then, we introduce CT-Searcher, a novel 3D scanpath predictor designed specifically to process CT volumes and generate radiologist-like 3D fixation sequences, overcoming the limitations of current scanpath predictors that only handle 2D inputs. Since deep learning models benefit from a pretraining step, we develop a pipeline that converts existing 2D gaze datasets into 3D gaze data to pretrain CT-Searcher. Through both qualitative and quantitative evaluations on CT-ScanGaze, we demonstrate the effectiveness of our approach and provide a comprehensive assessment framework for 3D scanpath prediction in medical imaging.Code and data will be available for research purposes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 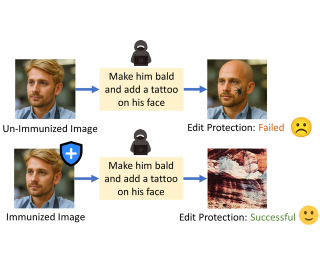
Abstract
Advancements in diffusion models have enabled effortless image editing via text prompts, raising concerns about image security. Attackers with access to user images can exploit these tools for malicious edits. Recent defenses attempt to protect images by adding a limited noise in the pixel space to disrupt the functioning of diffusion-based editing models. However, the adversarial noise added by previous methods is easily noticeable to the human eye. Moreover, most of these methods are not robust to purification techniques like JPEG compression under a feasible pixel budget. We propose a novel optimization approach that introduces adversarial perturbations directly in the frequency domain by modifying the Discrete Cosine Transform (DCT) coefficients of the input image. By leveraging the JPEG pipeline, our method generates adversarial images that effectively prevent malicious image editing. Extensive experiments across a variety of tasks and datasets demonstrate that our approach introduces fewer visual artifacts while maintaining similar levels of edit protection and robustness to noise purification techniques.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Multimodal large language models (MLLMs) have made significant progress in vision-language understanding, yet effectively aligning different modalities remains a fundamental challenge. We present a framework that unifies multimodal understanding by applying byte-pair encoding to visual tokens. Unlike conventional approaches that rely on modality-specific encoders, our method directly incorporates structural information into visual tokens, mirroring successful tokenization strategies in text-only language models. We introduce a priority-guided encoding scheme that considers both frequency and spatial consistency, coupled with a multi-stage training procedure based on curriculum-driven data composition. These enhancements enable the transformer model to better capture cross-modal relationships and reason with visual information. Comprehensive experiments demonstrate improved performance across diverse vision-language tasks. By bridging the gap between visual and textual representations, our approach contributes to the advancement of more capable and efficient multimodal foundation models.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 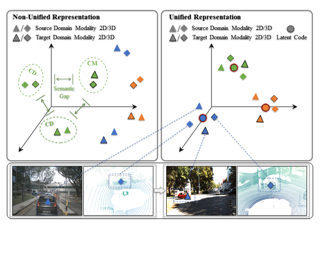
Abstract
Modality or domain distribution shifts pose formidable challenges in 3D semantic segmentation. Existing methods predominantly address either cross-modal or cross-domain adaptation in isolation, leading to insufficient exploration of semantic associations and complementary features in heterogeneous data. To bridge this gap, we present UniDxMD, a unified representation method for cross-modal unsupervised domain adaptation (UDA) in 3D semantic segmentation that simultaneously tackles both cross-modal and cross-domain adaptation objectives. Our core insight is deriving a unified discrete representation from heterogeneous data to mitigate distribution shifts, inspired by vector quantization. Specifically, we propose a differentiable, cluster-based soft quantization mechanism (CSQM) that maps heterogeneous data (spanning modalities and domains) into a shared discrete latent space. Then, we introduce latent space regularization (LSR), leveraging joint prototypes that satisfy semantic relational consistency as learnable anchors to enhance the compactness and semantic discriminability of the discrete latent space. Our method paves the way for advancing cross-modal UDA in 3D semantic segmentation towards the unified representation. Extensive results across four challenging cross-modal UDA scenarios demonstrate the superiority of our method, achieving state-of-the-art performance on multiple benchmarks. Code will be available publicly.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 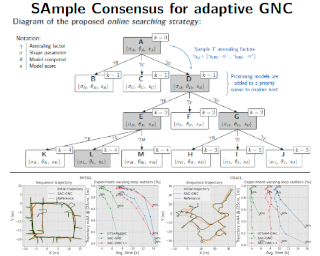
Abstract
Outliers are ubiquitous in geometric vision contexts such as pose estimation and mapping, leading to inaccurate estimates. While robust loss functions tackle outliers, it is challenging to make the estimation robust to the choice of initialization and estimate the appropriate robust loss shape parameter that allows distinguishing inliers from outliers. Graduated non-convexity (GNC) often mitigates these issues. However, typical GNC uses a fixed annealing factor to update the shape parameter, which can lead to low-quality or inefficient estimates. This paper proposes a novel approach to adaptively anneal the shape parameter within a GNC framework. We developed a search strategy that incorporates a sampling of annealing choices and model scorings to select the most promising shape parameter at each GNC iteration. Additionally, we propose new stopping criteria and an initialization technique that improves performance for diverse data, and we show the benefits of combining discrete and continuous robust estimation strategies. We evaluate our method using synthetic and real-world data in two problems: 3D registration and pose graph optimization in SLAM sequences. Our results demonstrate greater efficiency and robustness compared to previous GNC schemes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
3D shape generation has greatly flourished through the development of so-called ``native" 3D diffusion, particularly through the Vectset Diffusion Model (VDM). While recent advancements have shown promising results in generating high-resolution 3D shapes, VDM still struggles at high-speed generation. Challenges exist because of not only difficulties in accelerating diffusion sampling but also VAE decoding in VDM -- areas under-explored in previous works. To address these challenges, we present FlashVDM, a systematic framework for accelerating both VAE and DiT in VDM. For DiT, FlashVDM enables flexible diffusion sampling with as few as 5 inference steps, while maintaining comparable quality, which is made possible by stabilizing consistency distillation with our newly introduced Progressive Flow Distillation technique. For VAE, we introduce a lightning vectset decoder equipped with Adaptive KV Selection, Hierarchical Volume Decoding,, and Efficient Network Design. By exploiting the locality of vectset and the sparsity of shape surface in the volume, the proposed decoder drastically lowers FLOPs, minimizing the overall decoding overhead. We apply FlashVDM to the current state-of-the-art open-source shape generation model Hunyuan3D-2, resulting in Hunyuan3D-2 Turbo. Through systematic evaluation for both generation and reconstruction, we demonstrate that our model outperforms existing fast 3D generation methods by a significant margin, achieving …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
It has been observed that deep neural networks (DNNs) often use both genuine as well as spurious features.In this work, we propose ''Amending Inherent Interpretability via Self-Supervised Masking'' (AIM), a simple yet surprisingly effective method that promotes the network’s utilization of genuine features over spurious alternatives without requiring additional annotations.In particular, AIM uses features at multiple encoding stages to guide a self-supervised, sample-specific feature-masking process. As a result, AIM allows training well-performing and inherently interpretable models that faithfully summarize the decision process.When tested on challenging datasets designed to assess reliance on spurious features and out-of-domain generalization, AIM networks demonstrate significant dual benefits: Evaluations show that AIM improves interpretability, as measured by the Energy Pointing Game (EPG) score, by $\sim$6$-$37\%, while simultaneously enhancing accuracy by $\sim$10$-$40\%. These impressive performance gains are further validated on the standard in-domain CUB-200 dataset for fine-grained classification. The results provide compelling evidence supporting our hypothesis that AIM finds genuine and meaningful features that directly contribute to its improved human interpretability.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Instruction tuning fine-tunes pre-trained Multi-modal Large Language Models (MLLMs) to handle real-world tasks. However, the rapid expansion of visual instruction datasets introduces data redundancy, leading to excessive computational costs. We propose a collaborative framework, DataTailor, which leverages three key principles—informativeness, uniqueness, and representativeness—for effective data selection. We argue that a valuable sample should be informative of the task, non-redundant, and represent the sample distribution (i.e., not an outlier). We further propose practical ways to score against each principle, which automatically adapts to a given dataset without tedious hyperparameter tuning. Comprehensive experiments on various benchmarks demonstrate that DataTailor achieves 101.3\% of the performance of full-data fine-tuning with only 15\% of the data, significantly reducing computational costs while maintaining superior results. This exemplifies the "Less is More" philosophy in MLLM development. The code is in https://anonymous.4open.science/r/DataTailor-5BC3.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis.This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we analyze the performance of latent image and video diffusion representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. For the most informative comparison, we utilize the same model architecture, WALT, across image and video generation objectives. Our results show that video generation pre-training consistently outperforms its image counterpart, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 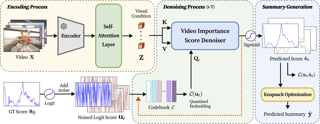
Abstract
Video summarization is a task of shortening a video by choosing a subset of frames while preserving its essential moments. Despite the innate subjectivity of the task, previous works have deterministically regressed to an averaged frame score over multiple raters, ignoring the inherent subjectivity of what constitutes a "good" summary. We propose a novel problem formulation by framing video summarization as a conditional generation task, allowing a model to learn the distribution of good summaries and to generate multiple plausible summaries that better reflect varying human perspectives. Adopting diffusion models for the first time in video summarization, our proposed method, SummDiff, dynamically adapts to visual contexts and generates multiple candidate summaries conditioned on the input video. Extensive experiments demonstrate that SummDiff not only achieves the state-of-the-art performance on various benchmarks but also produces summaries that closely align with individual annotator preferences. Moreover, we provide a deeper insight with novel metrics from an analysis of the knapsack, which is an important last step of generating summaries but has been overlooked in evaluation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper aims to establish correspondences for a set of 2D query points across a video sequence in an online manner. Recent methods leverage future frames to achieve smooth point tracking at the current frame, but they still struggle to find points with significant viewpoint changes after long-term occlusions and inherently cannot achieve online tracking. To overcome these challenges, we develop a novel online tracking framework, named ReTracker, that integrates two advances in image matching with tracking-specific designs. First, a decoder network with a global receptive field is incorporated with a temporal attention module to robustly track points undergoing large location changes. Second, the decoder network is adapted to pretrain on large-scale two-view matching data, which offers significantly greater diversity and volume than tracking data, to learn general matching priors. This pretraining strategy effectively enhances our tracker's ability to handle viewpoint and appearance variations after long-term occlusions. Experiments demonstrate that our method outperforms recent online trackers across multiple benchmarks and achieves competitive or superior performance compared to offline methods. Furthermore, we collect an ego-centric, occlusion-heavy dataset to illustrate the retracking capabilities of our approach. The code and dataset will be released for the reproducibility.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Recent progress in multimodal large language models has markedly enhanced the understanding of short videos (typically under one minute), and several evaluation datasets have emerged accordingly. However, these advancements fall short of meeting the demands of real-world applications such as embodied intelligence for long-term decision-making, in-depth movie reviews and discussions, and live sports commentary, all of which require comprehension of long videos spanning several hours. To address this gap, we introduce LVBench, a benchmark specifically designed for long video understanding. Our dataset comprises publicly sourced videos and encompasses a diverse set of tasks aimed at long video comprehension and information extraction. LVBench is designed to challenge multimodal models to demonstrate long-term memory and extended comprehension capabilities. Our extensive evaluations reveal that current multimodal models still underperform on these demanding long video understanding tasks. Through LVBench, we aim to spur the development of more advanced models capable of tackling the complexities of long video comprehension.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Light Field (LF) images captured under low illumination conditions typically exhibit low quality. Recent learning-based methods for low-light LF enhancement are generally tailored to specific illumination inputs, limiting their performance in real-world scenes. Moreover, how to maintain the inherent view-consistency in the enhanced images also remain as a difficult problem. In this paper, we propose to explore the view consistency for scene-adaptive low-light LF enhancement. We first analyze the view consistency for LF illumination maps and design a self-supervised view-consistent loss to keep the consistency between the illumination maps of different views in LFs. To enhance the model's perception of illumination, we combine both global and local information to estimate the illumination map, which is easily plugged into other models. Subsequently, we use the illumination maps to light up the low-light LF images and restore the corruption to produce the final enhanced image. Extensive experiments demonstrate that our View-Consistency Network (VCNet) outperforms state-of-the-art methods on real-world low-light LF datasets in both fixed lighting conditions and dynamic lighting conditions. Our proposed illumination adjustment is also demonstrated that can comprehensively improve the performance of existing methods in terms of both image quality and view consistency.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Diffusion-based models have recently revolutionized image generation, achieving unprecedented levels of fidelity. However, consistent generation of high-quality images remains challenging partly due to the lack of conditioning mechanisms for perceptual quality. In this work, we propose methods to integrate image quality assessment (IQA) models into diffusion-based generators, enabling quality-aware image generation. We show that diffusion models can learn complex qualitative relationships from both IQA models’ outputs and internal activations. First, we experiment with gradient-based guidance to optimize image quality directly and show this method has limited generalizability. To address this, we introduce IQA-Adapter, a novel framework that conditions generation on target quality levels by learning the implicit relationship between images and quality scores. When conditioned on high target quality, IQA-Adapter can shift the distribution of generated images towards a higher-quality subdomain, and, inversely, it can be used as a degradation model, generating progressively more distorted images when provided with a lower-quality signal. Under high-quality condition, IQA-Adapter achieves up to a 10\% improvement across multiple objective metrics, as confirmed by a user preference study, while preserving generative diversity and content. Furthermore, we extend IQA-Adapter to a reference-based conditioning scenario, utilizing the rich activation space of IQA models to transfer highly specific, …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Accurate monocular 3D object detection (M3OD) is pivotal for safety-critical applications like autonomous driving, yet its reliability deteriorates significantly under real-world domain shifts caused by environmental or sensor variations. To address these shifts, Test-Time Adaptation (TTA) methods have emerged, enabling models to adapt to target distributions during inference. While prior TTA approaches recognize the positive correlation between low uncertainty and high generalization ability, they fail to address the dual uncertainty inherent to M3OD: semantic uncertainty (ambiguous class predictions) and geometric uncertainty (unstable spatial localization). To bridge this gap, we propose Dual Uncertainty Optimization (**DUO**), the first TTA framework designed to jointly minimize both uncertainties for robust M3OD. Through a convex optimization lens, we introduce an innovative convex structure of the focal loss and further derive a novel conjugate loss, enabling label-agnostic uncertainty weighting and balanced learning for high-uncertainty objects. In parallel, we design a semantic-aware normal field constraint that preserves geometric coherence in regions with clear semantic cues, reducing uncertainty from the unstable 3D representation. This dual-branch mechanism forms a complementary loop: enhanced spatial perception improves semantic classification, and robust semantic predictions further refine spatial understanding. Extensive experiments demonstrate the superiority of DUO over existing methods across various datasets and …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 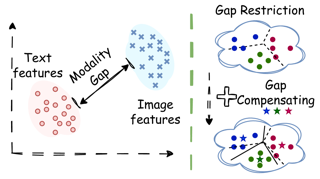
Abstract
Continual learning aims to enable models to learn sequentially from continuously incoming data while retaining performance on previously learned tasks.With the Contrastive Language-Image Pre-trained model (CLIP) exhibiting strong capabilities across various downstream tasks, there has been growing interest in leveraging CLIP for continual learning in such scenarios.Most existing works overlook the inherent modality gap in CLIP, a key factor in its generalization and adaptability. In this paper, we analyze the variations in the modality gap during the fine-tuning of vision-language pre-trained models.Our observations reveal that the modality gap effectively reflects the extent to which pre-trained knowledge is preserved.Based on these insights, we propose a simple yet effective method that improves CLIP’s performance in class-incremental learning.Our approach leverages modality gap preservation to mitigate forgetting and modality gap compensation to enhance the capacity for new data, introducing a novel modality-gap-based perspective for continual learning. Extensive experiments on multiple benchmarks demonstrate that our method outperforms existing approaches without requiring additional replay data.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
While significant advances exist in pseudo-label generation for semi-supervised semantic segmentation, pseudo-label selection remains understudied. Existing methods typically use fixed confidence thresholds to retain high-confidence predictions as pseudo-labels. However, these methods cannot cope with network overconfidence tendency, where correct and incorrect predictions overlap significantly in high-confidence regions, making separation challenging and amplifying model cognitive bias. Meanwhile, the direct discarding of low-confidence predictions disrupts spatial-semantic continuity, causing critical context loss. We propose Confidence Separable Learning (CSL) to address these limitations. CSL formulates pseudo-label selection as a convex optimization problem within the confidence distribution feature space, establishing sample-specific decision boundaries to distinguish reliable from unreliable predictions. Additionally, CSL introduces random masking of reliable pixels to guide the network in learning contextual relationships from low-reliability regions, thereby mitigating the adverse effects of discarding uncertain predictions. Extensive experimental results on the Pascal VOC 2012 and Cityscapes benchmarks show that CSL performs favorably against state-of-the-art methods.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
DUSt3R has recently shown that one can reduce many tasks in multi-view geometry, including estimating camera intrinsics and extrinsics, reconstructing the scene in 3D, and establishing image correspondences, to the prediction of a pair of viewpoint-invariant point maps, i.e., pixel-aligned point clouds defined in a common reference frame. This formulation is elegant and powerful, but unable to tackle dynamic scenes. To address this challenge, we introduce the concept of Dynamic Point Maps (DPM), extending standard point maps to support 4D tasks such as motion segmentation, scene flow estimation, 3D object tracking, and 2D correspondence. Our key intuition is that, when time is introduced, there are several possible spatial and time references that can be used to define the point maps. We identify a minimal subset of such combinations that can be regressed by a network to solve the sub tasks mentioned above. We train a DPM predictor on a mixture of synthetic and real data and evaluate it across diverse benchmarks for video depth prediction, dynamic point cloud reconstruction, 3D scene flow and object pose tracking, achieving state-of-the-art performance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent advances in diffusion models have significantly improved image generation and editing, but extending these capabilities to 3D assets remains challenging, especially for fine-grained edits that require multi-view consistency. Existing methods typically restrict editing to predetermined viewing angles, severely limiting their flexibility and practical applications.We introduce Edit360, a tuning-free framework that extends 2D modifications to multi-view consistent 3D editing. Built upon video diffusion models, Edit360 enables user-specific editing from arbitrary viewpoints while ensuring structural coherence across all views. The framework selects anchor views for 2D modifications and propagates edits across the entire 360-degree range. To achieve this, Edit360 introduces a novel Anchor-View Editing Propagation mechanism, which effectively aligns and merges multi-view information within the latent and attention spaces of diffusion models. The resulting edited multi-view sequences facilitate the reconstruction of high-quality 3D assets, enabling customizable 3D content creation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Facial attractiveness prediction (FAP) has long been an important computer vision task, which could be widely applied in live videos with facial retouching. However, previous FAP datasets are either small or closed-source. Moreover, the corresponding FAP models exhibit limited generalization and adaptation ability.To overcome these limitations, we introduce the first large-scale FAP dataset LiveBeauty specifically designed for live video scenarios wherein face images may be real-time processed for aesthetics purposes.10,000 face images are collected directly from a live streaming platform, with 200,000 corresponding attractiveness annotations obtained from a well-devised subjective experiment, making LiveBeauty the largest open-access FAP dataset. Based on the built dataset, a novel FAP method named Facial Prior Enhanced Multi-modal model (FPEM) is proposed to measure the attractiveness of facial images.Extensive experiments conducted on both LiveBeauty and other open-source FAP datasets demonstrate that our proposed method achieves state-of-the-art performance. The dataset will be available soon.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 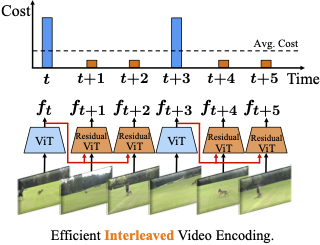
Abstract
Several video understanding tasks, such as natural language temporal video grounding, temporal activity localization, and audio description generation, require "temporally dense" reasoning over frames sampled at high temporal resolution. However, computing frame-level features for these tasks is computationally expensive given the temporal resolution requirements. In this paper, we make three contributions to reduce the cost of computing features for temporally dense tasks. First, we introduce a vision transformer (ViT) architecture, dubbed ResidualViT, that leverages the large temporal redundancy in videos to efficiently compute temporally dense frame-level features. Our architecture incorporates (i) learnable residual connections that ensure temporal consistency across consecutive frames and (ii) a token reduction module that enhances processing speed by selectively discarding temporally redundant information while reusing weights of a pretrained foundation model.Second, we propose a lightweight distillation strategy to approximate the frame-level features of the original foundation model. Finally, we evaluate our approach across four tasks and five datasets, in both zero-shot and fully supervised settings, demonstrating significant reductions in computational cost (up to 60\%) and improvements in inference speed (up to 2.5$\times$ faster), all while closely approximating the accuracy of the original foundation model.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA have transformed vision model adaptation, enabling the rapid deployment of customized models. However, the compactness of LoRA adaptations introduces new safety concerns, particularly their vulnerability to model extraction attacks. This paper introduces a new focus of model extraction attacks named LoRA extraction that extracts LoRA-adaptive models based on a public pre-trained model. We then propose a novel extraction method called StolenLoRA which trains a substitute model to extract the functionality of a LoRA-adapted model using synthetic data. StolenLoRA leverages a Large Language Model to craft effective prompts for data generation, and it incorporates a Disagreement-based Semi-supervised Learning (DSL) strategy to maximize information gain from limited queries.Our experiments demonstrate the effectiveness of StolenLoRA, achieving up to a 96.60% attack success rate with only 10k queries, even in cross-backbone scenarios where the attacker and victim models utilize different pre-trained backbones. These findings reveal the specific vulnerability of LoRA-adapted models to this type of extraction and underscore the urgent need for robust defense mechanisms tailored to PEFT methods.We also explore a preliminary defense strategy based on diversified LoRA deployments, highlighting its potential to mitigate such attacks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Local feature matching remains a fundamental challenge in computer vision. Recent Area to Point Matching (A2PM) methods have improved matching accuracy. However, existing research based on this framework relies on inefficient pixel-level comparisons and complex graph matching that limit scalability. In this work, we introduce the Semantic and Geometric-aware Descriptor Network (SGAD), which fundamentally rethinks area-based matching by generating highly discriminative area descriptors that enable direct matching without complex graph optimization. This approach significantly improves both accuracy and efficiency of area matching. We further improve the performance of area matching through a novel supervision strategy that decomposes the area matching task into classification and ranking subtasks. Finally, we introduce the Hierarchical Containment Redundancy Filter (HCRF) to eliminate overlapping areas by analyzing containment graphs. SGAD demonstrates remarkable performance gains, reducing runtime by 60$\times$ (0.82s vs. 60.23s) compared to MESA. Extensive evaluations show consistent improvements across multiple point matchers: SGAD+LoFTR reduces runtime compared to DKM, while achieving higher accuracy (0.82s vs. 1.51s, 65.98 vs. 61.11) in outdoor pose estimation, and SGAD+ROMA delivers +7.39\% AUC@5$^\circ$ in indoor pose estimation, establishing a new state-of-the-art.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D segmentation. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code will be available soon.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 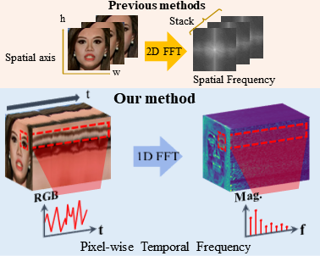
Abstract
We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. The traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect pixel-wise temporal artifacts. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
The viewing graph is a compact tool to encode the geometry of multiple views: nodes represent uncalibrated cameras and edges represent fundamental matrices (when available). Most research focuses on theoretical analyses, exploring for which viewing graphs it is possible (in principle) to retrieve cameras from fundamental matrices, in the sense that the problem admits a unique solution for noiseless data. However, the practical task of recovering cameras from noisy fundamental matrices is still open, as available methods are limited to special graphs (such as those covered by triplets). In this paper, we develop the first method that can deal with the recovery of cameras from noisy fundamental matrices in a general viewing graph. Experimental results demonstrate the promise of the proposed approach on a variety of synthetic and real scenarios.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 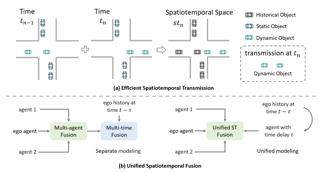
Abstract
Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Compared to image-text pair data, interleaved corpora enable Vision-Language Models (VLMs) to understand the world more naturally like humans. However, such existing datasets are crawled from webpage, facing challenges like low knowledge density, loose image-text relations, and poor logical coherence between images. On the other hand, the internet hosts vast instructional videos (e.g., online geometry courses) that are widely used by humans to learn foundational subjects, yet these valuable resources remain underexplored in VLM training. In this paper, we introduce a high-quality \textbf{multimodal textbook} corpus with richer foundational knowledge for VLM pretraining. It collects over 2.5 years of instructional videos, totaling 22,000 class hours. We first use an LLM-proposed taxonomy to systematically gather instructional videos. Then we progressively extract and refine visual (keyframes), audio (ASR), and textual knowledge (OCR) from the videos, and organize as an image-text interleaved corpus based on temporal order. Compared to its counterparts, our video-centric textbook offers more coherent context, richer knowledge, and better image-text alignment. Experiments demonstrate its superb pretraining performance, particularly in knowledge- and reasoning-intensive tasks like ScienceQA and MathVista. Moreover, VLMs pre-trained on our textbook exhibit outstanding interleaved context awareness, leveraging visual and textual cues in their few-shot context for task solving.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Fitting a body to a 3D clothed human point cloud is a common yet challenging task. Traditional optimization-based approaches use multi-stage pipelines that are sensitive to pose initialization, while recent learning-based methods often struggle with generalization across diverse poses and garment types. We propose Equivariant Tightness Fitting for Clothed Humans, or ETCH, a novel pipeline that estimates cloth-to-body surface mapping through locally approximate SE(3) equivariance, encoding tightness as displacement vectors from the cloth surface to the underlying body. Following this mapping, pose-invariant body features regress sparse body markers, simplifying clothed human fitting into an inner-body marker fitting task. Extensive experiments on CAPE and 4D-Dress show that ETCH significantly outperforms state-of-the-art methods -- both tightness-agnostic and tightness-aware -- in body fitting accuracy on loose clothing (16.7% ~ 69.5%) and shape accuracy (average 49.9%). It also reduces directional errors by (67.2% ~ 89.8%) in few-shot settings (<1% data). Qualitative results demonstrate strong performance regardless of body shape, loose clothing, or challenging poses. We will release the code and models for research purposes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Prior work has analyzed the robustness of deep models to image transformations and corruptions, particularly in cases where such alterations are not seen during training. When this occurs, they introduce a form of distribution shift at test time, often leading to performance degradation. The primary focus has been on severe corruptions that, when applied aggressively, distort useful signals necessary for accurate semantic predictions.We take a different perspective by analyzing parameters of the image acquisition process and transformations that may be subtle or even imperceptible to the human eye. We find that such parameters are systematically encoded in the learned visual representations and can be easily recovered. More strikingly, their presence can have a profound impact—either positively or negatively—on semantic predictions. This effect depends on whether there is a strong correlation or anti-correlation between semantic labels and these acquisition-based or processing-based labels.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper introduces UnZipLoRA, a method for decomposing an image into its constituent subject and style, represented as two distinct LoRAs (Low-Rank Adaptations). Unlike existing personalization techniques that focus on either subject or style in isolation, or require separate training sets for each, UnZipLoRA disentangles these elements from a single image by training both the LoRAs simultaneously. UnZipLoRA ensures that the resulting LoRAs are compatible, i.e., they can be seamlessly combined using direct addition. UnZipLoRA enables independent manipulation and recontextualization of subject and style, including generating variations of each, applying the extracted style to new subjects, and recombining them to reconstruct the original image or create novel variations. To address the challenge of subject and style entanglement, UnZipLoRA employs a novel prompt separation technique, as well as column and block separation strategies to accurately preserve the characteristics of subject and style, and ensure compatibility between the learned LoRAs. Evaluation with human studies and quantitative metrics demonstrates UnZipLoRA's effectiveness compared to other state-of-the-art methods, including DreamBooth-LoRA, Inspiration Tree, and B-LoRA.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
In this paper, we introduce Latent Bridge Matching (LBM), a new, versatile and scalable method that relies on Bridge Matching in a latent space to achieve fast image-to-image translation. We show that the method can reach state-of-the-art results for various image-to-image tasks using only a single inference step. In addition to its efficiency, we also demonstrate the versatility of the method across different image translation tasks such as object removal, normal and depth estimation, and object relighting. We also derive a conditional framework of LBM and demonstrate its effectiveness by tackling the tasks of controllable image relighting and shadow generation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 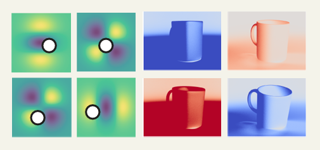
Abstract
We derive methods to compute higher order differentials (Hessians and Hessian-vector products) of the rendering operator. Our approach is based on importance sampling of a convolution that represents the differentials of rendering parameters and shows to be applicable to both rasterization and path tracing. We demonstrate that this information improves convergence when used in higher-order optimizers such as Newton or Conjugate Gradient relative to a gradient descent baseline in several inverse rendering tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. We will make the dataset publicly available for research purpose.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators.Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications.To circumvent this inherent drawback, we propose **Adversarial Distribution Matching (ADM)**, a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner.In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces.Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage.By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed **DMDX**, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time.Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 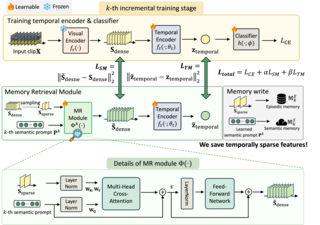
Abstract
In this work, we tackle the problem of video class-incremental learning (VCIL). Many existing VCIL methods mitigate catastrophic forgetting by rehearsal training with a few temporally dense samples stored in episodic memory, which is memory-inefficient. Alternatively, some methods store temporally sparse samples, sacrificing essential temporal information and thereby resulting in inferior performance.To address this trade-off between memory-efficiency and performance, we propose EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning (ESSENTIAL).We are inspired by the human memory system, which integrates episodic and semantic memory for accurate information retrieval.ESSENTIAL consists of episodic memory for storing temporally sparse features and semantic memory for storing general knowledge represented by learnable prompts.We introduce a novel memory retrieval (MR) module that integrates episodic and semantic memory through cross-attention, enabling the retrieval of temporally dense features from temporally sparse features.We rigorously validate ESSENTIAL on diverse datasets: UCF-101, HMDB51, and Something-Something-V2 from the TCD benchmark and UCF-101, ActivityNet, and Kinetics-400 from the vCLIMB benchmark.Remarkably, with significantly reduced memory, ESSENTIAL achieves favorable performance on the benchmarks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper explains training-time out-of-distribution (OOD) detection from a novel view, i.e., interactions between different input variables of deep neural networks (DNNs). Specifically, we provide a unified understanding of the effectiveness of current training-time OOD detection methods, i.e., DNNs trained with these methods all encode more complex interactions for inference than those trained without training-time methods, which contributes to their superior OOD detection performance. We further conduct thorough empirical analyses and verify that complex interactions play a primary role in OOD detection, by developing a simple-yet-efficient method to force the DNN to learn interactions of specific complexities and evaluate the change of OOD detection performances. Besides, we also use interactions to investigate why near-OOD samples are more difficult to distinguish from in-distribution (ID) samples than far-OOD samples, mainly because compared to far-OOD samples, the distribution of interactions in near-OOD samples is more similar to that of ID samples. Moreover, we discover that training-time OOD detection methods can effectively decrease such similarities. The code will be released when the paper is accepted.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Although 3D Gaussian Splatting (3DGS) has revolutionized 3D reconstruction, it still faces challenges such as aliasing, projection artifacts, and view inconsistencies, primarily due to the simplification of treating splats as 2D entities. We argue that incorporating full 3D evaluation of Gaussians throughout the 3DGS pipeline can effectively address these issues while preserving rasterization efficiency. Specifically, we introduce an adaptive 3D smoothing filter to mitigate aliasing and present a stable view-space bounding method that eliminates popping artifacts when Gaussians extend beyond the view frustum. Furthermore, we promote tile-based culling to 3D with screen-space planes, accelerating rendering and reducing sorting costs for hierarchical rasterization. Our method achieves state-of-the-art quality on in-distribution evaluation sets and significantly outperforms other approaches for out-of-distribution views. Our qualitative evaluations further demonstrate the effective removal of aliasing, distortions, and popping artifacts, ensuring real-time, artifact-free rendering.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Human perceptual systems excel at inducing and recognizing objects across both known and novel categories, a capability far beyond current machine learning frameworks. While generalized category discovery (GCD) aims to bridge this gap, existing methods predominantly focus on optimizing objective functions. We present an orthogonal solution, inspired by the human cognitive process for novel object understanding: decomposing objects into visual primitives and establishing cross-knowledge comparisons. We propose ConGCD, which establishes primitive-oriented representations through high-level semantic reconstruction, binding intra-class shared attributes via deconstruction. Mirroring human preference diversity in visual processing, where distinct individuals leverage dominant or contextual cues, we implement dominant and contextual consensus units to capture class-discriminative patterns and inherent distributional invariants, respectively. A consensus scheduler dynamically optimizes activation pathways, with final predictions emerging through multiplex consensus integration. Extensive evaluations across coarse- and fine-grained benchmarks demonstrate ConGCD's effectiveness as a consensus-aware paradigm.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper investigates the problem of understanding dynamic 3D scenes from egocentric observations, a key challenge in robotics and embodied AI. Unlike prior studies that explored this as long-form video understanding and utilized egocentric video only, we instead propose an LLM-based agent, Embodied VideoAgent, which constructs scene memory from both egocentric video and embodied sensory inputs (e.g. depth and pose sensing). We further introduce a VLM-based approach to automatically update the memory when actions or activities over objects are perceived. Embodied VideoAgent attains significant advantages over counterparts in challenging reasoning and planning tasks in 3D scenes, achieving gains of 6.5% on Ego4D-VQ3D, 2.6% on OpenEQA, and 15.3% on EnvQA. We have also demonstrated its potential in various embodied AI tasks including generating embodied interactions and perception for robot manipulation. The code and demo will be made public.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 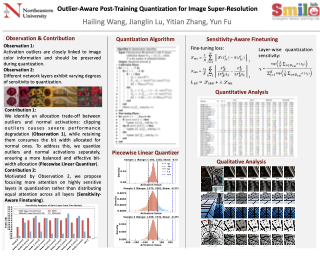
Abstract
Quantization techniques, including quantization-aware training (QAT) and post-training quantization (PTQ), have become essential for inference acceleration of image super-resolution (SR) networks. Compared to QAT, PTQ has garnered significant attention as it eliminates the need for ground truth and model retraining. However, existing PTQ methods for SR often fail to achieve satisfactory performance as they overlook the impact of outliers in activation. Our empirical analysis reveals that these prevalent activation outliers are strongly correlated with image color information, and directly removing them leads to significant performance degradation. Motivated by this, we propose a dual-region quantization strategy that partitions activations into an outlier region and a dense region, applying uniform quantization to each region independently to better balance bit-width allocation. Furthermore, we observe that different network layers exhibit varying sensitivities to quantization, leading to different levels of performance degradation. To address this, we introduce sensitivity-aware finetuning that encourages the model to focus more on highly sensitive layers, further enhancing quantization performance. Extensive experiments demonstrate that our method outperforms existing PTQ approaches across various SR networks and datasets, while achieving performance comparable to QAT methods in most scenarios with at least a 75 $\times$ speedup.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
The commercialization of generative artificial intelligence (GenAI) has led to a multi-level ecosystem involving model developers, service providers, and consumers. Thus, ensuring traceability is crucial, as service providers may violate intellectual property rights (IPR), and consumers may generate harmful content. However, existing methods are limited to single-level attribution scenarios and cannot simultaneously trace across multiple levels. To this end, we introduce a scalable dual fingerprinting method for text-to-image (T2I) models, to achieve traceability of both service providers and consumers. Specifically, we propose 2-headed Fingerprint-Informed Low-Rank Adaptation (FI-LoRA), where each head is controlled by a binary fingerprint and capable of introducing the fingerprints into generated images. In practice, one FI-LoRA head is used by the developer to assign a unique fingerprint to each service provider, while the other is made available to service providers for embedding consumer-specific fingerprints during image generation. Our method does not merely embed two fingerprints within the generated image but instead allows independent control over them at developer level and business level, enabling simultaneous traceability of businesses and consumers. Experiments show that our method applies to various image generation and editing tasks of multiple T2I models, and can achieve over 99.9\% extraction accuracy for both fingerprints. Our …
|
|
Highlight
|
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Poster
[ Exhibit Hall I ] Abstract
Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 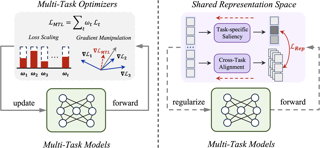
Abstract
Despite the promise of Multi-Task Learning (MTL) in leveraging complementary knowledge across tasks, existing multi-task optimization (MTO) techniques remain fixated on resolving conflicts through optimizer-centric loss scaling and gradient manipulation, yet fail to deliver consistent gains. In this paper, we argue that the shared representation space, where task interactions naturally occur, offers rich information and potential for operations complementary to existing optimizer designs, especially for facilitating the inter-task complementarity, which is rarely explored in MTO. This intuition leads to Rep-MTL, which exploits the representation-level task saliency to quantify interactions between task-specific optimization and shared representation learning. By steering these saliencies through entropybased penalization and sample-wise cross-task alignment, Rep-MTL aims to mitigate negative transfer by maintaining the effective training of individual tasks instead pure conflict-solving, while explicitly promoting complementary information sharing. Experiments are conducted on four challenging MTL benchmarks covering both task-shift and domain-shift scenarios. The results show that Rep-MTL, even paired with the basic equal weighting (EW) policy, achieves competitive performance gains with favorable efficiency. Beyond standard performance metrics, Power Law (PL) exponent analysis demonstrates Rep-MTL’s efficacy in balancing task-specific learning and cross-task sharing.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 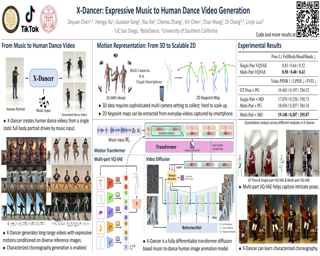
Abstract
We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Panoramic optical flow enables a comprehensive understanding of temporal dynamics across wide fields of view. However, severe distortions caused by sphere-to-plane projections, such as the equirectangular projection (ERP), significantly degrade the performance of conventional perspective-based optical flow methods, especially in polar regions. To address this challenge, we propose PriOr-Flow, a novel dual-branch framework that leverages the low-distortion nature of the orthogonal view to enhance optical flow estimation in these regions. Specifically, we introduce the Dual-Cost Collaborative Lookup (DCCL) operator, which jointly retrieves correlation information from both the primitive and orthogonal cost volumes, effectively mitigating distortion noise during cost volume construction. Furthermore, our Ortho-Driven Distortion Compensation (ODDC) module iteratively refines motion features from both branches, further suppressing polar distortions. Extensive experiments demonstrate that PriOr-Flow is compatible with various perspective-based iterative optical flow methods and consistently achieves state-of-the-art performance on publicly available panoramic optical flow datasets, setting a new benchmark for wide-field motion estimation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Under Display Camera (UDC) is an advanced imaging system that places a digital camera lens underneath a display panel, effectively concealing the camera. However, the display panel significantly degrades captured images or videos, introducing low transmittance, blur, noise, and flare issues. Tackling such issues is challenging because of the complex degradation of UDCs, including diverse flare patterns. Despite extensive research on UDC images and their restoration models, studies on videos have yet to be significantly explored. While two UDC video datasets exist, they primarily focus on unrealistic or synthetic UDC degradation rather than real-world UDC degradation. In this paper, we propose a real-world UDC video dataset called UDC-VIX. Unlike existing datasets, only UDC-VIX exclusively includes human motions that target facial recognition. We propose a video-capturing system to simultaneously acquire non-degraded and UDC-degraded videos of the same scene. Then, we align a pair of captured videos frame by frame, using discrete Fourier transform (DFT). We compare UDC-VIX with six representative UDC still image datasets and two existing UDC video datasets. Using six deep-learning models, we compare UDC-VIX and an existing synthetic UDC video dataset. The results indicate the ineffectiveness of models trained on earlier synthetic UDC video datasets, as they do …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
What cannot be measured cannot be improved while likely never uttered by Lord Kelvin, summarizes effectively the purpose of this work. This paper presents a detailed evaluation of automated metrics for evaluating structured 3D reconstructions. Pitfalls of each metric are discussed, and a thorough analyses through the lens of expert 3D modelers' preferences is presented. A set of systematic "unit tests" are proposed to empirically verify desirable properties, and context aware recommendations as to which metric to use depending on application are provided. Finally, a learned metric distilled from human expert judgments is proposed and analyzed.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 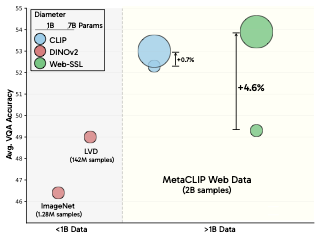
Abstract
Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is often attributed to the semantics introduced by language supervision, even though visual SSL and CLIP models are often trained on different data. In this work, we ask the question: "Do visual self-supervised approaches lag behind CLIP due to the lack of language supervision, or differences in the training data?" We study this question by training both visual SSL and CLIP models on the same MetaCLIP data, and leveraging VQA as a diverse testbed for vision encoders. In this controlled setup, visual SSL models scale better than CLIP models in terms of data and model capacity, and visual SSL performance does not saturate even after scaling up to 7B parameters. Consequently, we observe visual SSL methods achieve CLIP-level performance on a wide range of VQA and classic vision benchmarks. These findings demonstrate that pure visual SSL can match language-supervised visual pretraining at scale, opening new opportunities for vision-centric representation learning.
|
|
Highlight
|
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Poster
[ Exhibit Hall I ] 
Abstract
We present a self-supervised method to improve an agent's abilities in describing arbitrary objectswhile actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism.First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set.Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations will be released upon paper acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 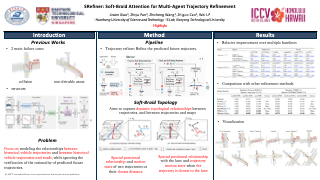
Abstract
Accurate prediction of multi-agent future trajectories is crucial for autonomous driving systems to make safe and efficient decisions. Trajectory refinement has emerged as a key strategy to enhance prediction accuracy. However, existing refinement methods often overlook the topological relationships between trajectories, which are vital for improving prediction precision. Inspired by braid theory, we propose a novel trajectory refinement approach, Soft-Braid Refiner (SRefiner), guided by the soft-braid topological structure of trajectories using Soft-Braid Attention. Soft-Braid Attention captures spatio-temporal topological relationships between trajectories by considering both spatial proximity and vehicle motion states at ``soft intersection points". Additionally, we extend this approach to model interactions between trajectories and lanes, further improving the prediction accuracy. SRefiner is a multi-iteration, multi-agent framework that iteratively refines trajectories, incorporating topological information to enhance interactions within traffic scenarios. SRefiner achieves significant performance improvements over four baseline methods across two datasets, establishing a new state-of-the-art in trajectory refinement.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Given an object mask, Semi-supervised Video Object Segmentation (SVOS) technique aims to track and segment the object across video frames, serving as a fundamental task in computer vision. Although recent memory-based methods demonstrate potential, they often struggle with scenes involving occlusion, particularly in handling object interactions and high feature similarity. To address these issues and meet the real-time processing requirements of downstream applications, in this paper, we propose a novel bOundary Amendment video object Segmentation method with Inherent Structure refinement, hereby named OASIS. Specifically, a lightweight structure refinement module is proposed to enhance segmentation accuracy. With the fusion of rough edge priors captured by the Canny filter and stored object features, the module can generate an object-level structure map and refine the representations by highlighting boundary features. Evidential learning for uncertainty estimation is introduced to further address challenges in occluded regions. The proposed method, OASIS, maintains an efficient design, yet extensive experiments on challenging benchmarks demonstrate its superior performance and competitive inference speed compared to other state-of-the-art methods, i.e., achieving the F values of 91.6 (vs. 89.7 on DAVIS-17 validation set) and G values of 86.6 (vs. 86.2 on YouTubeVOS 2019 validation set) while maintaining a competitive speed of 48 …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Most existing remote sensing instance segmentation approaches are designed for close-vocabulary prediction, limiting their ability to recognize novel categories or generalize across datasets. This restricts their applicability in diverse Earth observation scenarios. To address this, we introduce open-vocabulary (OV) learning for remote sensing instance segmentation. While current OV segmentation models perform well on natural image datasets, their direct application to remote sensing faces challenges such as diverse landscapes, seasonal variations, and the presence of small or ambiguous objects in aerial imagery. To overcome these challenges, we propose SCORE (Scene Context matters in Open-vocabulary REmote sensing instance segmentation), a framework that integrates multi-granularity scene context, i.e., regional context and global context, to enhance both visual and textual representations. Specifically, we introduce Region-Aware Integration, which refines class embeddings with regional context to improve object distinguishability. Additionally, we propose Global Context Adaptation, which enriches naive text embeddings with remote sensing global context, creating a more adaptable and expressive linguistic latent space for the classifier. We establish new benchmarks for OV remote sensing instance segmentation across diverse datasets. Experimental results demonstrate that, our proposed method achieves SOTA performance, which provides a robust solution for large-scale, real-world geospatial analysis.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task?This question of model selection is traditionally answered by collecting and annotating a validation dataset---a costly and time-intensive process.We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected.We validate our approach by curating a collection of 25 benchmark tasks capturing a range of model selection scenarios.CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 50% compared to the previous state-of-the-art. We will make our code and data public.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We introduce a taxonomy of solid materials for hierarchical material recognition from local appearance. Our taxonomy is motivated by vision applications, and is arranged according to the physical traits of materials. We contribute a diverse dataset of images and aligned depth maps of materials in the wild. The depth maps can be used to generate novel views to augment the dataset. Utilizing the taxonomy and dataset, we present a learning-based approach to hierarchical material recognition that uses graph neural networks. Our model leverages taxonomic proximity between material classes, and achieves state-of-the-art performance. We show that our model has the potential to generalize in few-shot learning settings. As a result, it achieves coarse classification of underrepresented materials.
|
|
Highlight
|
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Poster
[ Exhibit Hall I ] 
Abstract
Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We present OminiControl, a novel approach that rethinks how image conditions are integrated into Diffusion Transformer (DiT) architectures. Current image conditioning methods either introduce substantial parameter overhead or handle only specific control tasks effectively, limiting their practical versatility. OminiControl addresses these limitations through three key innovations: (1) a minimal architectural design that leverages the DiT's own VAE encoder and transformer blocks, requiring just 0.1\% additional parameters; (2) a unified sequence processing strategy that combines condition tokens with image tokens for flexible token interactions; and (3) a dynamic position encoding mechanism that adapts to both spatially-aligned and non-aligned control tasks. Our extensive experiments show that this streamlined approach not only matches but surpasses the performance of specialized methods across multiple conditioning tasks. To overcome data limitations in subject-driven generation, we also introduce Subjects200K, a large-scale dataset of identity-consistent image pairs synthesized using DiT models themselves. This work demonstrates that effective image control can be achieved without architectural complexity, opening new possibilities for efficient and versatile image generation systems.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper introduces a tuning-free method for both object insertion and subject-driven generation. The task involves composing an object, given multiple views, into a scene specified by either an image or text. Existing methods struggle to fully meet the task's challenging objectives: (i) seamlessly composing the object into the scene with photorealistic pose and lighting, and (ii) preserving the object's identity. We hypothesize that achieving these goals requires large scale supervision, but manually collecting sufficient data is simply too expensive. The key observation in this paper is that many mass-produced objects recur across multiple images of large unlabeled datasets, in different scenes, poses, and lighting conditions. We use this observation to create massive supervision by retrieving sets of diverse views of the same object. This powerful paired dataset enables us to train a straightforward text-to-image diffusion architecture to map the object and scene descriptions to the composited image. We compare our method, ObjectMate, with state-of-the-art methods for object insertion and subject-driven generation, using a single or multiple references. Empirically, ObjectMate achieves superior identity preservation and more photorealistic composition. Differently from many other multi-reference methods, ObjectMate does not require slow test-time tuning.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Understanding real-world 3D point clouds is challenging due to domain shifts, causing geometric variations like density changes, noise, and occlusions. The key challenge is disentangling domain-invariant semantics from domain-specific geometric variations, as point clouds exhibit local inconsistency and global redundancy, making direct alignment ineffective. To address this, we propose CounterPC, a counterfactual intervention-based domain adaptation framework, which formulates domain adaptation within a causal latent space, identifying category-discriminative features entangled with intra-class geometric variation confounders. Through counterfactual interventions, we generate counterfactual target samples that retain domain-specific characteristics while improving class separation, mitigating domain bias for optimal feature transfer. To achieve this, we introduce two key modules: i) Joint Distribution Alignment, which leverages 3D foundation models (3D-FMs) and a self-supervised autoregressive generative prediction task to unify feature alignment, and ii) Counterfactual Feature Realignment, which employs Optimal Transport (OT) to align category-relevant and category-irrelevant feature distributions, ensuring robust sample-level adaptation while preserving domain and category properties. CounterPC outperforms state-of-the-art methods on PointDA and GraspNetPC-10, achieving accuracy improvements of 4.7 and 3.6, respectively. Code and pre-trained weights will be publicly released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 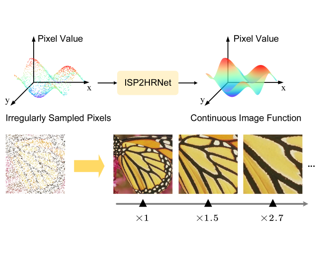
Abstract
While image signals are typically defined on a regular 2D grid, there are scenarios where they are only available at irregular positions. In such cases, reconstructing a complete image on regular grid is essential. This paper introduces ISP2HRNet, an end-to-end network designed to reconstruct high resolution image from irregularly sampled pixels that do not fall on a regular grid. To handle the challenges brought by irregular sampling, we propose an architecture to extract gradient structure hierarchically and learn continuous image representation. Specifically, we derive image gradient for each irregularly sampled pixel and further learn higher order gradient structural features according to the geometric and photometric information at the vertices of neighboring triangles. To convert the features from irregular pixels to regular grid, we propose a dual branch content-dependent weight generator to adaptively fuse the information from neighboring irregular pixels. Subsequently, an encoder captures deep structural details on regular grid and forms latent codes. Implicit neural representation parameterized by multi-layer perceptron decodes the latent codes and coordinates to pixel values for generating high resolution image. Experimental results demonstrate that the proposed network can effectively solve the problem of high resolution image reconstruction from irregularly sampled pixels and achieve promising results. The …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 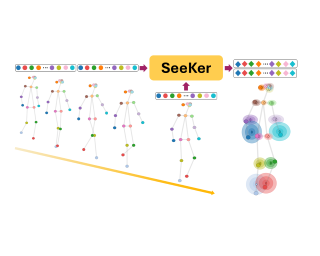
Abstract
Detecting anomalous human behaviouris an important visual taskin safety-critical applicationssuch as healthcare monitoring,workplace safety,or public surveillance.In these contexts,abnormalities are often reflectedwith unusual human poses.Thus, we propose SeeKer,a method for detecting anomaliesin sequences of human skeletons.Our method formulates the skeleton sequence densitythrough autoregressive factorization at the keypoint level.The corresponding conditional distributionsrepresent probable keypoint locations given prior skeletal motion.We formulate the joint distribution of the considered skeletonas causal prediction of conditional Gaussiansacross its constituent keypoints.A skeleton is flagged as anomalous if its keypoint locations surprise our model(i.e. receive a low density).In practice, our anomaly score is a weighted sum of per-keypoint log-conditionals,where the weights account for the confidence of the underlying keypoint detector.Despite its conceptual simplicity,SeeKer surpasses all previous methodson the UBnormal and MSAD-HR datasetswhile delivering competitive performanceon the ShanghaiTech dataset.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Obtaining high-quality 3D semantic occupancy from raw sensor data remains an essential yet challenging task, often requiring extensive manual labeling. In this work, we propose AutoOcc, an vision-centric automated pipeline for open-ended semantic occupancy annotation that integrates differentiable Gaussian splatting guided by vision-language models. We formulate the open-ended semantic occupancy reconstruction task to automatically generate scene occupancy by combining attention maps from vision-language models and foundation vision models. We devise semantic-aware Gaussians as intermediate geometric descriptors and propose a cumulative Gaussian-to-voxel splatting algorithm that enables effective and efficient occupancy annotation. Our framework outperforms existing automated occupancy annotation methods without human labels. AutoOcc also enables open-ended semantic occupancy auto-labeling, achieving robust performance in both static and dynamically complex scenarios. All the source codes and trained models will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Knowledge Distillation (KD) has been established as an effective technique for reducing the resource requirements of models when tackling computer vision tasks. Prior work has studied how to distill the knowledge of a teacher model better, but it overlooks how data affects the distillation result. This work examines the impact of data in knowledge distillation from two perspectives: (i) quantity of knowledge and (ii) quality of knowledge. Our examination finds that faster knowledge distillation can be achieved by using data with a large amount of high-quality knowledge in distillation. Based on the findings, this work proposes an efficient adaptive sampling method called KDAS for faster knowledge distillation, which enhances the distillation efficiency by selecting and applying 'good' samples for the distillation. This work shows that our adaptive sampling methods can effectively accelerate the training efficiency of a student model when combined with existing KD methods.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 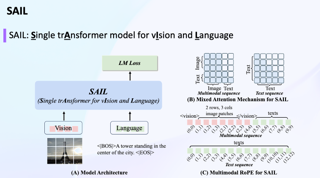
Abstract
This paper introduces SAIL, a single transformer unified multimodal large language model (MLLM) that integrates raw pixel encoding and language decoding within a singular architecture. Unlike existing modular MLLMs, which rely on a pre-trained vision transformer (ViT), SAIL eliminates the need for a separate vision encoder, presenting a more minimalist architecture design. Instead of introducing novel architectural components, SAIL adapts mix-attention mechanisms and multimodal positional encodings to better align with the distinct characteristics of visual and textual modalities. We systematically compare SAIL's properties-including scalability, cross-modal information flow patterns, and visual representation capabilities-with those of modular MLLMs. By scaling both training data and model size, SAIL achieves performance comparable to modular MLLMs. Notably, the removal of pretrained ViT components enhances SAIL's scalability and results in significantly different cross-modal information flow patterns. Moreover, SAIL demonstrates strong visual representation capabilities, achieving results on par with ViT-22B in vision tasks such as semantic segmentation. Code and models will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We introduce CoTracker3, a new state-of-the-art point tracker. With CoTracker3, we revisit the design of recent trackers, removing components and reducing the number of parameters while also improving performance. We also explore the interplay of synthetic and real data. Recent trackers are trained on synthetic videos due to the difficulty of collecting tracking annotations for real data. However, this can result in suboptimal performance due to the statistical gap between synthetic and real videos. We thus suggest using off-the-shelf trackers as teachers, annotating real videos with pseudo-labels. Compared to other recent attempts at using real data for learning trackers, this scheme is much simpler and achieves better results using 1,000 times less data. CoTracker3 is available in online (causal) and offline variants and is particularly robust to occlusions.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the **Attribute (Att) Adapter**, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning.We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world.Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 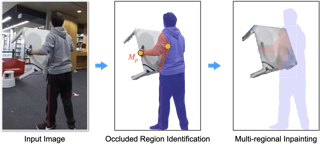
Abstract
Amodal completion, the task of inferring the complete appearance of objects despite partial occlusions, is crucial for understanding complex human–object interactions (HOI) in computer vision and robotics. Existing methods, including pre-trained diffusion models, often struggle to generate plausible completions in dynamic scenarios due to their limited understanding of HOI. To address this challenge, we propose a novel approach that leverages physical prior knowledge alongside a specialized multi-regional inpainting technique tailored for HOI. By incorporating physical constraints derived from human topology and contact information, we define two distinct regions: the primary region, where occluded object parts are most likely to reside, and the secondary region, where occlusions are less probable. Our multi-regional inpainting method employs customized denoising strategies across these regions within a diffusion model, thereby enhancing the accuracy and realism of generated completions in both shape and visual detail. Experimental results demonstrate that our approach substantially outperforms existing methods in HOI scenarios, advancing machine perception toward a more human-like understanding of dynamic environments. Furthermore, we show that our pipeline remains robust even without ground-truth contact annotations, broadening its applicability to tasks such as 3D reconstruction and novel view/pose synthesis. Code will be made publicly available upon acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The use of CLIP embeddings to assess the alignment of samples produced by text-to-image generative models has been extensively explored in the literature. While the widely adopted CLIPScore, derived from the cosine similarity of text and image embeddings, effectively measures the relevance of a generated image, it does not quantify the diversity of images generated by a text-to-image model. In this work, we extend the application of CLIP embeddings to quantify and interpret the intrinsic diversity of text-to-image models, which is responsible for generating diverse images from similar text prompts. To achieve this, we propose a decomposition of the CLIP-based kernel covariance matrix of image data into text-based and non-text-based components. Using the Schur complement of the joint image-text kernel covariance matrix, we perform this decomposition and define the matrix-based entropy of the decomposed component as the *Schur Complement Entropy (SCE)* score, a measure of the intrinsic diversity of a text-to-image model based on data collected with varying text prompts. Additionally, we demonstrate the use of the Schur complement-based decomposition to nullify the influence of a given prompt in the CLIP embedding of an image, enabling focus or defocus of embeddings on specific objects or properties for downstream tasks. We …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 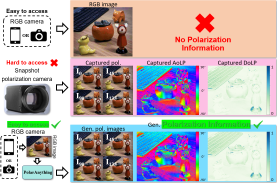
Abstract
Polarization images facilitate image enhancement and 3D reconstruction tasks, but the limited accessibility of polarization cameras hinders their broader application. This gap drives the need for synthesizing photorealistic polarization images. The existing polarization simulator Mitsuba relies on a parametric polarization image formation model and requires extensive 3D assets covering shape and PBR materials, preventing it from generating large-scale photorealistic images. To address this problem, we propose PolarAnything, capable of synthesizing polarization images from a single RGB input with both photorealism and physical accuracy, eliminating the dependency on 3D asset collections. Drawing inspiration from the zero-shot performance of pretrained diffusion models, we introduce a diffusion-based generative framework with an effective representation strategy that preserves the fidelity of polarization properties. Extensive experiments show that our model not only generates high-quality polarization images but also effectively supports downstream tasks such as shape from polarization.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We propose Long-LRM, a feed-forward 3D Gaussian reconstruction model for instant, high-resolution, 360$^\circ$ wide-coverage, scene-level reconstruction. Specifically, it takes in 32 input images at a resolution of $960\times 540$ and produces the Gaussian reconstruction in just 1 second on a single A100 GPU. To handle the long sequence of **250K** tokens brought by the large input size, Long-LRM features a mixture of the recent Mamba2 blocks and the classical transformer blocks, enhanced by a light-weight token merging module and Gaussian pruning steps that balance between quality and efficiency. We evaluate Long-LRM on the large-scale DL3DV benchmark and Tanks&Temples, demonstrating reconstruction quality comparable to the optimization-based methods while achieving an **800**$\times$ speedup w.r.t. the optimization-based approaches and an input size at least **60**$\times$ larger than the previous feed-forward approaches. We conduct extensive ablation studies on our model design choices for both rendering quality and computation efficiency. We also explore Long-LRM's compatibility with other Gaussian variants such as 2D GS, which enhances Long-LRM's ability in geometry reconstruction. Project page: https://longgggglrm.github.io
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Human motion is inherently continuous and dynamic, posing significant challenges for generative models. While discrete generation methods are widely used, they suffer from limited expressiveness and frame-wise noise artifacts. In contrast, continuous approaches produce smoother, more natural motion but often struggle to adhere to conditioning signals due to high-dimensional complexity and limited training data. To resolve this discord between discrete and continuous representations we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that leverages rectified flow to decode discrete motion tokens in the continuous, raw motion space. Our core idea is to frame token decoding as a conditional generation task, ensuring that DisCoRD captures fine-grained dynamics and achieves smoother, more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals on diverse settings. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results establish DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Code and checkpoints will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 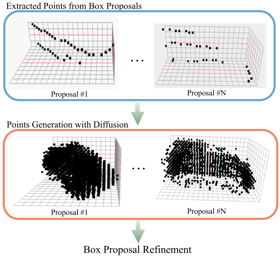
Abstract
The robustness of 3D object detection in large-scale outdoor point clouds degrades significantly when deployed in an unseen environment due to domain shifts. To minimize the domain gap, existing works on domain adaptive detection focuses on several factors, including point density, object shape and sizes, to reduce the false negative detections. However, the adaptation results indicate that there are still remaining challenges. We argue that this is due to the challenge in recognizing comparably less distinctive region on object surface due to sparsity, occlusion, etc. In this work, we aim to reinforce those features by generating points on object surface to make them straightforwardly recognizable. We draw our motivation from a common observation that detection proposals already contain the accurate bounding boxes, but with relatively low objectness score predictions, which lead to false negatives. Given these box proposals, we densify sparse object points with a diffusion approach. As a result, our model DiffRefine can act as a simple additional module before second-stage refinement, where most existing detection models for two-stage detection can use. Experimental results on domain adaptive detection show competitive performance, especially on vanishing points due to distance on various detection architectures.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Diffusion-based generative models have demonstrated exceptional promise in super-resolution (SR) tasks, achieving a substantial advancement in detail generation relative to prior methods. However, these approaches face significant computational efficiency challenges. When the input is video, the problem becomes even more pronounced. For instance, current techniques may require tens of minutes to super-resolve a mere 2-second, 1080p video. In this paper, we present TurboVSR, an ultra-efficient diffusion-based video super-resolution model. Our core design comprises three key aspects: **(1)** We employ an autoencoder with a high compression ratio of 32$\times$32$\times$8 to reduce the number of tokens. **(2)** Highly compressed latents pose substantial challenges for training. We introduce factorized conditioning to mitigate the learning complexity: we first learn to super-resolve the initial frame; subsequently, we condition the super-resolution of the remaining frames on the high-resolution initial frame and the low-resolution subsequent frames. **(3)** We convert the pre-trained diffusion model to a shortcut model to enable fewer sampling steps, further accelerating inference.As a result, TurboVSR performs on par with state-of-the-art VSR methods, while being 100+ times faster, taking only 7 seconds to process a 2-second long 1080p video. TurboVSR also supports image resolution by considering image as a one-frame video. Our efficient design makes …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Dataset distillation (DD) condenses large datasets into compact yet informative substitutes, preserving performance comparable to the original dataset while reducing storage, transmission costs, and computational consumption. However, previous DD methods mainly focus on distilling information from images, often overlooking the semantic information inherent in the data. The disregard for context hinders the model's generalization ability, particularly in tasks involving complex datasets, which may result in illogical outputs or the omission of critical objects. In this study, we integrate vision-language methods into DD by introducing text prototypes to distill language information and collaboratively synthesize data with image prototypes, thereby enhancing dataset distillation performance. Notably, the text prototypes utilized in this study are derived from descriptive text information generated by an open-source large language model. This framework demonstrates broad applicability across datasets without pre-existing text descriptions, expanding the potential of dataset distillation beyond traditional image-based approaches. Compared to other methods, the proposed approach generates logically coherent images containing target objects, achieving state-of-the-art validation performance and demonstrating robust generalization. Source code and generated data are available in https://anonymous.4open.science/r/10575/.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
While image conditional diffusion models demonstrate impressive generation capabilities, they exhibit high vulnerability when facing backdoor and adversarial attacks. In this paper, we define a scenario named diffusion anomaly where generated results of a reverse process under attack deviate significantly from the normal ones. By analyzing the underlying formation mechanism of the diffusion anomaly, we reveal how perturbations are amplified during the reverse process and accumulated in the results. Based on the analysis, we reveal the phenomena of divergence and homogeneity, which cause the diffusion process to deviate significantly from the normal process and to decline in diversity. Leveraging these two phenomena, we propose a method named Diffusion Anomaly Detection (DADet) to effectively detect both backdoor and adversarial attacks. Extensive experiments demonstrate that our proposal achieves excellent defense performance against backdoor and adversarial attacks. Specifically, for the backdoor attack detection, our method achieves an F1 score of 99\% on different datasets including MS COCO and CIFAR-10. For the detection of adversarial samples, the F1 score exceeds 84\% across three adversarial attacks and two different tasks, evaluated on the MS COCO and Places365 datasets respectively.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent studies in extreme image compression have achieved remarkable performance by compressing the tokens from generative tokenizers. However, these methods often prioritize clustering common semantics within the dataset, while overlooking the diverse details of individual objects. Consequently, this results in suboptimal reconstruction fidelity, especially at low bitrates. To address this issue, we introduce a Dual-generative Latent Fusion (DLF) paradigm. DLF decomposes the latent into semantic and detail elements, compressing them through two distinct branches. The semantic branch clusters high-level information into compact tokens, while the detail branch encodes perceptually critical details to enhance the overall fidelity. Additionally, we propose a cross-branch interactive design to reduce redundancy between the two branches, thereby minimizing the overall bit cost. Experimental results demonstrate the impressive reconstruction quality of DLF even below 0.01 bits per pixel (bpp). On the CLIC2020 test set, our method achieves bitrate savings of up to 27.93% on LPIPS and 53.55% on DISTS compared to MS-ILLM. Furthermore, DLF surpasses recent diffusion-based codecs in visual fidelity while maintaining a comparable level of generative realism. Code will be available later.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Segment Anything Model 2 (SAM2) has emerged as a strong base model in various pinhole imaging segmentation tasks. However, when applying it to $360^\circ$ domain, the significant field-of-view (FoV) gap between pinhole ($70^\circ \times 70^\circ$) and panoramic images ($180^\circ \times 360^\circ$) poses unique challenges. Two major concerns for this application includes 1) inevitable distortion and object deformation brought by the large FoV disparity between domains; 2) the lack of pixel-level semantic understanding that the original SAM2 cannot provide.To address these issues, we propose a novel $\textbf{OmniSAM}$ framework, which makes the $\textbf{first}$ attempt to apply SAM2 for panoramic semantic segmentation. Specifically, to bridge the first gap, OmniSAM first divides the panorama into sequences of patches. These patches are then treated as image sequences in similar manners as in video segmentation tasks. We then leverage the SAM2’s memory mechanism to extract cross-patch correspondences that embeds the cross-FoV dependencies, improving feature continuity and the prediction consistency along mask boundaries.For the second gap, OmniSAM fine-tunes the pretrained image encoder and reutilize the mask decoder for semantic prediction. An FoV-based prototypical adaptation module with dynamic pseudo label update mechanism is also introduced to facilitate the alignment of memory and backbone features, thereby improving model generalization …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
4D Gaussian Splatting (4DGS) has recently emerged as a promising technique for capturing complex dynamic 3D scenes with high fidelity. It utilizes a 4D Gaussian representation and a GPU-friendly rasterizer, enabling rapid rendering speeds. Despite its advantages, 4DGS faces significant challenges, notably the requirement of millions of 4D Gaussians, each with extensive associated attributes, leading to substantial memory and storage cost. This paper introduces a memory-efficient framework for 4DGS. We streamline the color attribute by decomposing it into a per-Gaussian direct color component with only 3 parameters and a shared lightweight alternating current color predictor. This approach eliminates the need for spherical harmonics coefficients, which typically involve up to 144 parameters in classic 4DGS, thereby creating a memory-efficient 4D Gaussian representation. Furthermore, we introduce an entropy-constrained Gaussian deformation technique that uses a deformation field to expand the action range of each Gaussian and integrates an opacity-based entropy loss to limit the number of Gaussians, thus forcing our model to use as few Gaussians as possible to fit a dynamic scene well. With simple half-precision storage and zip compression, our framework achieves a storage reduction by approximately 190$\times$ and 125$\times$ on the Technicolor and Neural 3D Video datasets, respectively, compared to …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We introduce ED-VTG, a method for fine-grained video temporal grounding utilizing multi-modal large language models. Our approach harnesses the capabilities of multimodal LLMs to jointly process text and video, in order to effectively localize natural language queries in videos through a two-stage process. Rather than being directly grounded, language queries are initially transformed into enriched sentences that incorporate missing details and cues to aid in grounding. In the second stage, these enriched queries are grounded, using a lightweight decoder, which specializes at predicting accurate boundaries conditioned on contextualized representations of the enriched queries. To mitigate noise and reduce the impact of hallucinations, our model is trained with a multiple-instance-learning objective that dynamically selects the optimal version of the query for each training sample. We demonstrate state-of-the-art results across various benchmarks in temporal video grounding and paragraph grounding settings. Experiments reveal that our method significantly outperforms all previously proposed LLM-based temporal grounding approaches and is either superior or comparable to specialized models, while maintaining a clear advantage against them in zero-shot evaluation scenarios.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 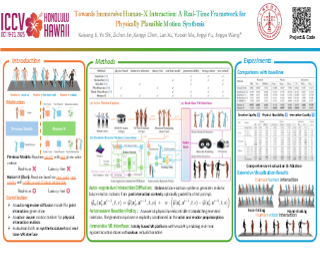
Abstract
Real-time synthesis of physically plausible human interactions remains a critical challenge for immersive VR/AR systems and humanoid robotics. While existing methods demonstrate progress in kinematic motion generation, they often fail to address the fundamental tension between real-time responsiveness, physical feasibility, and safety requirements in dynamic human-machine interactions. We introduce Human-X, a novel framework designed to enable immersive and physically plausible human interactions across diverse entities, including human-avatar, human-humanoid, and human-robot systems. Unlike existing approaches that focus on post-hoc alignment or simplified physics, our method jointly predicts actions and reactions in real-time using an auto-regressive reaction diffusion planner, ensuring seamless synchronization and context-aware responses. To enhance physical realism and safety, we integrate an actor-aware motion tracking policy trained with reinforcement learning, which dynamically adapts to interaction partners’ movements while avoiding artifacts like foot sliding and penetration. Extensive experiments on the Inter-X and InterHuman datasets demonstrate significant improvements in motion quality, interaction continuity, and physical plausibility over state-of-the-art methods. Our framework is validated in real-world applications, including virtual reality interface for human-robot interaction, showcasing its potential for advancing human-robot collaboration.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We describe a simple method for cross-architecture knowledge distillation, where the knowledge transfer is cast into a redundant information suppression formulation. Existing methods introduce sophisticated modules, architecture-tailored designs, and excessive parameters, which impair their efficiency and applicability. We propose to extract the architecture-agnostic knowledge in heterogeneous representations by reducing the redundant architecture-exclusive information. To this end, we present a simple redundancy suppression distillation (RSD) loss, which comprises cross-architecture invariance maximization and feature decorrelation objectives. To prevent the student from entirely losing its architecture-specific capabilities, we further design a lightweight module that decouples the RSD objective from the student's internal representations. Our method is devoid of the architecture-specific designs and complex operations in the pioneering method of OFA. It substantially outperforms OFA on CIFAR-100 and ImageNet-1k benchmarks with only a fraction of their parameter overhead, which highlights its potential as a simple and strong baseline to the cross-architecture distillation community. Our code and models will be made publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 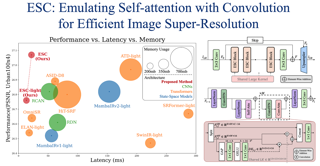
Abstract
In this paper, we tackle the high computational cost of transformers for lightweight image super-resolution (SR).Motivated by the observations of self-attention's inter-layer repetition, we introduce a convolutionized self-attention module named Convolutional Attention (ConvAttn) that emulates self-attention's long-range modeling capability and instance-dependent weighting with a single shared large kernel and dynamic kernels.By utilizing the ConvAttn module, we significantly reduce the reliance on self-attention and its involved memory-bound operations while maintaining the representational capability of transformers.Furthermore, we overcome the challenge of integrating flash attention into the lightweight SR regime, effectively mitigating self-attention's inherent memory bottleneck.We scale up window size to 32$\times$32 with flash attention rather than proposing an intricated self-attention module, significantly improving PSNR by 0.31dB on Urban100$\times$2 while reducing latency and memory usage by 16$\times$ and 12.2$\times$.Building on these approaches, our proposed network, termed Emulating Self-attention with Convolution (ESC), notably improves PSNR by 0.27 dB on Urban100$\times$4 compared to HiT-SRF, reducing the latency and memory usage by 3.7$\times$ and 6.2$\times$, respectively.Extensive experiments demonstrate that our ESC maintains the ability for long-range modeling, data scalability, and the representational power of transformers despite most self-attentions being replaced by the ConvAttn module.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Research on differentiable scene representations is consistently moving towards more efficient, real-time models. Recently, this has led to the popularization of splatting methods, which eschew the traditional ray-based rendering of radiance fields in favor of rasterization. This has yielded a significant improvement in rendering speeds due to the efficiency of rasterization algorithms and hardware, but has come at a cost: the approximations that make rasterization efficient also make implementation of light transport phenomena like reflection and refraction much more difficult. We propose a novel scene representation which avoids these approximations, but keeps the efficiency and reconstruction quality of splatting by leveraging a decades-old efficient volumetric mesh ray tracing algorithm which has been largely overlooked in recent computer vision research. The resulting model, which we name Radiant Foam, achieves rendering speed and quality comparable to Gaussian Splatting, without the constraints of rasterization. Unlike ray traced Gaussian models that use hardware ray tracing acceleration, our method requires no special hardware or APIs beyond the standard features of a programmable GPU.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 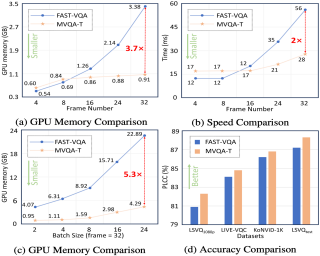
Abstract
The rapid growth of long-duration, high-definition videos has made efficient video quality assessment (VQA) a critical challenge. Existing research typically tackles this problem through two main strategies: reducing model parameters and resampling inputs. However, light-weight Convolution Neural Networks (CNN) and Transformers often struggle to balance efficiency with high performance due to the requirement of long-range modeling capabilities. Recently, the state-space model, particularly Mamba, has emerged as a promising alternative, offering linear complexity with respect to sequence length. Meanwhile, efficient VQA heavily depends on resampling long sequences to minimize computational costs, yet current resampling methods are often weak in preserving essential semantic information. In this work, we present MVQA, a Mamba-based model designed for efficient VQA along with a novel Unified Semantic and Distortion Sampling (USDS) approach. USDS combines semantic patch sampling from low-resolution videos and distortion patch sampling from original-resolution videos. The former captures semantically dense regions, while the latter retains critical distortion details. To prevent computation increase from dual inputs, we propose a fusion mechanism using pre-defined masks, enabling a unified sampling strategy that captures both semantic and quality information without additional computational burden. Experiments show that the proposed MVQA, equipped with USDS, achieve comparable performance to state-of-the-art methods …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Achieving flexible and high-fidelity identity-preserved image generation remains formidable, particularly with advanced Diffusion Transformers (DiTs) like FLUX. We introduce InfiniteYou (InfU), one of the earliest robust frameworks leveraging DiTs for this task. InfU addresses significant issues of existing methods, such as insufficient identity similarity, poor text-image alignment, and low generation quality and aesthetics. Central to InfU is InfuseNet, a component that injects identity features into the DiT base model via residual connections, enhancing identity similarity while maintaining generation capabilities. A multi-stage training strategy, including pretraining and supervised fine-tuning (SFT) with synthetic single-person-multiple-sample (SPMS) data, further improves text-image alignment, ameliorates image quality, and alleviates face copy-pasting. Extensive experiments demonstrate that InfU achieves state-of-the-art performance, surpassing existing baselines. In addition, the plug-and-play design of InfU ensures compatibility with various existing methods, offering a valuable contribution to the broader community.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In this work, we address activity-biometrics, which involves identifying individuals across diverse set of activities. Unlike traditional person identification, this setting introduces additional challenges as identity cues become entangled with motion dynamics and appearance variations, making biometrics feature learning more complex. While additional visual data like pose and/or silhouette help, they often struggle from extraction inaccuracies. To overcome this, we propose a multimodal language-guided framework that replaces reliance on additional visual data with structured textual supervision. At its core, we introduce **DisenQ** (**Disen**tangling **Q**-Former), a unified querying transformer that disentangles biometrics, motion, and non-biometrics features by leveraging structured language guidance. This ensures identity cues remain independent of appearance and motion variations, preventing misidentifications. We evaluate our approach on three activity-based video benchmarks, achieving state-of-the-art performance. Additionally, we demonstrate strong generalization to complex real-world scenario with competitive performance on a traditional video-based identification benchmark, showing the effectiveness of our framework.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
With more event datasets being released online, safeguarding the event dataset against unauthorized usage has become a serious concern for data owners. Unlearnable Examples are proposed to prevent the unauthorized exploitation of image datasets. However, it's unclear how to create unlearnable asynchronous event streams to prevent event misuse. In this work, we propose the first unlearnable event stream generation method to prevent unauthorized training from event datasets. A new form of asynchronous event error-minimizing noise is proposed to perturb event streams, tricking the unauthorized model into learning embedded noise instead of realistic features. To be compatible with the sparse event, a projection strategy is presented to sparsify the noise to render our unlearnable event streams (UEvs). Extensive experiments demonstrate that our method effectively protects event data from unauthorized exploitation, while preserving their utility for legitimate use. We hope our UEvs contribute to the advancement of secure and trustworthy event dataset sharing.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 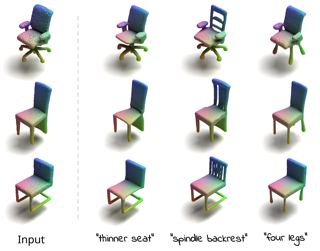
Abstract
Natural language offers a highly intuitive interface for enabling localized fine-grained edits of 3D shapes. However, prior works face challenges in preserving global coherence while locally modifying the input 3D shape. In this work, we introduce an inpainting-based framework for editing shapes represented as point clouds. Our approach leverages foundation 3D diffusion models for achieving localized shape edits, adding structural guidance in the form of a partial conditional shape, ensuring that other regions correctly preserve the shape's identity. Furthermore, to encourage identity preservation also within the local edited region, we propose an inference-time coordinate blending algorithm which balances reconstruction of the full shape with inpainting at a progression of noise levels during the inference process. Our coordinate blending algorithm seamlessly blends the original shape with its edited version, enabling a fine-grained editing of 3D shapes, all while circumventing the need for computationally expensive and often innacurate inversion. Extensive experiments show that our method outperforms alternative techniques across a wide range of metrics that evaluate both fidelity to the original shape and also adherence to the textual description. We will release our code and trained models.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 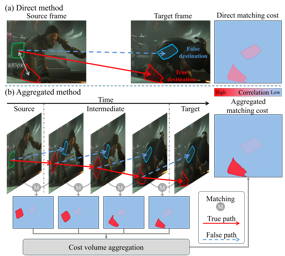
Abstract
With advancements in sensor and display technologies, high-resolution imagery is becoming increasingly prevalent in diverse applications. As a result, optical flow estimation needs to adapt to larger image resolutions, where even moderate movements lead to substantial pixel displacements, making long-range motion estimation more critical than ever. However, existing datasets primarily focus on short-range flow in low-resolution settings, limiting the generalization of models to high-resolution scenarios with large displacements. Additionally, there is a lack of suitable datasets for evaluating model capacity in long-range motion estimation, further hindering progress in this area. To address this, we introduce RelayFlow-4K, high-resolution 4K optical flow dataset designed to capture diverse motion patterns, including long-range intermediate frame flows. While such datasets provide valuable training resources, long-range estimation remains challenging due to increased matching ambiguity. Simply incorporating these datasets does not inherently improve performance. To this end, we propose a novel training framework that integrates matching cost distillation and incremental time-step learning to refine cost volume estimation and stabilize training. Additionally, we leverage the distance map, which measures the distance from unmatched regions to their nearest matched pixels, improving occlusion handling. Our approach significantly enhances long-range optical flow estimation in high-resolution settings. Our datasets and code will …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Impressive results on real-world image super-resolution (Real-ISR) have been achieved by employing pre-trained stable diffusion (SD) models. However, one well-known yet critical issue of such methods lies in their poor reconstruction of image fine structures, such as small characters and textures, due to the aggressive resolution reduction of the VAE (e.g., 8$\times$ downsampling) in the SD model. One solution is to employ a VAE with a lower downsampling rate for diffusion; however, adapting its latent features with the pre-trained UNet to preserve the diffusion prior while mitigating the increased computational cost poses new challenges. To address these issues, we propose a transfer VAE training (TVT) strategy to transfer the 8$\times$ downsampled VAE into a 4$\times$ one while preserving the pre-trained diffusion prior. Specifically, we first train a 4$\times$ decoder based on the output features of the original VAE encoder, then train a 4$\times$ encoder while keeping the newly trained decoder fixed. Such a TVT strategy helps align the new encoder-decoder pair with the original VAE latent space while enhancing image fine details. Additionally, we introduce a compact VAE and compute-efficient UNet by optimizing their network architectures, reducing the overall computational cost while effectively capturing high-resolution fine-scale features. Experimental results demonstrate …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Generating accurate, informative, and hallucination-free captions for charts remains challenging for vision language models, primarily due to the lack of large-scale, high-quality datasets of real-world charts. However, existing real-world chart datasets suffer from the inclusion of extraneous information that cannot be inferred from the chart and failure to sufficiently capture structural elements and key insights. Therefore, we introduce ChartCap, a large-scale dataset of 565K real-world chart images paired with type-specific, dense captions that exclude extraneous information and highlight both structural elements and key insights in detail. To build ChartCap, we design a four-stage pipeline that generates captions using only the discernable data from the chart and employ a cycle consistency-based human verification, which accelerates quality control without sacrificing accuracy. Additionally, we propose a novel metric, the Visual Consistency Score, which evaluates caption quality by measuring the similarity between the chart regenerated from a caption and the original chart, independent of reference captions. Extensive experiments confirms that models fine-tuned on ChartCap consistently generate more accurate and informative captions with reduced hallucinations, surpassing not only open-source and proprietary models but also even human-annotated captions.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 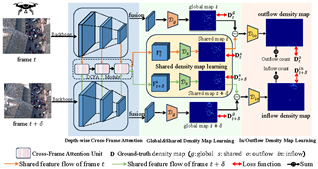
Abstract
Video Individual Counting (VIC) has received increasing attentions recently due to its importance in intelligent video surveillance. Existing works are limited in two aspects, i.e., dataset and method. Previous crowd counting datasets are captured with fixed or rarely moving cameras with relatively sparse individuals, restricting evaluation for a highly varying view and time in crowded scenes. While VIC methods have been proposed based on localization-then-association or localization-then-classification, they may not perform well due to difficulty in accurate localization of crowded and small targets under challenging scenarios. To address these issues, we collect a MovingDroneCrowd Dataset and propose a density map based VIC method. Different from existing datasets, our dataset consists of videos captured by fast-moving drones in crowded scenes under diverse illuminations, shooting heights and angles. Other than localizing individuals, we propose a Depth-wise Cross-Frame Attention (DCFA) module, which directly estimate inflow and outflow density maps to learn shared density between consecutive frames. The inflow density maps across frames are summed up to obtain the number of unique pedestrians in a video. Experiments on our datasets and publicly available ones the the superiority of our method over the state of the arts for VIC in highly dynamic and complex crowded …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The rapid advancements in generative technology have emerged as a double-edged sword. While offering powerful tools that enhance convenience, they also pose significant social concerns. As defenders, current synthetic image detection methods often lack artifact-level textual interpretability and are overly focused on image manipulation detection, and current datasets usually suffer from outdated generators and a lack of fine-grained annotations. In this paper, we introduce SynthScars, a high-quality and diverse dataset consisting of 12,236 fully synthetic images with human-expert annotations. It features 4 distinct image content types, 3 categories of artifacts, and fine-grained annotations covering pixel-level segmentation, detailed textual explanations, and artifact category labels. Furthermore, we propose LEGION (LEarning to Ground and explain for Synthetic Image detectiON), a multimodal large language model~(MLLM)-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation.Building upon this capability, we further explore LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments show that LEGION outperforms existing methods across multiple benchmarks, particularly surpassing the second-best traditional expert on SynthScars by 3.31\% in mIoU and 7.75\% in F1 score. Moreover, the refined images generated under its guidance exhibit stronger alignment with human preferences. …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
High-throughput screening techniques, such as microscopy imaging of cellular responses to genetic and chemical perturbations, play a crucial role in drug discovery and biomedical research. However, robust perturbation screening for \textit{de novo} cell lines remains challenging due to the significant morphological and biological heterogeneity across cell lines. To address this, we propose a novel framework that integrates external biological knowledge into existing pretraining strategies to enhance microscopy image profiling models. Our approach explicitly disentangles perturbation-specific and cell line-specific representations using external biological information. Specifically, we construct a knowledge graph leveraging protein interaction data from STRING and Hetionet databases to guide models toward perturbation-specific features during pretraining. Additionally, we incorporate transcriptomic features from single-cell foundation models to capture cell line-specific representations. By learning these disentangled features, our method improves the generalization of imaging models to \textit{de novo} cell lines. We evaluate our framework on the RxRx database through one-shot fine-tuning on an RxRx1 cell line and few-shot fine-tuning on cell lines from the RxRx19a dataset. Experimental results demonstrate that our method enhances microscopy image profiling for \textit{de novo} cell lines, highlighting its effectiveness in real-world phenotype-based drug discovery applications.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Blind Face Restoration aims to recover high-fidelity, detail-rich facial images from unknown degraded inputs, presenting significant challenges in preserving both identity and detail. Pre-trained diffusion models have been increasingly used as image priors to generate fine details. Still, existing methods often use fixed diffusion sampling timesteps and a global guidance scale, assuming uniform degradation. This limitation and potentially imperfect degradation kernel estimation frequently lead to under- or over-diffusion, resulting in an imbalance between fidelity and quality. We propose DynFaceRestore, a novel blind face restoration approach that learns to map any blindly degraded input to Gaussian blurry images. By leveraging these blurry images and their respective Gaussian kernels, we dynamically select the starting timesteps for each blurry image and apply closed-form guidance during the diffusion sampling process to maintain fidelity. Additionally, we introduce a dynamic guidance scaling adjuster that modulates the guidance strength across local regions, enhancing detail generation in complex areas while preserving structural fidelity in contours. This strategy effectively balances the trade-off between fidelity and quality. DynFaceRestore achieves state-of-the-art performance in both quantitative and qualitative evaluations, demonstrating robustness and effectiveness in blind face restoration.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This prospective study proposes CoMatch, a novel semi-dense image matcher with dynamic covisibility awareness and bilateral subpixel accuracy. Firstly, observing that modeling context interaction over the entire coarse feature map elicits highly redundant computation due to the neighboring representation similarity of tokens, a covisibility-guided token condenser is introduced to adaptively aggregate tokens in light of their covisibility scores that are dynamically estimated, thereby ensuring computational efficiency while improving the representational capacity of aggregated tokens simultaneously. Secondly, considering that feature interaction with massive non-covisible areas is distracting, which may degrade feature distinctiveness, a covisibility-assisted attention mechanism is deployed to selectively suppress irrelevant message broadcast from non-covisible reduced tokens, resulting in robust and compact attention to relevant rather than all ones. Thirdly, we find that at the fine-level stage, current methods adjust only the target view's keypoints to subpixel level, while those in the source view remain restricted at the coarse level and thus not informative enough, detrimental to keypoint location-sensitive usages. A simple yet potent fine correlation module is developed to refine the matching candidates in both source and target views to subpixel level, attaining attractive performance improvement. Thorough experimentation across an array of public benchmarks affirms CoMatch’s promising accuracy, efficiency, …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Visual grounding (VG) is the capability to identify the specific regions in an image associated with a particular text description. In medical imaging, VG enhances interpretability by highlighting relevant pathological features corresponding to textual descriptions, improving model transparency and trustworthiness for wider adoption of deep learning models in clinical practice. Current models struggle to associate textual descriptions with disease regions due to inefficient attention mechanisms and a lack of fine-grained token representations. In this paper, we empirically demonstrate two key observations. First, current VLMs assign high norms to background tokens, diverting the model's attention from regions of disease. Second, the global tokens used for cross-modal learning are not representative of local disease tokens. This hampers identifying correlations between the text and disease tokens. To address this, we introduce simple, yet effective Disease-Aware Prompting (DAP) process, which uses the explainability map of a VLM to identify the appropriate image features. This simple strategy amplifies disease-relevant regions while suppressing background interference. Without any additional pixel-level annotations, DAP improves visual grounding accuracy by 20.74\% compared to state-of-the-art methods across three major chest X-ray datasets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Structure and continuous motion estimation from point correspondences is a fundamental problem in computer vision that has been powered by well-known algorithms such as the familiar 5-point or 8-point algorithm. However, despite their acclaim, these algorithms are limited to processing point correspondences originating from a pair of views each one representing an instantaneous capture of the scene. Yet, in the case of rolling shutter cameras, or more recently, event cameras, this synchronization breaks down. In this work, we present a unified approach for structure and linear motion estimation from 2D point correspondences with arbitrary timestamps, from an arbitrary set of views. By formulating the problem in terms of first-order dynamics and leveraging a constant velocity motion model, we derive a novel, linear point incidence relation allowing for the efficient recovery of both linear velocity and 3D points with predictable degeneracies and solution multiplicities. Owing to its general formulation, it can handle correspondences from a wide range of sensing modalities such as global shutter, rolling shutter, and event cameras, and can even combine correspondences from different collocated sensors. We validate the effectiveness of our solver on both simulated and real-world data, where we show consistent improvement across all modalities when compared …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Recent breakthroughs and rapid integration of generative models (GMs) have sparked interest in the problem of model attribution and their fingerprints. For instance, service providers need reliable methods of authenticating their models to protect their IP, while users and law enforcement seek to verify the source of generated content for accountability and trust. In addition, a growing threat of model collapse is arising, as more model-generated data are being fed back into sources (e.g., YouTube) that are often harvested for training (``regurgitative training''), heightening the need to differentiate synthetic from human data. Yet, a gap still exists in understanding generative models' fingerprints, we believe, stemming from the lack of a formal framework that can define, represent, and analyze the fingerprints in a principled way. To address this gap, we take a geometric approach and propose a new definition of artifact and fingerprint of generative models using Riemannian geometry, which allows us to leverage the rich theory of differential geometry. Our new definition generalizes previous work (Song et al, 2024) to non-Euclidean manifolds by learning Riemannian metrics from data and replacing the Euclidean distances and nearest-neighbor search with geodesic distances and $k$NN-based Riemannian center of mass. We apply our theory to …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We introduce HouseCrafter, a novel approach that can lift a 2D floorplan into a complete large 3D indoor scene (\eg, a house). Our key insight is to adapt a 2D diffusion model, which is trained on web-scale images, to generate consistent multi-view color (RGB) and depth (D) images across different locations of the scene. Specifically, the RGB-D images are generated autoregressively in batches along sampled locations derived from the floorplan. At each step, the diffusion model conditions on previously generated images to produce new images at nearby locations. The global floorplan and attention design in the diffusion model ensures the consistency of the generated images, from which a 3D scene can be reconstructed. Through extensive evaluation on the 3D-FRONT dataset, we demonstrate that HouseCrafter can generate high-quality house-scale 3D scenes. Ablation studies also validate the effectiveness of different design choices. We will release our code and model weights.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Video face restoration faces a critical challenge in maintaining temporal consistency while recovering fine facial details from degraded inputs. This paper presents a novel approach that extends Vector-Quantized Variational Autoencoders (VQ-VAEs), pretrained on static high-quality portraits, into a video restoration framework through variational latent space modeling. Our key innovation lies in reformulating discrete codebook representations as Dirichlet-distributed continuous variables, enabling probabilistic transitions between facial features across frames. A spatio-temporal Transformer architecture jointly models inter-frame dependencies and predicts latent distributions, while a Laplacian-constrained reconstruction loss combined with perceptual (LPIPS) regularization enhances both pixel accuracy and visual quality. Comprehensive evaluations on blind face restoration, video inpainting, and facial colorization tasks demonstrate state-of-the-art performance. This work establishes an effective paradigm for adapting intensive image priors, pretrained on high-quality images, to video restoration while addressing the critical challenge of flicker artifacts.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 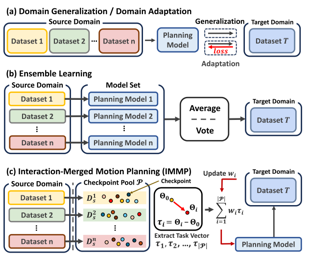
Abstract
Motion planning is a crucial component of autonomous robot driving. While various trajectory datasets exist, effectively utilizing them for a target domain remains challenging due to differences in agent interactions and environmental characteristics. Conventional approaches, such as domain adaptation or ensemble learning, leverage multiple source datasets but suffer from domain imbalance, catastrophic forgetting, and high computational costs. To address these challenges, we propose Interaction-Merged Motion Planning (IMMP), a novel approach that leverages parameter checkpoints trained on different domains during adaptation to the target domain. IMMP follows a two-step process: pre-merging to capture agent behaviors and interactions, sufficiently extracting diverse information from the source domain, followed by merging to construct an adaptable model that efficiently transfers diverse interactions to the target domain. Our method is evaluated on various planning benchmarks and models, demonstrating superior performance compared to conventional approaches.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We introduce Geo4D, a method to repurpose video diffusion models for monocular 3D reconstruction of dynamic scenes.By leveraging the strong dynamic prior captured by such video models, Geo4D can be trained using only synthetic data while generalizing well to real data in a zero-shot manner. Geo4D predicts several complementary geometric modalities, namely point, depth, and ray maps. It uses a new multi-modal alignment algorithm to align and fuse these modalities, as well as multiple sliding windows, at inference time, thus obtaining robust and accurate 4D reconstruction of long videos. Extensive experiments across multiple benchmarks show that Geo4D significantly surpasses state-of-the-art video depth estimation methods, including recent methods such as MonST3R, which are also designed to handle dynamic scenes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Generative videos have the potential to revolutionize game development by autonomously creating new content. In this paper, we present GameFactory, a framework for action-controlled scene-generalizable game video generation. We first address the fundamental challenge of action controllability by introducing GF-Minecraft, a action-annotated game video dataset without human bias, and developing a action control module that enables precise control over both keyboard and mouse inputs. We further extend to support autoregressive generation for unlimited-length interactive videos.More importantly, GameFactory tackles the critical challenge of scene-generalizable action control, which most existing methods fail to address. To enable the creation of entirely new and diverse games beyond fixed styles and scenes, we leverage the open-domain generative priors from pre-trained video diffusion models. To bridge the domain gap between open-domain priors and small-scale game datasets, we propose a multi-phase training strategy with a domain adapter that decouples game style learning from action control. This decoupling ensures that action control learning is no longer bound to specific game styles, thereby achieving scene-generalizable action control.Experimental results demonstrate that GameFactory effectively generates open-domain action-controllable game videos, representing a significant step forward in AI-driven game generation. Our dataset and code will be publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In recent years, researchers have explored the task of open-vocabulary video instance segmentation, which aims to identify, track, and segment any instance within an open set of categories. The core challenge of Open-Vocabulary VIS lies in solving the cross-domain alignment problem, including spatial-temporal and text-visual domain alignments. Existing methods have made progress but still face shortcomings in addressing these alignments, especially due to data heterogeneity. Inspired by metric learning, we propose an innovative Sliced Wasserstein Bridging Learning Framework. This framework utilizes the Sliced Wasserstein distance as the core tool for metric learning, effectively bridging the four domains involved in the task. Our innovations are threefold: (1) Domain Alignment: By mapping features from different domains into a unified metric space, our method maintains temporal consistency and learns intrinsic consistent features between modalities, improving the fusion of text and visual information. (2) Weighting Mechanism: We introduce an importance weighting mechanism to enhance the discriminative ability of our method when dealing with imbalanced or significantly different data. (3) High Efficiency: Our method inherits the computational efficiency of the Sliced Wasserstein distance, allowing for online processing of large-scale video data while maintaining segmentation accuracy. Through extensive experimental evaluations, we have validated the robustness of …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Supervised learning has been the dominant approach for developing detectors of AI-generated face images. However, the reliance on pre-generated face samples often limits the adaptability to the diverse and rapidly evolving landscape of AI face generators. Here, we propose a bi-level optimization framework for self-supervised AI-generated face detection, relying solely on photographic images and aligning the pretext tasks with the downstream AI face detection. The inner loop optimization aims to train a feature extractor using linearly weighted objectives of several pretext tasks, including classifying categorical exchangeable image file format (EXIF) tags, ranking ordinal EXIF tags, and identifying global and local face manipulations. The outer loop optimization treats the coarse-grained detection of face manipulations as a surrogate task for AI-generated image detection, directing the feature extractor to adapt to detecting AI faces by optimizing the linear weightings to align the task relationships. To validate the effectiveness of our self-supervised features, we first frame AI-generated face detection as one-class classification, and model the feature distribution of photographic images using a Gaussian mixture model. Faces with low likelihoods are flagged as AI-generated. Additionally, we train a two-layer perceptron based on the extracted self-supervised features as a simple binary classifier. We demonstrate by comprehensive …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Monocular and stereo depth estimation offer complementary strengths: monocular methods capture rich contextual priors but lack geometric precision, while stereo approaches leverage epipolar geometry but struggle with ambiguities such as reflective or textureless surfaces.Despite their synergies, these paradigms remain largely disjoint in practice.We introduce OmniDepth, a unified framework that bridges both through iterative bidirectional alignment of their latent representations.At its core, a novel cross-attentive alignment mechanism dynamically synchronizes monocular contextual cues with disparity hypothesis representations during stereo reasoning.This mutual alignment resolves stereo ambiguities (e.g., specular surfaces) by injecting monocular structure priors while refining monocular depth with stereo geometry.Extensive experiments demonstrate state-of-the-art results: OmniDepth reduces zero-shot generalization error by $\!>\!40\%$ on Middlebury and ETH3D compared to leading stereo methods, while addressing longstanding failure cases on transparent and reflective surfaces.By harmonizing multi-view geometry with monocular context, OmniDepth advances robust 3D perception that transcends modality-specific limitations.Code and models will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We present the first work demonstrating that a pure Mamba block can achieve efficient Dense Global Fusion, meanwhile guaranteeing top performance for camera-LiDAR multi-modal 3D object detection. Our motivation stems from the observation that existing fusion strategies are constrained by their inability to simultaneously achieve efficiency, long-range modeling, and retaining complete scene information. Inspired by recent advances in state-space models (SSMs) and linear attention, we leverage their linear complexity and long-range modeling capabilities to address these challenges. However, this is non-trivial since our experiments reveal that simply adopting efficient linear-complexity methods does not necessarily yield improvements and may even degrade performance. We attribute this degradation to the loss of height information during multi-modal alignment, leading to deviations in sequence order. To resolve this, we propose height-fidelity LiDAR encoding that preserves precise height information through voxel compression in continuous space, thereby enhancing camera-LiDAR alignment. Subsequently, we introduce the Hybrid Mamba Block, which leverages the enriched height-informed features to conduct local and global contextual learning. By integrating these components, our method achieves state-of-the-art performance with the top-tire NDS score of 75.0 on the nuScenes validation benchmark, even surpassing methods that utilize high-resolution inputs. Meanwhile, our method maintains efficiency, achieving faster inference speed …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Prosthetic legs play a pivotal role in clinical rehabilitation, allowing individuals with lower-limb amputations the ability to regain mobility and improve their quality of life. Gait analysis is fundamental for optimizing prosthesis design and alignment, directly impacting the mobility and life quality of individuals with lower-limb amputations. Vision-based machine learning (ML) methods offer a scalable and non-invasive solution to gait analysis, but face challenges in correctly detecting and analyzing prosthesis, due to their unique appearances and new movement patterns. In this paper, we aim to bridge this gap by introducing a multi-purpose dataset, namely ProGait, to support multiple vision tasks including Video Object Segmentation, 2D Human Pose Estimation, and Gait Analysis (GA). ProGait provides 412 video clips from four above-knee amputees when testing multiple newly-fitted prosthetic legs through walking trials, and depicts the presence, contours, poses, and gait patterns of human subjects with transfemoral prosthetic legs. Alongside the dataset itself, we also present benchmark tasks and fine-tuned baseline models to illustrate the practical application and performance of the ProGait dataset. We compared our baseline models against pre-trained vision models, demonstrating improved generalizability when applying the ProGait dataset for prosthesis-specific tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 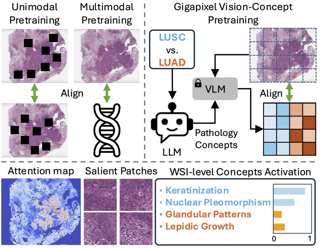
Abstract
Pretraining a Multiple Instance Learning (MIL) aggregator enables the derivation of Whole Slide Image (WSI)-level embeddings from patch-level representations without supervision. While recent multimodal MIL pretraining approaches leveraging auxiliary modalities have demonstrated performance gains over unimodal WSI pretraining, the acquisition of these additional modalities necessitates extensive clinical profiling. This requirement increases costs and limits scalability in existing WSI datasets lacking such paired modalities. To address this, we propose Gigapixel Vision-Concept Knowledge Contrastive pretraining (GECKO), which aligns WSIs with a Concept Prior derived from the available WSIs. First, we derive an inherently interpretable concept prior by computing the similarity between each WSI patch and textual descriptions of predefined pathology concepts. GECKO then employs a dual-branch MIL network: one branch aggregates patch embeddings into a WSI-level deep embedding, while the other aggregates the concept prior to a corresponding WSI-level concept embedding. Both aggregated embeddings are aligned using a contrastive objective, thereby pretraining the entire dual-branch MIL model. Moreover, when auxiliary modalities such as transcriptomics data are available, GECKO seamlessly integrates them. Across five diverse tasks, GECKO consistently outperforms prior unimodal and multimodal pretraining approaches while also delivering clinically meaningful interpretability that bridges the gap between computational models and pathology expertise.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Visual object tracking and segmentation are becoming fundamental tasks for understanding human activities in egocentric vision. Recent research has benchmarked state-of-the-art methods and concluded that first person egocentric vision presents challenges compared to previously studied domains. However, these claims are based on evaluations conducted across significantly different scenarios. Many of the challenging characteristics attributed to egocentric vision are also present in third person videos of human-object activities. This raises a critical question: how much of the observed performance drop stems from the unique first person viewpoint inherent to egocentric vision versus the domain of human-object activities? To address this question, we introduce a new benchmark study designed to disentangle such factors. Our evaluation strategy enables a more precise separation of challenges related to the first person perspective from those linked to the broader domain of human-object activity understanding. By doing so, we provide deeper insights into the true sources of difficulty in egocentric tracking and segmentation, facilitating more targeted advancements in this field.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 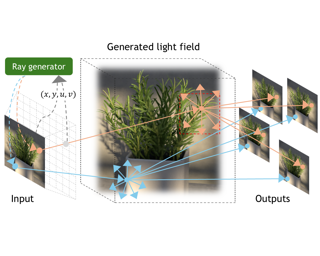
Abstract
A concept of light-fields computed from multiple view images on regular grids has proven its benefit for scene representations, and supported realistic renderings of novel views and photographic effects such as refocusing and shallow depth of field. In spite of its effectiveness of light flow computations, obtaining light fields requires either computational costs or specialized devices like a bulky camera setup and a specialized microlens array. In an effort to broaden its benefit and applicability, in this paper, we propose a novel view synthesis method for light field generation from only single images, named $\textit{inverse image-based rendering}$. Unlike previous attempts to implicitly rebuild 3D geometry or to explicitly represent objective scenes, our method reconstructs light flows in a space from image pixels, which behaves in the opposite way to image-based rendering. To accomplish this, we design a neural rendering pipeline to render a target ray in an arbitrary viewpoint. Our neural renderer first stores the light flow of source rays from the input image, then computes the relationships among them through cross-attention, and finally predicts the color of the target ray based on these relationships. After the rendering pipeline generates the first novel view from a single input image, the …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent feature matching methods have achieved remarkable performance but lack efficiency consideration. In this paper, we revisit the mainstream detector-free matching pipeline and improve all its stages considering both accuracy and efficiency. We propose an Efficient Deep feature Matching network, EDM. We first adopt a deeper CNN with fewer dimensions to extract multi-level features. Then we present a Correlation Injection Module that conducts feature transformation on high-level deep features, and progressively injects feature correlations from global to local for efficient multi-scale feature aggregation, improving both speed and performance. In the refinement stage, a novel lightweight bidirectional axis-based regression head is designed to directly predict subpixel-level correspondences from latent features, avoiding the significant computational cost of explicitly locating keypoints on high-resolution local feature heatmaps. Moreover, effective selection strategies are introduced to enhance matching accuracy. Extensive experiments show that our EDM achieves competitive matching accuracy on various benchmarks and exhibits excellent efficiency, offering valuable best practices for real-world applications. The code will be made publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Detectors often suffer from performance drop due to domain gap between training and testing data. Recent methods explore diffusion models applied to domain generalization (DG) and adaptation (DA) tasks, but still struggle with large inference costs and have not yet fully leveraged the capabilities of diffusion models. We propose to tackle these problems by extracting intermediate features from a single-step diffusion process, improving feature collection and fusion to reduce inference time by 75% while enhancing performance on source domains (i.e., Fitness). Then, we construct an object-centered auxiliary branch by applying box-masked images with class prompts to extract robust and domain-invariant features that focus on object. We also apply consistency loss to align the auxiliary and ordinary branch, balancing fitness and generalization while preventing overfitting and improving performance on target domains (i.e., Generalization). Furthermore, within a unified framework, standard detectors are guided by diffusion detectors through feature-level and object-level alignment on source domains (for DG) and unlabeled target domains (for DA), thereby improving cross-domain detection performance (i.e., Transferability). Our method achieves competitive results on 3 DA benchmarks and 5 DG benchmarks. Additionally, experiments on COCO generalization benchmark demonstrate that our method maintains significant advantages and show remarkable efficiency in large domain …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Direct preference optimization (DPO) has shown success in aligning diffusion models with human preference. However, We identify two potential risks for existing DPO algorithms: First, current DPO methods for estimating the rewards of step-wise intermediate samples are biased, leading to inaccurate preference ordering for step-wise optimization. Second, existing DPO methods may inadvertently increase the sampling probabilities of dispreferred samples, potentially introducing application risks. To address these issues, we propose Revised Direct Preference Optimization (RDPO), a simple but effective step-wise DPO-based text-to-image diffusion model alignment method. By designing a more theoretically grounded and efficient intermediate-step reward estimation and introducing an additional regularization terms to constrain the sampling probability of dispreferred samples, RDPO can achieve more effective and stable text-to-image alignment performance. Our experiments on two datasets, with base models including Stable Diffusion v1.5 and SDXL, demonstrate that RDPO can effectively learn and construct reward signals for each step of the model, improving alignment performance while ensuring better generalization.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Bokeh rendering methods play a key role in creating the visually appealing, softly blurred backgrounds seen in professional photography. While recent learning-based approaches show promising results, generating realistic Bokeh with controllable strength remains challenging. Existing methods require additional inputs and suffer from unrealistic Bokeh reproduction due to reliance on synthetic data. In this work, we propose Bokehlicious, a highly efficient network that provides intuitive control over Bokeh strength through an Aperture-Aware Attention mechanism, mimicking the physical lens aperture. To further address the lack of high-quality real-world data, we present RealBokeh, a novel dataset featuring 23,000 high-resolution (24-MP) images captured by professional photographers, covering diverse scenes with varied aperture and focal length settings. Evaluations on both our new RealBokeh and established Bokeh rendering benchmarks show that Bokehlicious consistently outperforms SOTA methods while significantly reducing computational cost and exhibiting strong zero-shot generalization. Our method and dataset further extend to defocus deblurring, achieving competitive results on the RealDOF benchmark. Our code and data will be public.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
X-ray imaging, based on penetration, enables detailed visualization of internal structures. Building on this capability, existing implicit 3D reconstruction methods have adapted the NeRF model and its variants for internal CT reconstruction. However, these approaches often neglect the significance of objects' anatomical priors for implicit learning, limiting both reconstruction precision and learning efficiency, particularly in ultra-sparse view scenarios. To address these challenges, we propose a novel 3D CT reconstruction framework that employs a 'target prior' derived from the object's projection data to enhance implicit learning. Our approach integrates positional and structural encoding to facilitate voxel-wise implicit reconstruction, utilizing the target prior to guide voxel sampling and enrich structural encoding. This dual strategy significantly boosts both learning efficiency and reconstruction quality. Additionally, we introduce a CUDA-based algorithm for rapid estimation of high-quality 3D target priors from sparse-view projections. Experiments utilizing projection data from a complex abdominal dataset demonstrate that the proposed model substantially enhances learning efficiency, outperforming the current leading model, NAF, by a factor of ten. In terms of reconstruction quality, it also exceeds the most accurate model, NeRP, achieving PSNR improvements of 3.57 dB, 5.42 dB, and 5.70 dB with 10, 20, and 30 projections, respectively. The code is …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they do not effectively address the specific challenges of geospatial applications.Generic VLM benchmarks are not designed to handle the complexities of geospatial data, an essential component for applications such as environmental monitoring, urban planning, and disaster management.Key challenges in the geospatial domain include temporal change detection, large-scale object counting, tiny object detection, and understanding relationships between entities in remote sensing imagery.To bridge this gap, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, segmentation, and temporal analysis. Our benchmark features over 10,000 manually verified instructions and spanning diverse visual conditions, object types, and scales.We evaluate several state-of-the-art VLMs to assess performance on geospatial-specific challenges. The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific tasks, highlighting the room for further improvements. Notably, the best-performing LLaVa-OneVision achieves only 41.7\% accuracy on MCQs, slightly more than GPT-4o, which is approximately double the random guess performance. Our benchmark will be publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Zero-shot depth completion with metric scales poses significant challenges, primarily due to performance limitations such as domain specificity and sensor characteristics. One recent emerging solution is to integrate monocular depth foundation models into depth completion frameworks, yet these efforts still face issues with suboptimal performance and often require further adaptation to the target task. Surprisingly, we find that a simple test-time training, which fine-tunes monocular depth foundation models on sparse depth measurements from sensors just as it is, yields reasonable results. However, this test-time training obviously incurs high computational costs and introduces biases towards specific conditions, making it impractical for real-world scenarios. In this paper, we introduce a new approach toward parameter-efficient zero-shot depth completion. Our key idea of this work is to leverage visual prompt tuning, achieving sensor-specific depth scale adaptation without forgetting foundational knowledge. Experimental results on diverse datasets demonstrate that our approach outperforms relevant state-of-the-art methods, showing superior generalization and efficiency. Our source code is available in the supplementary materials.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 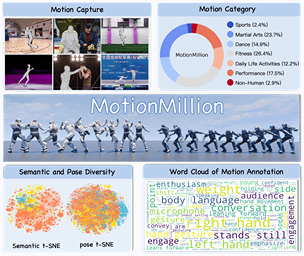
Abstract
Generating diverse and natural human motion sequences based on textual descriptions constitutes a fundamental and challenging research area within the domains of computer vision, graphics, and robotics. Despite significant advancements in this field, current methodologies often face challenges regarding zero-shot generalization capabilities, largely attributable to the limited size of training datasets. Moreover, the lack of a comprehensive evaluation framework impedes the advancement of this task by failing to identify directions for improvement. In this work, we aim to push text-to-motion into a new era, that is, to achieve the generalization ability of zero-shot. To this end, firstly, we develop an efficient annotation pipeline and introduce MotionMillion—the largest human motion dataset to date, featuring over 2,000 hours and 2 million high-quality motion sequences. Additionally, we propose MotionMillion-Eval, the most comprehensive benchmark for evaluating zero-shot motion generation. Leveraging a scalable architecture, we scale our model to 7B parameters and validate its performance on MotionMillion-Eval. Our results demonstrate strong generalization to out-of-domain and complex compositional motions, marking a significant step toward zero-shot human motion generation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Pre-trained vision-language models have exhibited remarkable abilities in detecting out-of-distribution (OOD) samples. However, some challenging OOD samples, which lie close to in-distribution (InD) data in image feature space, can still lead to misclassification. The emergence of foundation models like diffusion models and multimodal large language models (MLLMs) offers a potential solution to this issue. In this work, we propose SynOOD, a novel approach that harnesses foundation models to generate synthetic, challenging OOD data for fine-tuning CLIP models, thereby enhancing boundary-level discrimination between InD and OOD samples. Our method uses an iterative in-painting process guided by contextual prompts from MLLMs to produce nuanced, boundary-aligned OOD samples. These samples are refined through noise adjustments based on gradients from OOD scores like the energy score, effectively sampling from the InD/OOD boundary. With these carefully synthesized images, we fine-tune the CLIP image encoder and negative label features derived from the text encoder to strengthen connections between near-boundary OOD samples and a set of negative labels. Finally, SynOOD achieves state-of-the-art performance on the large-scale ImageNet benchmark, with minimal increases in parameters and runtime. Our approach significantly surpasses existing methods, improving AUROC by 2.80% and reducing FPR95 by 11.13%. The code for SynOOD will be made …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Affine Grassmannian has been favored for expressing proximity between lines and planes due to its theoretical exactness in measuring distances among features. Despite this advantage, the existing method can only measure the proximity without yielding the distance as an explicit function of rigid body transformation. Thus, an optimizable distance function on the manifold has remained underdeveloped, stifling its application in registration problems. This paper is the first to explicitly derive an optimizable cost function between two Grassmannian features with respect to rigid body transformation ($\mathbf{R}$ and $\mathbf{t}$). Specifically, we present a rigorous mathematical proof demonstrating that the bases of high-dimensional linear subspaces can serve as an explicit representation of the cost. Finally, we propose an optimizable cost function based on the transformed bases that can be applied to the registration problem of any affine subspace. Compared to vector parameter-based approaches, our method is able to find a globally optimal solution by directly minimizing the geodesic distance which is agnostic to representation ambiguity. The resulting cost function and its extension to the inlier-set maximizing Branch-and-Bound (BnB) solver have been demonstrated to improve the convergence of existing solutions or outperform them in various computer vision tasks. The code will be made available …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent advancements in multimodal large language models (MLLMs) have demonstrated exceptional performance in multimodal perception and understanding. However, leading open-source MLLMs exhibit significant limitations in complex and structured reasoning, particularly in tasks requiring deep reasoning for decision-making and problem-solving. In this work, we present Corvid, an MLLM with enhanced chain-of-thought (CoT) reasoning capabilities. Architecturally, Corvid incorporates a hybrid vision encoder for informative visual representation and a meticulously designed connector (GateMixer) to facilitate cross-modal alignment. To enhance Corvid's CoT reasoning capabilities, we introduce MCoT-Instruct-287K, a high-quality multimodal CoT instruction-following dataset, refined and standardized from diverse public reasoning sources. Leveraging this dataset, we fine-tune Corvid with a two-stage CoT-formatted training approach to progressively enhance its step-by-step reasoning abilities. Furthermore, we propose an effective inference-time scaling strategy that enables Corvid to mitigate over-reasoning and under-reasoning through self-verification. Extensive experiments demonstrate that Corvid outperforms existing o1-like MLLMs and state-of-the-art MLLMs with similar parameter scales, with notable strengths in mathematical reasoning and science problem-solving.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Backdoor attacks undermine the integrity of machine learning models by allowing attackers to manipulate predictions using poisoned training data. Such attacks lead to targeted misclassification when specific triggers are present, while the model behaves normally under other conditions. This paper considers a post-training backdoor defense task, aiming to detoxify the backdoors in pre-trained models. We begin by analyzing the underlying issues of vanilla fine-tuning and observe that it is often trapped in regions with low loss for both clean and poisoned samples. Motivated by such observations, we propose Distance-Driven Detoxification (D3), an innovative approach that reformulates backdoor defense as a constrained optimization problem. Specifically, D3 promotes the model's departure from the vicinity of its initial weights, effectively reducing the influence of backdoors. Extensive experiments on state-of-the-art (SOTA) backdoor attacks across various model architectures and datasets demonstrate that D3 not only matches but often surpasses the performance of existing SOTA post-training defense techniques.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 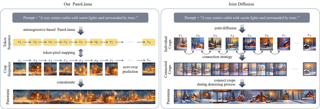
Abstract
Panoramic Image Generation (PIG) aims to create coherent images of arbitrary lengths. Most existing methods fall in the joint diffusion paradigm, but their complex and heuristic crop connection designs often limit their ability to achieve multilevel coherence. By deconstructing this challenge into its core components, we find it naturally aligns with next-token prediction, leading us to adopt an autoregressive (AR) paradigm for PIG modeling. However, existing visual AR (VAR) models are limited to fixed-size generation, lacking the capability to produce panoramic images. In this paper, we propose PanoLlama, a novel framework that achieves endless and coherent panorama generation with the autoregressive paradigm. Our approach develops a training-free strategy that utilizes token redirection to overcome the size limitations of existing VAR models, enabling next-crop prediction in both horizontal and vertical directions. This refreshes the PIG pipeline while achieving SOTA performance in coherence (47.50\%), fidelity(28.16\%), and aesthetics (15\%). Additionally, PanoLlama supports applications other PIG methods cannot achieve, including mask-free layout control, multi-scale and multi-guidance synthesis. To facilitate standardized evaluation, we also establish a dataset with 1,000 prompts spanning 100+ themes, providing a new testing benchmark for PIG research.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent GPUs leverage Winograd convolution and structured pruning to significantly accelerate inference.First, Winograd convolution is theoretically 2.25× faster than standard convolution.Second, structured pruning reduces inference time without additional overhead as the pruning ratio increases.However, applying conventional structured pruning alongside Winograd convolution is inefficient. Existing structured pruning methods, which do not account for how GPUs process Winograd convolution, require large pruning unit sizes, leading to significant information loss.In this paper, we propose Winograd Structured Pruning (WINS), \textbf{the first approach} to employ optimized structured pruning for Winograd convolution. WINS is designed based on an in-depth analysis of Winograd convolution's computational characteristics on GPUs.Additionally, we introduce two variants, WINS-B and WINS-AB, which further enhance performance. Experimental results show that WINS-AB achieves up to 2.8× practical speedup in Winograd convolution inference on GPUs while preserving the accuracy of ResNet-18 on ImageNet.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Segmentation of very large images is a common problem in microscopy, medical imaging or remote sensing. The problem is usually addressed by sliding window inference, which can theoretically lead to seamlessly stitched predictions. However, in practice many of the popular pipelines still suffer from tiling artifacts. We investigate the root cause of these issues and show that they stem from the normalization layers within the neural networks. We propose indicators to detect normalization issues and further explore the trade-offs between artifact-free and high-quality predictions, using three diverse microscopy datasets as examples. Finally, we propose to use BatchRenorm as the most suitable normalization strategy, which effectively removes tiling artifacts and enhances transfer performance, thereby improving the reusability of trained networks for new datasets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 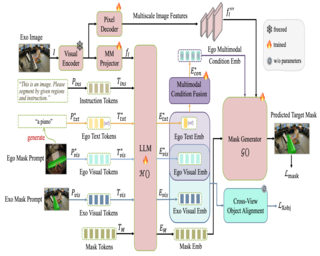
Abstract
Bridging the gap between ego-centric and exo-centric views has been a long-standing question in computer vision. In this paper, we focus on the emerging Ego-Exo object correspondence task, which aims to understand object relations across ego-exo perspectives through segmentation. While numerous segmentation models have been proposed, most operate on a single image (view), making them impractical for cross-view scenarios. PSALM, a recently proposed segmentation method, stands out as a notable exception with its demonstrated zero-shot ability on this task. However, due to the drastic viewpoint change between ego and exo, PSALM fails to accurately locate and segment objects, especially in complex backgrounds or when object appearances change significantly. To address these issues, we propose ObjectRelator, a novel approach featuring two key modules: Multimodal Condition Fusion (MCFuse) and SSL-based Cross-View Object Alignment (XObjAlign). MCFuse introduces language as an additional cue, integrating both visual masks and textual descriptions to improve object localization and prevent incorrect associations. XObjAlign enforces cross-view consistency through self-supervised alignment, enhancing robustness to object appearance variations. Extensive experiments demonstrate ObjectRelator’s effectiveness on the large-scale Ego-Exo4D benchmark and HANDAL-X (an adapted dataset for cross-view segmentation) with state-of-the-art performance. Codes and models will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
In recent years, text-to-image (T2I) diffusion models have garnered significant attention for their ability to generate high-quality images reflecting text prompts. However, their growing popularity has also led to the emergence of backdoor threats, posing substantial risks. Currently, effective defense strategies against such threats are lacking due to the diversity of backdoor targets in T2I synthesis. In this paper, we propose NaviDet, the first general input-level backdoor detection framework for identifying backdoor inputs across various backdoor targets. Our approach is based on the new observation that trigger tokens tend to induce significant neuron activation variation in the early stage of the diffusion generation process, a phenomenon we term Early-step Activation Variation. Leveraging this insight, NaviDetdetects malicious samples by analyzing neuron activation variations caused by input tokens. Through extensive experiments, we demonstrate the effectiveness and efficiency of our method against various T2I backdoor attacks, surpassing existing baselines with significantly lower computational overhead. Furthermore, we rigorously demonstrate that our method remains effective against potential adaptive attacks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We propose a model-agnostic, progressive test-time energy adaptation approach for medical image segmentation. Maintaining model performance across diverse medical datasets is challenging, as distribution shifts arise from inconsistent imaging protocols and patient variations. Unlike domain adaptation methods that require multiple passes through target data—impractical in clinical settings—our approach adapts pretrained models progressively as they process test data. Our method leverages a shape energy model trained on source data, which assigns an energy score at the patch level to segmentation maps: low energy represents in-distribution (accurate) shapes, while high energy signals out-of-distribution (erroneous) predictions. By minimizing this energy score at test time, we refine the segmentation model to align with the target distribution. To validate the effectiveness and adaptability, we evaluated our framework on eight public MRI (bSSFP, T1- and T2-weighted) and X-ray datasets spanning cardiac, spinal cord, and lung segmentation. We consistently outperform baselines both quantitatively and qualitatively.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 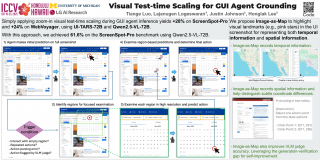
Abstract
We introduce RegionFocus, a visual test-time scaling approach that enhances GUI-based AI agents by leveraging visual cues to navigate the complexity of modern web interfaces. Understanding webpages is challenging due to the visual complexity of GUI images and the large number of interface elements, making accurate action selection difficult. Our approach dynamically zooms in on relevant regions, reducing background clutter and improving action accuracy without relying on extensive text-based reasoning. To support this process, we propose an image-as-history mechanism that visualizes key landmarks at each step, providing a transparent action record and enabling the agent to effectively choose among action candidates.Even with a simple region selection strategy, we observe significant performance gains of 31.7\% on Screenspot-pro and 34.9\% on WebVoyager benchmarks on top of a state-of-the-art open Vision Language Model Agent, highlighting the effectiveness of visual test-time scaling in interactive settings.Our code will be released publicly.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We completely classify all minimal problems for Structure-from-Motion (SfM) where arrangements of points and lines are fully observed by multiple uncalibrated pinhole cameras. We find 291 minimal problems, 73 of which have unique solutions and can thus be solved linearly.Two of the linear problems allow an arbitrary number of views, while all other minimal problems have at most 9 cameras. All minimal problems have at most 7 points and at most 12 lines. We compute the number of solutions of each minimal problem, as this gives a measurement of the problem's intrinsic difficulty, and find that these number are relatively low (e.g., when comparing with minimal problems for calibrated cameras). Finally, by exploring stabilizer subgroups of subarrangements, we develop a geometric and systematic way to 1) factorize minimal problems into smaller problems, 2) identify minimal problems in underconstrained problems, and 3) formally prove non-minimality.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
This paper investigates the recently emerged problem of Language-assisted Image Clustering (LaIC), where textual semantics are leveraged to improve the discriminability of visual representations to facilitate image clustering. Due to the unavailability of true class names, one of core challenges of LaIC lies in how to filter positive nouns, i.e., those semantically close to the images of interest, from unlabeled wild corpus data.Existing filtering strategies are predominantly based on the off-the-shelf feature space learned by CLIP; however, despite being intuitive, these strategies lack a rigorous theoretical foundation. To fill this gap, we propose a novel gradient-based framework, termed as GradNorm, which is theoretically guaranteed and shows strong empirical performance. In particular, we measure the positiveness of each noun based on the magnitude of gradients back-propagated from the cross-entropy between the predicted target distribution and the softmax output. Theoretically, we provide a rigorous error bound to quantify the separability of positive nouns by GradNorm and prove that GradNorm naturally subsumes existing filtering strategies as extremely special cases of itself. Empirically, extensive experiments show that GradNorm achieves the state-of-the-art clustering performance on various real-world settings.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in interpreting images using natural language. However, without using large-scale datasets for retraining, these models are difficult to adapt to specialized vision tasks, e.g., chart understanding. This problem is caused by a mismatch between pre-training and downstream datasets: pre-training datasets primarily concentrate on scenes and objects but contain limited information about specialized, non-object images, such as charts and tables. In this paper, we share an interesting finding that training an MLLM with chain-of-thought (CoT) reasoning data can facilitate model adaptation in specialized vision tasks, especially under data-limited regimes. However, we identify a critical issue within CoT data distilled from pre-trained MLLMs, i.e., the data often contains multiple factual errors in the reasoning steps. To address the problem, we propose Grounded Chain-of-Thought (GCoT), a simple bootstrapping-based approach that aims to inject grounding information (i.e., bounding boxes) into CoT data, essentially making the reasoning steps more faithful to input images. We evaluate our approach on five specialized vision tasks, which cover a variety of visual formats including charts, tables, receipts, and reports. The results demonstrate that under data-limited regimes our approach significantly improves upon fine-tuning and distillation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 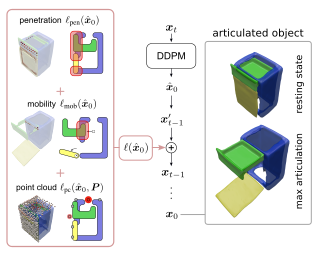
Abstract
Articulated objects are an important type of interactable objects in everyday environments. In this paper, we propose a novel diffusion model-based approach for generating articulated objects that aligns them with partial point clouds and improves their physical plausibility. The model represents part shapes by signed distance functions (SDFs). We guide the reverse diffusion process using a point cloud alignment loss computed using the predicted SDFs. Additionally, we impose non-penetration and mobility constraints based on the part SDFs for guiding the model to generate more physically plausible objects. We also make our diffusion approach category-aware to further improve point cloud alignment if category information is available. We evaluate the generative ability and constraint consistency of samples generated with our approach using the PartNet-Mobility dataset. We also compare our approach with an unguided baseline diffusion model and demonstrate that our method can improve constraint consistency and provides a tradeoff with generative ability.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent advances in optical flow estimation have prioritized accuracy at the cost of growing GPU memory consumption, particularly for high-resolution (FullHD) inputs. We introduce MEMFOF, a memory-efficient multi-frame optical flow method that identifies a favorable trade-off between multi-frame estimation and GPU memory usage. Notably, MEMFOF requires only 2.09 GB of GPU memory at runtime for 1080p inputs, and 28.5 GB during training, which uniquely positions our method to be trained at native 1080p without the need for cropping or downsampling.We systematically revisit design choices from RAFT-like architectures, integrating reduced correlation volumes and high-resolution training protocols alongside multi-frame estimation, to achieve state-of-the-art performance across multiple benchmarks while substantially reducing memory overhead. Our method outperforms more resource-intensive alternatives in both accuracy and runtime efficiency, validating its robustness for flow estimation at high resolutions. At the time of submission, our method ranks first on the Spring benchmark with a 1-pixel (1px) outlier rate of 3.289. On Sintel (clean), we share first place with the 5-frame VideoFlow-MOF, achieving an endpoint error (EPE) of 0.991, and on KITTI-2015, we place first with an Fl-all error of 2.94\%. Ablation studies demonstrate the critical role of multi-frame strategies, correlation-volume scaling, and resolution-aware training in striking an optimal …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We present EventUPS, the first uncalibrated photometric stereo method using event cameras—neuromorphic sensors that asynchronously detect brightness changes with microsecond resolution. Frame-based uncalibrated photometric stereo methods imposed high bandwidth demands and limiting applicability in dynamic scenes. They require dense image correspondence under varying illumination, cannot be directly applicable due to event data due to their fundamentally different sensing paradigm. Our approach introduces three key innovations: i) an augmented null space formulation that directly relates each event to constraints on surface normals and lighting, naturally handling ambient illumination; ii) a continuous parameterization of time-varying illumination that bridges asynchronous events to synchronized lighting estimation; iii) a structured lighting approach with known relative geometry that resolves the ambiguity to merely convex-concave uncertainty. We validate EventUPS using a custom-built LED-based lighting system implementing dual-ring and trefoil curve patterns. Extensive experiments on synthetic, semi-real, and real data demonstrate that our method achieves accuracy surpassing frame-based counterpart while requiring only 5\% of the data bandwidth.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Person search aims to jointly perform person detection and re-identification by localizing and identifying a query person within a gallery of uncropped scene images. Existing methods predominantly utilize ImageNet pre-trained backbones, which may be less effective at capturing the contextual and fine-grained features crucial for person search. Moreover, they rely on a shared backbone feature for both person detection and re-identification, leading to suboptimal features due to conflicting optimization objectives. Recently, diffusion models have emerged as powerful vision backbones, capturing rich visual priors from large-scale datasets. In this paper, we propose DiffPS (Diffusion Prior Knowledge for Person Search), a novel framework that leverages a frozen pre-trained diffusion model while eliminating the optimization conflict between two sub-tasks. We analyze key properties of diffusion priors and propose three specialized modules: (i) Diffusion-Guided Region Proposal Network (DGRPN) for enhanced person localization, (ii) Multi-Scale Frequency Refinement Network (MSFRN) to mitigate shape bias, and (iii) Semantic-Adaptive Feature Aggregation Network (SFAN) to leverage text-aligned diffusion features. DiffPS sets a new state-of-the-art on CUHK-SYSU and PRW. Our code will be available online at the time of the publication.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Semi-supervised semantic segmentation has attracted considerable attention as it alleviates the need for extensive pixel-level annotations. However, existing methods often overlook the potential optimization conflict between supervised and unsupervised learning objectives, leading to suboptimal performance. In this paper, we identify this under-explored issue and propose a novel Pareto Optimization Strategy (POS) to tackle it. POS aims to find a descent gradient direction that benefits both learning objectives, thereby facilitating model training. By dynamically assigning weights to the gradients at each iteration based on the model's learning status, POS effectively reconciles the intrinsic tension between the two objectives. Furthermore, we analyze POS from the perspective of gradient descent in random batch sampling and propose the Magnitude Enhancement Operation (MEO) to further unleash its potential by considering both direction and magnitude during gradient integration. Extensive experiments on challenging benchmarks demonstrate that integrating POS into existing semi-supervised segmentation methods yields consistent improvements across different data splits and architectures (CNN, Transformer), showcasing its effectiveness.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Physically-based rendering (PBR) has become a cornerstone in modern computer graphics, enabling realistic material representation and lighting interactions in 3D scenes. In this paper, we present MaterialMVP, a novel end-to-end model for generating PBR textures from 3D meshes and image prompts, addressing key challenges in multi-view material synthesis. Our approach leverages Reference Attention to extract and encode informative latent from the input reference images, enabling intuitive and controllable texture generation. We also introduce a Consistency-Regularized Training strategy to enforce stability across varying viewpoints and illumination conditions, ensuring illumination-invariant and geometrically consistent results. Additionally, we propose Dual-Channel Material Generation, which separately optimizes albedo and metallic-roughness (MR) textures while maintaining precise spatial alignment with the input images through Multi-Channel Aligned Attention. Learnable material embeddings are further integrated to capture the distinct properties of albedo and MR. Experimental results demonstrate that our model generates PBR textures with realistic behavior across diverse lighting scenarios, outperforming existing methods in both consistency and quality for scalable 3D asset creation.
|
|
Highlight
|
Poster
Ranran Huang · Krystian Mikolajczyk
Exhibit Hall I

Abstract
We introduce SPFSplat, an efficient framework for 3D Gaussian Splatting from sparse multi-view images, requiring no ground-truth poses during both training and inference. Our method simultaneously predicts Gaussians and camera poses from unposed images in a canonical space within a single feed-forward step. During training, the pose head estimate the poses at target views, which are supervised through the image rendering loss. Additionally, a reprojection loss is introduced to ensure alignment between Gaussians and the estimated poses of input views, reinforcing geometric consistency. This pose-free training paradigm and efficient one-step feed-forward inference makes SPFSplat well-suited for practical applications. Despite the absence of pose supervision, our self-supervised SPFSplat achieves state-of-the-art performance in novel view synthesis, even under significant viewpoint changes. Furthermore, it surpasses recent methods trained with geometry priors in relative pose estimation, demonstrating its effectiveness in both 3D scene reconstruction and camera pose learning.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 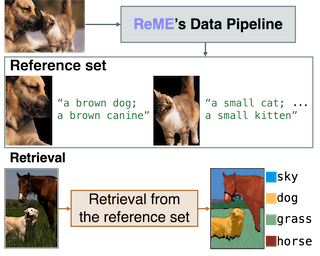
Abstract
Training-free open-vocabulary semantic segmentation (OVS) aims to segment images given a set of arbitrary textual categories without costly model fine-tuning. Existing solutions often explore attention mechanisms of pre-trained models, such as CLIP, or generate synthetic data and design complex retrieval processes to perform OVS. However, their performance is limited by the capability of reliant models or the suboptimal quality of reference sets. In this work, we investigate the largely overlooked data quality problem for this challenging dense scene understanding task, and identify that a high-quality reference set can significantly benefit training-free OVS. With this observation, we introduce a data-quality-oriented framework, comprising a data pipeline to construct a reference set with well-paired segment-text embeddings and a simple similarity-based retrieval to unveil the essential effect of data. Remarkably, extensive evaluations on ten benchmark datasets demonstrate that our method outperforms all existing training-free OVS approaches, highlighting the importance of data-centric design for advancing OVS without training.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Spatial intelligence is emerging as a transformative frontier in AI, yet it remains constrained by the scarcity of large-scale 3D datasets. Unlike the abundant 2D imagery, acquiring 3D data typically requires specialized sensors and laborious annotation. In this work, we present a scalable pipeline that converts single-view images into comprehensive, scale- and appearance-realistic 3D representations — including point clouds, camera poses, depth maps, and pseudo-RGBD — via integrated depth estimation, camera calibration, and scale calibration. Our method bridges the gap between the vast repository of imagery and the increasing demand for spatial scene understanding. By automatically generating authentic, scale-aware 3D data from images, we significantly reduce data collection costs and open new avenues for advancing spatial intelligence. We release multiple generated spatial datasets, i.e., COCO-3D and Objects365-v2-3D, and demonstrate through extensive experiments that our generated data can benefit various spatial tasks, ranging from basic perception to MLLM-based reasoning. These results validate our pipeline as an effective solution for developing AI systems capable of perceiving, understanding, and interacting with physical environments.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Knowledge distillation (KD) aims to transfer the knowledge of a more capable yet cumbersome teacher model to a lightweight student model. In recent years, relation-based KD methods have fallen behind, as instance-matching counterparts dominate in performance. In this paper, we revive relational KD by identifying and tackling several key issues in relational KD, including its susceptibility to overfitting and spurious responses. Specifically, we transfer novelly constructed affinity graphs that compactly encapsulate a wealth of beneficial inter-sample, inter-class, and inter-view correlations by exploiting virtual views and relations as a new kind of knowledge. As a result, the student has access to rich guidance signals and stronger regularisation throughout the distillation process. To further mitigate the adverse impact of spurious responses, we prune the affinity graphs by dynamically detaching redundant and unreliable edges. Extensive experiments on CIFAR-100, ImageNet, and MS-COCO datasets demonstrate the superior performance of the proposed virtual relation matching (VRM) method over a range of tasks, architectures, and set-ups. For instance, VRM for the first time hits 74.0% accuracy for ResNet50-to-MobileNetV2 distillation on ImageNet, and improves DeiT-Ti by 14.44% on CIFAR-100 with a ResNet56 teacher. Code and models will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Astronomical telescopes suffer from a tradeoff between field-of-view (FoV) and image resolution: increasing the FoV leads to an optical field that is under-sampled by the science camera. This work presents a novel computational imaging approach to overcome this tradeoff by leveraging the existing adaptive optics (AO) systems in modern ground-based telescopes. Our key idea is to use the AO system’s deformable mirror to apply a series of learned, precisely controlled distortions to the optical wavefront, producing a sequence of images that exhibit distinct, high-frequency, sub-pixel shifts. These images can then be jointly upsampled to yield the final super-resolved image. Crucially, we show this can be done while simultaneously maintaining the core AO operation --- correcting for the unknown and rapidly changing wavefront distortions caused by Earth's atmosphere. To achieve this, we incorporate end-to-end optimization of both the induced mirror distortions and the upsampling algorithm, such that telescope-specific optics and temporal statistics of atmospheric wavefront distortions are accounted for. Our experimental results with a hardware prototype, as well as simulations, demonstrate significant SNR improvements of up to 12 dB over non-AO super-resolution baselines, using only existing telescope optics and no hardware modifications. Moreover, by using a precise bench-top replica of a …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Precise 6-DoF simultaneous localization and mapping (SLAM) from onboard sensors is critical for wearable devices capturing egocentric data, which exhibits specific challenges, such as a wider diversity of motions and viewpoints, prevalent dynamic visual content, or long sessions affected by time-varying sensor calibration. While recent progress on SLAM has been swift, academic research is still driven by benchmarks that do not reflect these challenges or do not offer sufficiently accurate ground truth poses. In this paper, we introduce a new dataset and benchmark for visual-inertial SLAM with egocentric, multi-modal data. We record hours and kilometers of trajectories through a city center with glasses-like devices equipped with various sensors. We leverage surveying tools to obtain control points as indirect pose annotations that are metric, centimeter-accurate, and available at city scale. This makes it possible to evaluate extreme trajectories that involve walking at night or traveling in a vehicle. We show that state-of-the-art systems developed by academia are not robust to these challenges and we identify components that are responsible for this. In addition, we design tracks with different levels of difficulty to ease in-depth analysis and evaluation of less mature approaches. The dataset and benchmark will be made publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 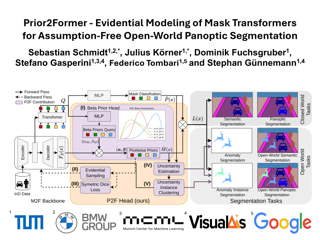
Abstract
In panoptic segmentation, individual instances must be separated within semantic classes. As state-of-the-art methods rely on a pre-defined set of classes, they struggle with novel categories and out-of-distribution (OOD) data. This is particularly problematic in safety-critical applications, such as autonomous driving, where reliability in unseen scenarios is essential. We address the gap between outstanding benchmark performance and reliability by proposing Prior2Former(P2F), the first approach for segmentation vision transformers rooted in evidential learning. P2F extends the mask vision transformer architecture by incorporating a Beta prior for computing model uncertainty in pixel-wise binary mask assignments. This design enables high-quality uncertainty estimation that effectively detects novel and OOD objects enabling state-of-the-art anomaly instance segmentation and open-world panoptic segmentation. Unlike most segmentation models addressing unknown classes, P2F operates without access to OOD data samples or contrastive training on void (i.e., unlabeled) classes, making it highly applicable in real-world scenarios where such prior information is unavailable. Additionally, P2F can be flexibly applied to anomaly instance and panoptic segmentation.Through comprehensive experiments on the Cityscapes, COCO, SegmentMeIfYouCan, and OoDIS datasets, we demonstrate the state-of-the-art performance of P2F. It achieves the highest ranking in the OoDIS anomaly instance benchmark among methods not using OOD data in any way.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Neural surface reconstruction faces critical challenges in achieving geometrically accurate and visually coherent results under complex real-world conditions. We present a unified framework that simultaneously resolves multi-view radiance inconsistencies, enhances low-textured surface recovery, and preserves fine structural details through three fundamental innovations. First, our SDF-guided visibility factor $\mathbb{V}$ establishes continuous occlusion reasoning to eliminate reflection-induced ambiguities in multi-view supervision. Second, we introduce local geometry constraints via ray-aligned patch analysis $\mathbb{P}$, enforcing planarity in textureless regions while maintaining edge sensitivity through adaptive feature weighting. Third, we reformulate Eikonal regularization with rendering-prioritized relaxation, enabling detail preservation by conditioning geometric smoothness on local radiance variations. Unlike prior works that address these aspects in isolation, our method achieves synergistic optimization where multi-view consistency, surface regularity, and structural fidelity mutually reinforce without compromise. Extensive experiments across synthetic and real-world datasets demonstrate state-of-the-art performance, with quantitative improvements of 21.4\% in Chamfer distance over reflection-aware baselines and 2.32 dB PSNR gains against neural rendering counterparts. Qualitative results showcase unprecedented reconstruction quality for challenging cases including specular instruments, urban layouts with thin structures, and Lambertian surfaces with sub-millimeter details. Our code will be publicly released to facilitate research in unified neural surface recovery.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 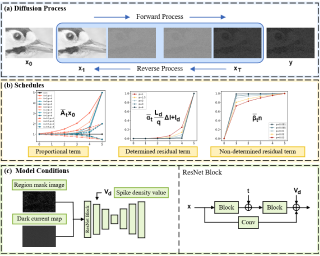
Abstract
Spike-based imaging, inspired by the human visual system, offers several advantages, including high temporal resolution and low power consumption, but suffers from significant image degradation in low-light conditions due to noise interference. Restoring spike images under such conditions poses a significant challenge, as traditional frame-based or spike-based techniques are ill-suited to handle such severe noise and unique noise characteristics. This paper proposes a novel approach for restoring low-light spike images using noise-modeled diffusion models. By establishing a noise-embedded spike imaging model under low light, we model the forward diffusion process as the degradation of spike images with proportional and residual terms and incorporate determinstic and non-determinstic components with reverse shifting, enabling the model to capture the distinctive spike noise structure. Additionally, we utilize region mask image, dark current map and spike density value as conditions to further guide the restoration process by providing prompts for degradation regions, deterministic parameters and noise intensity. Experimental results demonstrate that our method significantly outperforms existing spike-based reconstruction and diffusion-based image restoration methods in both quantitative performance and visual qualityThis work opens new possibilities for spike-based imaging systems, particularly in low-light environments, and lays the groundwork for future developments in spike image restoration using advanced …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Generating natural and physically plausible character motion remains challenging, particularly for long-horizon control with diverse guidance signals. While prior work combines high-level diffusion-based motion planners with low-level physics controllers, these systems suffer from domain gaps that degrade motion quality and require task-specific fine-tuning.To tackle this problem, we introduce UniPhys, a diffusion-based behavior cloning framework that unifies motion planning and control into a single model. UniPhys enables flexible, expressive character motion conditioned on multi-modal inputs such as text, trajectories, and goals. To address accumulated prediction errors over long sequences, UniPhys is trained with the Diffusion Forcing paradigm, learning to denoise noisy motion histories and handle discrepancies introduced by the physics simulator. This design allows UniPhys to robustly generate physically plausible, long-horizon motions. Through guided sampling, UniPhys generalizes to a wide range of control signals, including unseen ones, without requiring task-specific fine-tuning. Experiments show that UniPhys outperforms prior methods in motion naturalness, generalization, and robustness across diverse control tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We address the problem of few-shot pattern detection, which aims to detect all instances of a given pattern, typically represented by a few exemplars, from an input image.Although similar problems have been studied in few-shot object counting and detection (FSCD), previous methods and their benchmarks have narrowed patterns of interest to object categories and often fail to localize non-object patterns. In this work, we propose a simple yet effective detector based on template matching and regression, dubbed \ours.While previous FSCD methods typically represent given target exemplars into a spatially collapsed prototype, we revisit classic template matching and regression. It effectively preserves and leverages the spatial layout of exemplars in our minimalistic architecture, which consists of a few learnable layers of either convolutions or projections.We also introduce a new dataset, dubbed RPINE, which covers a wider range of patterns than existing object-centric datasets.Experiments on three benchmarks, RPINE, FSCD-147, FSCD-LVIS, demonstrate that our method outperforms recent state-of-the-art methods, showing an outstanding generalization ability on cross-dataset evaluation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 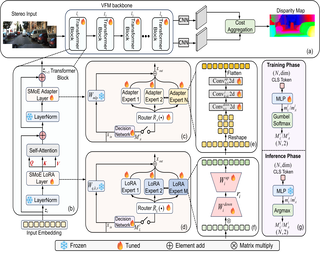
Abstract
Recently, learning-based stereo matching networks have advanced significantly.However, they often lack robustness and struggle to achieve impressive cross-domain performance due to domain shifts and imbalanced disparity distributions among diverse datasets.Leveraging Vision Foundation Models (VFMs) can intuitively enhance the model's robustness, but integrating such a model into stereo matching cost-effectively to fully realize their robustness remains a key challenge.To address this, we propose SMoEStereo, a novel framework that adapts VFMs for stereo matching through a tailored, scene-specific fusion of Low-Rank Adaptation (LoRA) and Mixture-of-Experts (MoE) modules.SMoEStereo introduces MoE-LoRA with adaptive ranks and MoE-Adapter with adaptive kernel sizes. The former dynamically selects optimal experts within MoE to adapt varying scenes across domains, while the latter injects inductive bias into frozen VFMs to improve geometric feature extraction.Importantly, to mitigate computational overhead, we further propose a lightweight decision network that selectively activates MoE modules based on input complexity, balancing efficiency with accuracy. Extensive experiments demonstrate that our method exhibits state-of-the-art cross-domain and joint generalization across multiple benchmarks without dataset-specific adaptation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Reconstructing clothed humans from a single image is a fundamental task in computer vision with wide-ranging applications. Although existing monocular clothed human reconstruction solutions have shown promising results, they often rely on the assumption that the human subject is in an occlusion-free environment. Thus, when encountering in-the-wild occluded images, these algorithms produce multiview inconsistent and fragmented reconstructions. Additionally, most algorithms for monocular 3D human reconstruction leverage geometric priors such as SMPL annotations for training and inference, which are extremely challenging to acquire in real-world applications. To address these limitations, we propose CHROME: Clothed Human Reconstruction with Occlusion-Resilience and Multiview-ConsistEncy from a Single Image, a novel pipeline designed to reconstruct occlusion-resilient 3D humans with multiview consistency from a single occluded image, without requiring either ground-truth geometric prior annotations or 3D supervision. Specifically, CHROME leverages a multiview diffusion model to first synthesize occlusion-free human images from the occluded input, compatible with off-the-shelf pose control to explicitly enforce cross-view consistency during synthesis. A 3D reconstruction model is then trained to predict a set of 3D Gaussians conditioned on both the occluded input and synthesized views, aligning cross-view details to produce a cohesive and accurate 3D representation. CHROME achieves significant improvements in terms of …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We propose a novel approach for long-term autoregressive scene generation in the form of a camera-conditioned video stream.Existing methods either rely on explicit geometry estimation in inpainting-based approaches, which suffer from geometric inaccuracies, or use a limited context window in video-based approaches, which struggle with long-term coherence.To address these limitations, we introduce Surfel-Indexed Memory of Views (SIMView), a mechanism that anchors past views to surface elements (surfels) they previously observed.This allows us to retrieve and condition novel view generation on the most relevant past views rather than just the latest ones.By leveraging information about the scene's geometric structure, our method significantly enhances long-term scene consistency while reducing computational overhead.We evaluate our approach on challenging long-term scene synthesis benchmarks, demonstrating superior performance in scene coherence and camera control compared to existing methods.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
As the core operator of Transformers, Softmax Attention exhibits excellent global modeling capabilities. However, its quadratic complexity limits its applicability to vision tasks. In contrast, Linear Attention shares a similar formulation with Softmax Attention while achieving linear complexity, enabling efficient global information modeling. Nevertheless, Linear Attention suffers from a significant performance degradation compared to standard Softmax Attention. In this paper, we analyze the underlying causes of this issue based on the formulation of Linear Attention. We find that, unlike Softmax Attention, Linear Attention entirely disregards the magnitude information of the Query($Q$ or $\phi(Q)$). The absence of magnitude information prevents the attention score distribution from dynamically adapting as the Query scales. As a result, despite its structural similarity to Softmax Attention, Linear Attention exhibits a significantly different attention score distribution. Based on this observation, we propose **Magnitude-Aware Linear Attention** (MALA), which modifies the computation of Linear Attention to fully incorporate the Query’s magnitude. This adjustment allows MALA to generate an attention score distribution that closely resembles Softmax Attention while exhibiting a more well-balanced structure. As a result, MALA surpasses Softmax Attention in performance while maintaining only linear complexity. We build Magnitude-Aware Vision Transformer (MAViT) based on MALA, achieving **84.7%** accuracy on …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper introduces Stereo Any Video, a powerful framework for video stereo matching. It can estimate spatially accurate and temporally consistent disparities without relying on auxiliary information such as camera poses or optical flow. The strong capability is driven by rich priors from monocular video depth models, which are integrated with convolutional features to produce stable representations. To further enhance performance, key architectural innovations are introduced: all-to-all-pairs correlation, which constructs smooth and robust matching cost volumes, and temporal convex upsampling, which improves temporal coherence. These components collectively ensure robustness, accuracy, and temporal consistency, setting a new standard in video stereo matching. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple datasets both qualitatively and quantitatively in zero-shot settings, as well as strong generalization to real-world indoor and outdoor scenarios. Code and models will be publicly released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We propose PRM, a novel photometric stereo based large reconstruction model to reconstruct high-quality meshes with fine-grained details. Previous large reconstruction models typically prepare training images under fixed and simple lighting, offering minimal photometric cues for precise reconstruction. Furthermore, images containing specular surfaces are treated as out-of-distribution samples, resulting in degraded reconstruction quality. To handle these challenges, PRM renders photometric stereo images by varying materials and lighting, which not only improves the local details by providing rich photometric cues but also increases the model’s robustness to variations in the appearance of input images. To offer enhanced flexibility, we incorporate a real-time physically-based rendering (PBR) method and mesh rasterization for ground-truth rendering. By using an explicit mesh as 3D representation, PRM ensures the application of differentiable PBR for predicted rendering. This approach models specular color more accurately for photometric stereo images than previous neural rendering methods and supports multiple supervisions for geometry optimization. Extensive experiments demonstrate that PRM significantly outperforms other models.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Standard clothing asset generation involves restoring forward-facing flat-lay garment images displayed on a clear background by extracting clothing information from diverse real-world contexts, which presents significant challenges due to highly standardized structure sampling distributions and clothing semantic absence in complex scenarios. Existing models have limited spatial perception, often exhibiting structural hallucinations and texture distortion in this high-specification generative task. To address this issue, we propose a novel Retrieval-Augmented Generation (RAG) framework, termed RAGDiffusion, to enhance structure determinacy and mitigate hallucinations by assimilating knowledge from language models and external databases. RAGDiffusion consists of two processes: (1) Retrieval-based structure aggregation, which employs contrastive learning and a Structure Locally Linear Embedding (SLLE) to derive global structure and spatial landmarks, providing both soft and hard guidance to counteract structural ambiguities; and (2) Omni-level faithful garment generation, which introduces a coarse-to-fine texture alignment that ensures fidelity in pattern and detail components within the diffusing. Extensive experiments on challenging real-world datasets demonstrate that RAGDiffusion synthesizes structurally and texture-faithful clothing assets with significant performance improvements, representing a pioneering effort in high-specification faithful generation with RAG to confront intrinsic hallucinations and enhance fidelity.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Vision benefits from grouping pixels into objects and understanding their spatial relationships, both laterally and in depth. This is captured by a scene representation comprising of an occlusion-ordered stack of "object layers,’’ each containing an isolated and amodally-completed object. To infer this representation from an image we introduce a diffusion-based architecture named Concurrent Object Layers (CObL). CObL generates a stack of object layers concurrently, using Stable Diffusion as a prior for natural objects, and using inference-time guidance to ensure the inferred layers composite back to the input image. We train CObL using a few thousand synthetically-generated images of multi-object tabletop scenes, and we find that it zero-shot generalizes to scenes of real-world tabletops with varying numbers of novel objects. In contrast to recent models for amodal object completion, CObL reconstructs multiple partially-occluded objects without any user prompting and without knowing the number of objects beforehand; and unlike previous models for object-centric representation learning, CObL is not limited to the closed world it was trained in.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Text-driven image generation using diffusion models has recently gained significant attention. To enable more flexible image manipulation and editing, recent research has expanded from single image generation to transparent layer generation and multi-layer compositions. However, existing approaches often fail to provide a thorough exploration of multi-layer structures, leading to inconsistent inter-layer interactions, such as occlusion relationships, spatial layout, and shadowing. In this paper, we introduce DreamLayer, a novel framework that enables coherent text-driven generation of multiple image layers, by explicitly modeling the relationship between transparent foreground and background layers. DreamLayer incorporates three key components, i.e., Context-Aware Cross-Attention (CACA) for global-local information exchange, Layer-Shared Self-Attention (LSSA) for establishing robust inter-layer connections, and Information Retained Harmonization (IRH) for refining fusion details at the latent level.By leveraging a coherent full-image context, DreamLayer builds inter-layer connections through attention mechanisms and applies a harmonization step to achieve seamless layer fusion. To facilitate research in multi-layer generation, we construct a high-quality, diverse multi-layer dataset including $400k$ samples. Extensive experiments and user studies demonstrate that DreamLayer generates more coherent and well-aligned layers, with broad applicability, including latent-space image editing and image-to-layer decomposition.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Metalenses offer significant potential for ultra-compact computational imaging but face challenges from complex optical degradation and computational restoration difficulties. Existing methods typically rely on precise optical calibration or massive paired datasets, which are non-trivial for real-world imaging systems. Furthermore, lack of control over the inference process often results in undesirable hallucinated artifacts. We introduce Degradation-Modeled Multipath Diffusion for tunable metalens photography, leveraging powerful natural image priors from pretrained models instead of large datasets. Our framework uses positive, neutral, and negative-prompt paths to balance high-frequency detail generation, structural fidelity, and suppression of metalens-specific degradation, alongside pseudo data augmentation. A tunable decoder enables controlled trade-offs between fidelity and perceptual quality. Additionally, a spatially varying degradation-aware attention (SVDA) module adaptively models complex optical and sensor-induced degradation. Finally, we design and build a millimeter-scale MetaCamera for real-world validation. Extensive results show that our approach outperforms state-of-the-art methods, achieving high-fidelity and sharp image reconstruction. More materials: https://dmdiff.github.io/.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Effective video tokenization is critical for scaling transformer models for long videos. Current approaches tokenize videos using space-time patches, leading to excessive tokens and computational inefficiencies. The best token reduction strategies degrade performance and barely reduce the number of tokens when the camera moves. We introduce grounded video tokenization, a paradigm that organizes tokens based on panoptic sub-object trajectories rather than fixed patches. Our method aligns with fundamental perceptual principles, ensuring that tokenization reflects scene complexity rather than video duration. We propose TrajViT, a video encoder that extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence. Trained with contrastive learning, TrajViT significantly outperforms space-time ViT (ViT3D) across multiple video understanding benchmarks, e.g., TrajViT outperforms ViT3D by a large margin of 6% top-5 recall in average at video-text retrieval task with 10x token deduction. We also show TrajViT as a stronger model than ViT3D for being the video encoder for modern VideoLLM, obtaining an average of 5.2% performance improvement across 6 VideoQA benchmarks while having 4x faster training time and 20x less inference FLOPs. TrajViT is the first efficient encoder to consistently outperform ViT3D across diverse video analysis tasks, making it a robust …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Extracting physically plausible 3D human motion from videos is a critical task. Although existing simulation-based motion imitation methods can enhance the physical quality of daily motions estimated from monocular video capture, extending this capability to high-difficulty motions remains an open challenge. This can be attributed to some flawed motion clips in video-based motion capture results and the inherent complexity in modeling high-difficulty motions. Therefore, sensing the advantage of segmentation in localizing human body, we introduce a mask-based motion correction module (MCM) that leverages motion context and video mask to repair flawed motions; and propose a physics-based motion transfer module (PTM), which employs a prior injected pretrain and adapt approach for motion imitation, improving physical plausibility with the ability to handle in-the-wild and challenging motions. Our approach is designed as a plug-and-play module to physically refine the video motion capture, which also excels in motion generation tasks. Finally, we collected a challenging in-the-wild test set to establish a benchmark, and our method has demonstrated effectiveness on both the new benchmark and existing public datasets. Our project page is : https://physicalmotionrestoration.github.io/
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 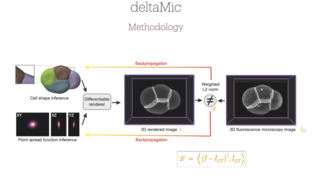
Abstract
Traditional methods for biological shape inference, such as deep learning (DL) and active contour models, face limitations in 3D. DL requires large labeled datasets, which are difficult to obtain, while active contour models rely on fine-tuned hyperparameters for intensity attraction and regularization. We introduce deltaMic, a novel 3D differentiable renderer for fluorescence microscopy. By leveraging differentiable Fourier-space convolution, deltaMic accurately models the image formation process, integrating a parameterized microscope point spread function and a mesh-based object representation. Unlike DL-based segmentation, it directly optimizes shape and microscopy parameters to fit real microscopy data, removing the need for large datasets or heuristic priors. To enhance efficiency, we develop a GPU-accelerated Fourier transform for triangle meshes, significantly improving speed. We demonstrate deltaMic’s ability to reconstruct cellular shapes from synthetic and real microscopy images, providing a robust tool for 3D segmentation and biophysical modeling. This work bridges physics-based rendering with modern optimization techniques, offering a new paradigm for microscopy image analysis and inverse biophysical modeling.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Text-Video Retrieval has been extensively studied to accurately retrieve the most relevant text (or video) candidate given a video (or text) query from large-scale online databases. With the advancement of multi-modal large language models (MLLMs), recent studies have proposed MLLM-based retrieval systems to enhance retrieval performance, particularly for long and complex query-candidate pairs. However, we observe that the naive application of MLLMs, $\textit{i.e.}$, retrieval based on candidate likelihood, introduces $\textit{candidate prior bias}$, wherein candidates with inherently higher prior probabilities are favored over those that are more relevant to the query. To this end, we propose a novel retrieval framework, Bidirectional Likelihood Estimation with MLLM ($\textbf{BLiM}$), which leverages query likelihood as well as candidate likelihood by training the model to generate text from a given video as well as video features from a given text. Furthermore, we introduce Candidate Prior Normalization ($\textbf{CPN}$), a simple yet effective training-free score calibration module designed to mitigate candidate prior bias in candidate likelihood. On four Text-Video Retrieval benchmarks, our BLiM equipped with CPN outperforms previous state-of-the-art models by an average margin of 6.4 in R@1, effectively alleviating candidate prior bias and emphasizing the relevance between the query and candidate. Our in-depth analysis across various multi-modal …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
As large models begin to gain momentum, vision-language foundation models are enabling robots to generalizably perform more and more tasks. However, due to the difficulty in data collection, the benefits are limited with simple embodiments. In this paper, we present \textbf{DexVLG}, a vision-language model that predicts language instruction-aligned dexterous grasp poses given single-view RGBD perception. To achieve this, we first synthesize a dataset of 170M dexterous grasp poses aligned with semantic parts on 174k objects in simulation, paired with informative part-level captions. With this large-scale dataset named \textbf{DexGraspNet 3.0}, we train a flow-matching VLM to generate instruction-aligned grasp poses on tabletop objects. To evaluate DexVLG, we curate benchmarks in physics-based simulation and perform real-world experiments. Our extensive experiments demonstrate DexVLG's great zero-shot generalizability, achieving over 76\% zero-shot execution success rate and state-of-the art part grasp accuracy in simulation, and demonstrate successful part-aligned grasps on real-world objects.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We propose a method for affine rectification of an image plane by leveraging changes in local scales and orientations under projective distortion. Specifically, we derive a novel linear constraint that directly relates pairs of points with orientations to the parameters of a projective transformation. This constraint is combined with an existing linear constraint on local scales, leading to highly robust rectification. The method reduces to solving a system of linear equations, enabling an efficient algebraic least-squares solution. It requires only two local scales and two local orientations, which can be extracted from, e.g., SIFT features. Unlike prior approaches, our method does not impose restrictions on individual features, does not require class segmentation, and makes no assumptions about feature interrelations. It is compatible with any feature detector that provides local scale or orientation. Furthermore, combining scaled and oriented points with line segments yields a highly robust algorithm that outperforms baselines. Extensive experiments show the effectiveness of our approach on real-world images, including repetitive patterns, building facades, and text-based content.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Large field-of-view (FOV) cameras can simplify and accelerate scene capture because they provide complete coverage with fewer views. However, existing reconstruction pipelines fail to take full advantage of large-FOV input data because they convert input views to perspective images, resulting in stretching that prevents the use of the full image. Additionally, they calibrate lenses using models that do not accurately fit real fisheye lenses in the periphery. We present a new reconstruction pipeline based on Gaussian Splatting that uses a flexible lens model and supports fields of view approaching 180 degrees. We represent lens distortion with a hybrid neural field based on an Invertible ResNet and use a cubemap to render wide-FOV images while retaining the efficiency of the Gaussian Splatting pipeline. Our system jointly optimizes lens distortion, camera intrinsics, camera poses, and scene representations using a loss measured directly against the original input pixels. We present extensive experiments on both synthetic and real-world scenes, demonstrating that our model accurately fits real-world fisheye lenses and that our end-to-end self-calibration approach provides higher-quality reconstructions than existing methods.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The continuous development of foundational models for video generation is evolving into various applications, with subject-consistent video generation still in the exploratory stage. We refer to this as Subject-to-Video, which extracts subject elements from reference images and generates subject-consistent videos following textual instructions. We believe that the essence of subject-to-video lies in balancing the dual-modal prompts of text and image, thereby deeply and simultaneously aligning both text and visual content. To this end, we propose Phantom, a unified video generation framework for both single- and multi-subject references.Building on existing text-to-video and image-to-video architectures, we redesign the joint text-image injection model and drive it to learn cross-modal alignment via text-image-video triplet data. The proposed method achieves perfect subject-consistent video generation while addressing issues of image content leakage and multi-subject confusion.Evaluation results indicate that our method outperforms other state-of-the-art closed-source commercial solutions.In particular, we emphasize subject consistency in human generation, covering existing ID-preserving video generation while offering enhanced advantages.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
The vision towers of Multimodal Language Models (MLLM) have significantly enhanced the performance of large multimodal models. This success is primarily attributed to extensive language alignment training, which enhances human-like understanding. However, these models predominantly rely on global category representations, limiting their performance in tasks that require localized representations, such as grounding, OCR, and segmentation. To address this limitation, we propose a novel Locality-Aware Cluster Contrastive Learning strategy. Our approach leverages local feature clustering and contrastive learning to improve the model's ability to understand and represent localized information. Furthermore, our method can be easily scaled to billion-level training, ensuring its applicability to large-scale datasets and models. We demonstrate the effectiveness of our method by achieving state-of-the-art results on the Visual Question Answering (VQA) and RefCOCO benchmarks, showcasing its superior capabilities in handling tasks that require fine-grained visual understanding. Our results indicate a significant improvement in performance, validating the potential of our approach in advancing MLLM tasks. It outperforms the widely used SigLIP.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Parametric human body models play a crucial role in computer graphics and vision, enabling applications ranging from human motion analysis to understanding human-environment interactions. Traditionally, these models use surface meshes, which pose challenges in efficiently handling interactions with other geometric entities, such as objects and scenes, typically represented as meshes or point clouds. To address this limitation, recent research has explored volumetric neural implicit body models. However, existing works are either insufficiently robust for complex human articulations or impose high computational and memory costs, limiting their widespread use. To this end, we introduce VolumetricSMPL, a neural volumetric body model that leverages Neural Blend Weights (NBW) to generate compact, yet efficient MLP decoders. Unlike prior approaches that rely on large MLPs, NBW dynamically blends a small set of learned weight matrices using predicted shape- and pose-dependent coefficients, significantly improving computational efficiency while preserving expressiveness. VolumetricSMPL outperforms prior volumetric occupancy model COAP with 10× faster inference, 6× lower GPU memory usage, enhanced accuracy, and a Signed Distance Function (SDF) for efficient and differentiable contact modeling. We demonstrate VolumetricSMPL’s strengths across four challenging tasks: (1) reconstructing human-object interactions from in-the-wild images, (2) recovering human meshes in 3D scenes from egocentric views, (3) scene-constrained …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 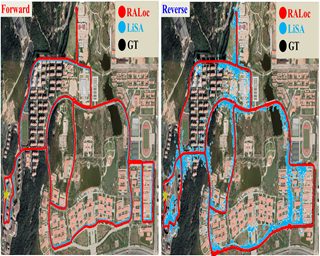
Abstract
LiDAR localization is a fundamental task in autonomous driving and robotics. Scene Coordinate Regression (SCR) exhibits leading pose accuracy, achieving impressive results in learning-based localization. We observe that the real-world LiDAR scans captured from different viewpoints usually result in the catastrophic collapse of SCR. However, existing LiDAR localization methods have largely overlooked the issue of rotation sensitivity in SCR. In this paper, we present RALoc, an outdoor LiDAR localization method with rotation awareness to achieve accurate localization. The key to our approach is to design a Point Cloud Canonicalization module, which leverages a powerful equivariant key feature aggregation to transform the input LiDAR scan towards a consistent orientation, effectively eliminating the adverse effects of rotation. This proposed module has promising scalability and can be seamlessly integrated with the existing LiDAR localization network. Moreover, we propose the $\textbf{Bi}$directional $\textbf{Li}$DAR $\textbf{Lo}$calization (BiLiLo) dataset as a benchmark to evaluate the performance of various methods in large outdoor scenes with significant rotation changes. Extensive experiments show that RALoc significantly improves localization performance in scenarios with large rotation changes, and also achieves competitive performance in the Oxford Radar RobotCar dataset. Our code and dataset will be released upon acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 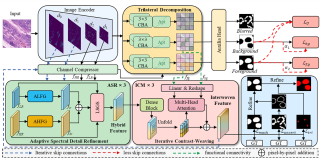
Abstract
histopathology images is a fundamental task in computational pathology. It is also a very challenging task due to complex nuclei morphologies, ambiguous boundaries, and staining variations. Existing methods often struggle to precisely delineate overlapping nuclei and handle class imbalance. We introduce WeaveSeg, a novel deep learning model for nuclei instance segmentation that significantly improves segmentation performance via synergistic integration of adaptive spectral feature refinement and iterative contrast-weaving. WeaveSeg features an adaptive spectral detail refinement (SAR) module for multi-scale feature enhancement via adaptive frequency component fusion, and an iterative contrast-weaving (ICW) module that progressively refines features through integrating contrastive attention, decoupled semantic context, and adaptive gating. Furthermore, we introduce a specialized uncertainty loss to explicitly model ambiguous regions, and a novel local contrast-based self-adaptive adjustment mechanism to accommodate dynamic feature distributions. Extensive experiments on MoNuSeg and CoNSeP demonstrate WeaveSeg's SOTA performance over existing models. Code will be publicly available.
|
|
Highlight
|
Poster
Siyuan Yan · Ming Hu · Yiwen Jiang · Xieji Li · Hao Fei · Philipp Tschandl · Harald Kittler · Zongyuan Ge
Exhibit Hall I

Abstract
The emergence of vision-language models has transformed medical AI, enabling unprecedented advances in diagnostic capability and clinical applications. However, progress in dermatology has lagged behind other medical domains due to the lack of standard image-text pairs. Existing dermatological datasets are limited in both scale and depth, offering only single-label annotations across a narrow range of diseases instead of rich textual descriptions, and lacking the crucial clinical context needed for real-world applications. To address these limitations, we present Derm1M, the first large-scale vision-language dataset for dermatology, comprising 1,029,761 image-text pairs. Built from diverse educational resources and structured around a standard ontology collaboratively developed by experts, Derm1M provides comprehensive coverage for over 390 skin conditions across four hierarchical levels and 130 clinical concepts with rich contextual information such as medical history, symptoms, and skin tone. To demonstrate Derm1M’s potential in advancing both AI research and clinical application, we pretrained a series of …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
3D reconstruction and simulation, although interrelated, have distinct objectives: reconstruction requires a flexible 3D representation that can adapt to diverse scenes, while simulation needs a structured representation to model motion principles effectively. This paper introduces the Mesh-adsorbed Gaussian Splatting (MaGS) method to address this challenge. MaGS constrains 3D Gaussians to roam near the mesh, creating a mutually adsorbed mesh-Gaussian 3D representation. Such representation harnesses both the rendering flexibility of 3D Gaussians and the structured property of meshes. To achieve this, we introduce RMD-Net, a network that learns motion priors from video data to refine mesh deformations, alongside RGD-Net, which models the relative displacement between the mesh and Gaussians to enhance rendering fidelity under mesh constraints. To generalize to novel, user-defined deformations beyond input video without reliance on temporal data, we propose MPE-Net, which leverages inherent mesh information to bootstrap RMD-Net and RGD-Net. Due to the universality of meshes, MaGS is compatible with various deformation priors such as ARAP, SMPL, and soft physics simulation. Extensive experiments on the D-NeRF, DG-Mesh, and PeopleSnapshot datasets demonstrate that MaGS achieves state-of-the-art performance in both reconstruction and simulation.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 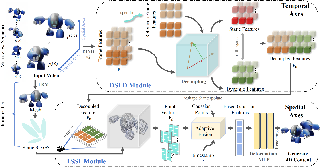
Abstract
Recently, the generation of dynamic 3D objects from a video has shown impressive results. Existing methods directly optimize Gaussians using whole information in frames. However, when dynamic regions are interwoven with static regions within frames, particularly if the static regions account for a large proportion, existing methods often overlook information in dynamic regions and are prone to overfitting on static regions. This leads to producing results with blurry textures. We consider that decoupling dynamic-static features to enhance dynamic representations can alleviate this issue. Thus, we propose a dynamic-static feature decoupling module (DSFD). Along temporal axes, it regards the regions of current frame features that possess significant differences relative to reference frame features as dynamic features. Conversely, the remaining parts are the static features. Then, we acquire decoupled features driven by dynamic features and current frame features. Moreover, to further enhance the dynamic representation of decoupled features from different viewpoints and ensure accurate motion prediction, we design a temporal-spatial similarity fusion module (TSSF). Along spatial axes, it adaptively selects similar information of dynamic regions. Hinging on the above, we construct a novel approach, DS4D. Experimental results verify our method achieves state-of-the-art (SOTA) results in video-to-4D. In addition, the experiments on a …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
A versatile video depth estimation model should be consistent and accurate across frames, produce high-resolution depth maps, and support real-time streaming. We propose a method, FlashDepth, that satisfies all three requirements, performing depth estimation for a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We validate our approach across multiple unseen datasets against state-of-the-art depth models, and find that our method outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as visual effects editing, and online decision-making, such as robotics.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Event-based keypoint detection and matching holds significant potential, enabling the integration of event sensors into highly optimized Visual SLAM systems developed for frame cameras over decades of research. Unfortunately, existing approaches struggle with the motion-dependent appearance of keypoints and the complex noise prevalent in event streams, resulting in severely limited feature matching capabilities and poor performance on downstream tasks. To mitigate this problem, we propose SuperEvent, a data-driven approach to predict stable keypoints with expressive descriptors. Due to the absence of event datasets with ground truth keypoint labels, we leverage existing frame-based keypoint detectors on readily available event-aligned and synchronized gray-scale frames for self-supervision: we generate temporally sparse keypoint pseudo-labels considering that events are a product of both scene appearance and camera motion. Combined with our novel, information-rich event representation, we enable SuperEvent to effectively learn robust keypoint detection and description in event streams. Finally, we demonstrate the usefulness of SuperEvent by its integration into a modern sparse keypoint and descriptor-based SLAM framework originally developed for traditional cameras, surpassing the state-of-the-art in event-based SLAM by a wide margin. The source code and model weights will be published after acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In this work, we introduce **NoiseQuery** as a novel method for enhanced noise initialization in versatile goal-driven text-to-image (T2I) generation. Specifically, we propose to leverage an aligned Gaussian noise as implicit guidance to complement explicit user-defined inputs, such as text prompts, for better generation quality and controllability. Unlike existing noise optimization methods designed for specific models, our approach is grounded in a fundamental examination of the generic finite-step noise scheduler design in diffusion formulation, allowing better generalization across different diffusion-based architectures in a **tuning-free manner**. This model-agnostic nature allows us to construct a reusable noise library compatible with multiple T2I models and enhancement techniques, serving as a foundational layer for more effective generation. Extensive experiments demonstrate that **NoiseQuery** enables fine-grained control and yields significant performance boosts not only over high-level semantics but also over **low-level visual attributes**, which are typically difficult to specify through text alone, with seamless integration into current workflows with minimal computational overhead.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
3D data simulation aims to bridge the gap between simulated and real-captured 3D data, which is a fundamental problem for real-world 3D visual tasks. Most 3D data simulation methods inject predefined physical priors but struggle to capture the full complexity of real data. An optimal approach involves learning an implicit mapping from synthetic to realistic data in a data-driven manner, but progress in this solution has met stagnation in recent studies. This work explores a new solution path of data-driven 3D simulation, called Stable-Sim2Real, based on a novel two-stage depth diffusion model. The initial stage finetunes StableDiffusion to generate the residual between the real and synthetic paired depth, producing a stable but coarse depth, where some local regions may deviate from realistic patterns. To enhance this, both the synthetic and initial output depth are fed into a second-stage diffusion, where diffusion loss is adjusted to prioritize these distinct areas identified by a 3D discriminator. We provide a new benchmark scheme to evaluate 3D data simulation methods. Extensive experiments show that training the network with the 3D simulated data derived from our method significantly enhances performance in real-world 3D visual tasks. Moreover, the evaluation demonstrates the high similarity between our 3D …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 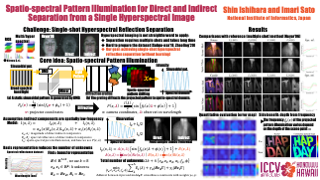
Abstract
Hyperspectral imaging has proven effective for appearance inspection because it can identify material compositions and reveal hidden features. Similarly, direct/indirect separation provides essential information about surface appearance and internal conditions, including layer structures and scattering behaviors. This paper presents a novel illumination system incorporating dispersive optics to unify both advantages for scene analyses. In general, achieving distinct direct/indirect separation requires multiple images with varying patterns. In a hyperspectral scenario, using a hyperspectral camera or tunable filters extends exposure and measurement times, hindering practical application.Our proposed system enables the illumination of a wavelength-dependent, spatially shifted pattern. With proper consideration of reflectance differences, we demonstrate robust separation of direct and indirect components for each wavelength can be achieved using a single hyperspectral image taken under one illumination pattern. Furthermore, we demonstrate analyzing the observed differences across wavelengths contributes to estimating depth.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Underwater visual simultaneous localization and mapping (SLAM) faces critical challenges in light attenuation and degraded geometric consistency. Despite recent advances of visual SLAM in indoor and urban scenes, these approaches typically assume a clear medium and neglect medium-light interactions, leading to performance degradation in underwater environments. To overcome these limitations, we propose DUV-SLAM, a dense underwater visual SLAM framework that integrates uncertainty-aware geometry estimation with physics-inspired neural scattering modeling. Our method introduces two core innovations: i) depth uncertainty quantification derived from differentiable bundle adjustment, which propagates geometric confidence to guide mapping optimization; and ii) a neural-Gaussian hybrid representation that combines adaptive 3D Gaussians for underwater reconstruction with a neural field capturing wavelength-dependent medium properties, optimized using a combination of photometric, geometric, and distribution losses. Experiments on synthetic and real-world datasets demonstrate that DUV-SLAM achieves high-quality monocular reconstruction while maintaining real-time efficiency and robust tracking accuracy. Our code will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Similar to conventional video generation, current deep learning-based weather prediction frameworks often lack explicit physical constraints, leading to unphysical outputs that limit their reliability for operational forecasting. Among various physical processes requiring proper representation, radiation plays a fundamental role as it drives Earth's weather and climate systems. However, accurate simulation of radiative transfer processes remains challenging for traditional numerical weather prediction (NWP) models due to their inherent complexity and high computational costs. Here, we propose FuXi-RTM, a hybrid physics-guided deep learning framework designed to enhance weather forecast accuracy while enforcing physical consistency. FuXi-RTM integrates a primary forecasting model (FuXi) with a fixed deep learning-based radiative transfer model (DLRTM) surrogate that efficiently replaces conventional radiation parameterization schemes. This represents the first deep learning-based weather forecasting framework to explicitly incorporate physical process modeling. Evaluated over a comprehensive 5-year dataset, FuXi-RTM outperforms its unconstrained counterpart in 88.51\% of 3320 variable and lead time combinations, with improvements in radiative flux predictions. By incorporating additional physical processes, FuXi-RTM paves the way for next-generation weather forecasting systems that are both accurate and physically consistent.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent advances in image-based saliency prediction are approaching gold standard performance levels on existing benchmarks. Despite this success, we show that predicting fixations across multiple saliency datasets remains challenging due to dataset bias. We find a significant performance drop (around 40%) when models trained on one dataset are applied to another. Surprisingly, increasing dataset diversity does not resolve this *inter-dataset gap*, with close to 60% attributed to dataset-specific biases. To address this remaining *generalization gap*, we propose a novel architecture extending a mostly dataset-agnostic encoder-decoder structure with fewer than 20 dataset-specific parameters that govern interpretable mechanisms such as multi-scale structure, center bias, and fixation spread. Adapting only these parameters to new data accounts for more than 75% of the generalization gap, with a large fraction of the improvement achieved with as few as 50 samples. Our model sets a new state-of-the-art on all three datasets of the MIT/Tuebingen Saliency Benchmark (MIT300, CAT2000, and COCO-Freeview), even when purely generalizing from unrelated datasets, but with a substantial boost when adapting to the respective training datasets. The model also provides valuable insights into spatial saliency properties, revealing complex multi-scale effects that combine both absolute and relative sizes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 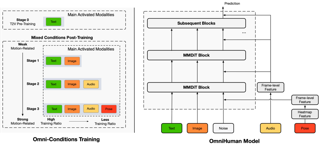
Abstract
End-to-end human animation, such as audio-driven talking human generation, has undergone notable advancements in the recent few years. However, existing methods still struggle to scale up as large general video generation models, limiting their potential in real applications. In this paper, we propose OmniHuman, a Diffusion Transformer-based framework that scales up data by mixing motion-related conditions into the training phase. To this end, we introduce two training principles for these mixed conditions, along with the corresponding model architecture and inference strategy. These designs enable OmniHuman to fully leverage data-driven motion generation, ultimately achieving highly realistic human video generation. More importantly, OmniHuman supports various portrait contents (face close-up, portrait, half-body, full-body), supports both talking and singing, handles human-object interactions and challenging body poses, and accommodates different image styles. Compared to existing end-to-end audio-driven methods, OmniHuman not only produces more realistic videos, but also offers greater flexibility in inputs. It also supports multiple driving modalities (audio-driven, video-driven and combined driving signals).
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 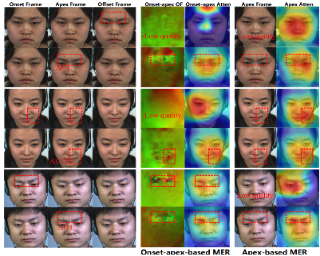
Abstract
Micro-expression recognition (MER) is a highly challenging task in affective computing. With the reduced-sized micro-expression (ME) input that contains key information based on key-frame indexes, key-frame-based methods have significantly improved the performance of MER. However, most of these methods focus on improving the performance with relatively accurate key-frame indexes, while ignoring the difficulty of obtaining accurate key-frame indexes and the objective existence of key-frame index errors, which impedes them from moving towards practical applications. In this paper, we propose CausalNet, a novel framework to achieve robust MER facing key-frame index errors while maintaining accurate recognition. To enhance robustness, CausalNet takes the representation of the entire ME sequence as the input. To address the information redundancy brought by the complete ME range input and maintain accurate recognition, first, the Causal Motion Position Learning Module (CMPLM) is proposed to help the model locate the muscle movement areas related to Action Units (AUs), thereby reducing the attention to other redundant areas. Second, the Causal Attention Block (CAB) is proposed to deeply learn the causal relationships between the muscle contraction and relaxation movements in MEs. Moreover, due to its unique design, the model can maintain sensitivity to local information as the feature fusion deepens. …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 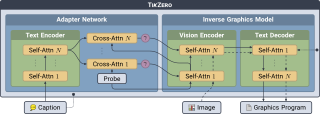
Abstract
With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like Ti*k*Z, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting Ti*k*Zero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, Ti*k*Zero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models will be made publicly available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
In this paper, we study the content-aware layout generation problem, which aims to automatically generate layouts that are harmonious with a given background image. Existing methods usually deal with this task with a single-step reasoning framework. The lack of a feedback-based self-correction mechanism leads to their failure rates significantly increasing when faced with complex element layout planning. To address this challenge, we introduce SEGA, a novel Stepwise Evolution paradigm for content-aware layout GenerAtion. Inspired by the systematic mode of human thinking, SEGA employs a hierarchical reasoning framework with a coarse-to-fine strategy: first, a coarse-level module roughly estimates the layout planning results; then, another refining module is leveraged to perform fine-level reasoning regarding the coarse planning results. Furthermore, we incorporate layout design principles as prior knowledge into the module to enhance its layout planning ability. Moreover, we present a new large-scale poster dataset, namely BIG-Poster with rich meta-information annotation. We conduct extensive experiments and obtain remarkable state-of-the-art performance improvement on multiple benchmark datasets.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Compared to 2D data, the scale of point cloud data in different domains available for training, is quite limited. Researchers have been trying to combine these data of different domains for masked autoencoder (MAE) pre-training to leverage such a data scarcity issue. However, the prior knowledge learned from mixed domains may not align well with the downstream 3D point cloud analysis tasks, leading to degraded performance. To address such an issue, we propose the Domain-Adaptive Point Cloud Masked Autoencoder (DAP-MAE), an MAE pre-training method, to adaptively integrate the knowledge of cross-domain datasets for general point cloud analysis. In DAP-MAE, we design a heterogeneous domain adapter that utilizes an adaptation mode during the pre-training, enabling the model to comprehensively learn information from point clouds across different domains, while employing a fusion mode in the fine-tuning to enhance point cloud features. Meanwhile, DAP-MAE incorporates a domain feature generator to guide the adaptation of point cloud features to various downstream tasks. With only one pre-training, DAP-MAE achieves excellent performance across four different point cloud analysis tasks, reaching 95.18\% in object classification on ScanObjectNN and 88.45\% in facial expression recognition on Bosphorus.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 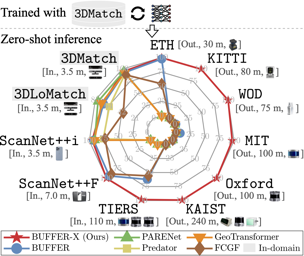
Abstract
Recent advances in deep learning-based point cloud registration have improved generalization, yet most methods still require retraining or manual parameter tuning for each new environment. In this paper, we identify three key factors limiting generalization: (a) reliance on environment-specific voxel size and search radius, (b) poor out-of-domain robustness of learning-based keypoint detectors,and (c) raw coordinate usage, which exacerbates scale discrepancies. To address these issues, we present a zero-shot registration pipeline called BUFFER-X by (a) adaptively determining voxel size/search radii, (b) using farthest point sampling to bypass learned detectors, and (c) leveraging patch-wise scale normalization for consistent coordinate bounds. In particular, we present a multi-scale patch-based descriptor generation and a hierarchical inlier search across scales to improve robustness in diverse scenes. We also propose a novel generalizability benchmark using 11 datasets that cover various indoor/outdoor scenarios and sensor modalities, demonstrating that BUFFER-X achieves substantial generalization without prior information or manual parameter tuning for the test datasets. Our code will be made publicly available.
|
|
Highlight
|
Poster
Yuchen Zhou · Jiayu Tang · Xiaoyan Xiao · Yueyao Lin · Linkai Liu · Zipeng Guo · Hao Fei · Xiaobo Xia · Chao Gou
Exhibit Hall I
Abstract
Modeling task-driven attention in driving is a fundamental challenge for both autonomous vehicles and cognitive science. Existing methods primarily predict where drivers look by generating spatial heatmaps, but fail to capture the cognitive motivations behind attention allocation in specific contexts, which limits deeper understanding of attention mechanisms. To bridge this gap, we introduce Explainable Driver Attention Prediction, a novel task paradigm that jointly predicts spatial attention regions (where), parses attended semantics (what), and provides cognitive reasoning for attention allocation (why). To support this, we present W³DA, the first large-scale explainable driver attention dataset. It enriches existing benchmarks with detailed semantic and causal annotations across diverse driving scenarios, including normal conditions, safety-critical situations, and traffic accidents. We further propose LLada, a Large Language model-driven framework for driver attention prediction, which unifies pixel modeling, semantic parsing, and cognitive reasoning within an end-to-end architecture. Extensive experiments demonstrate the effectiveness of LLada, exhibiting robust …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
3D Gaussian Splatting (3DGS) is a powerful reconstruction technique, but it needs to be initialized from accurate camera poses and high-fidelity point clouds. Typically, the initialization taken from Structure-from-Motion (SfM) algorithms; however, SfM is time-consuming and restricts the application of 3DGS in real-world scenarios and large-scale scene reconstruction. We introduce a constrained optimization method for simultaneous camera pose estimation and 3D reconstruction that does not require SfM support. Core to our approach is decomposing a camera pose into a sequence of camera-to-(device-)center and (device-)center-to-world optimizations. To facilitate, we propose two optimization constraints conditioned to the sensitivity of each parameter group and restricts each parameter’s search space. In addition, as we learn the scene geometry directly from the noisy point clouds, we propose geometric constraints to improve the reconstruction quality. Experiments demonstrate that the proposed method significantly outperforms the existing (multi-modal) 3DGS baseline and methods supplemented by COLMAP on both our collected dataset and two public benchmarks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Cooperative perception aims to address the inherent limitations of single autonomous driving systems through information exchange among multiple agents. Previous research has primarily focused on single-frame perception tasks. However, the more challenging cooperative sequential perception tasks, such as cooperative 3D multi-object tracking, have not been thoroughly investigated.Therefore, we propose CoopTrack, a fully instance-level end-to-end framework for cooperative tracking, featuring learnable instance association, which fundamentally differs from existing approaches.CoopTrack transmits sparse instance-level features that significantly enhance perception capabilities while maintaining low transmission costs. Furthermore, the framework comprises three key components: Multi-Dimensional Feature Extraction (MDFE), Cross-Agent Alignment (CAA), and Graph-Based Association (GBA), which collectively enable comprehensive instance representation with semantic and motion features, and adaptive cross-agent association and fusion based on graph learning.Experiments on the V2X-Seq dataset demonstrate that, benefiting from its sophisticated design, CoopTrack achieves state-of-the-art performance, with 39.0\% mAP and 32.8\% AMOTA. Codes and visualization results are provided in the supplementary materials.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Neural representations of 3D data have been widely adopted across various applications, particularly in recent work leveraging coordinate-based networks to model scalar or vector fields. However, these approaches face inherent challenges, such as handling thin structures and non-watertight geometries, which limit their flexibility and accuracy. In contrast, we propose a novel geometric data representation that models geometry as distributions-a powerful representation that makes no assumptions about surface genus, connectivity, or boundary conditions. Our approach uses diffusion models with a novel network architecture to learn surface point distributions, capturing fine-grained geometric details. We evaluate our representation qualitatively and quantitatively across various object types, demonstrating its effectiveness in achieving high geometric fidelity. Additionally, we explore applications using our representation, such as textured mesh representation, neural surface compression, dynamic object modeling, and rendering, highlighting its potential to advance 3D geometric learning.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 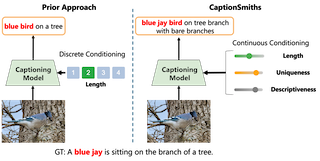
Abstract
An image captioning model flexibly switching its language pattern, e.g., descriptiveness and length, should be useful since it can be applied to diverse applications. However, despite the dramatic improvement in generative vision-language models, fine-grained control over the properties of generated captions is not easy due to two reasons: (i) existing models are not given the properties as a condition during training and (ii) existing models cannot smoothly transition its language pattern from one state to the other. Given this challenge, we propose a new approach, CaptionSmiths, to acquire a single captioning model that can handle diverse language patterns. First, our approach quantifies three properties of each caption, length, descriptiveness, and uniqueness of a word, as continuous scalar values, without human annotation. Given the values, we represent the conditioning via interpolation between two endpoint vectors corresponding to the extreme states, e.g., one for a very short caption and one for a very long caption. Empirical results demonstrate that the resulting model can smoothly change the properties of the output captions and show higher lexical alignment than baselines. For instance, CaptionSmiths reduces the error in controlling caption length by 506% despite better lexical alignment.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Most 3D object generators focus on aesthetic quality, often neglecting physical constraints necessary in applications.One such constraint is that the 3D object should be self-supporting, i.e., remains balanced under gravity.Prior approaches to generating stable 3D objects used differentiable physics simulators to optimize geometry at test-time, which is slow, unstable, and prone to local optima. Inspired by the literature on aligning generative models to external feedback, we propose Direct Simulation Optimization (DSO), a framework to use the feedback from a (non-differentiable) simulator to increase the likelihood that the 3D generator outputs stable 3D objects directly. We construct a dataset of 3D objects labeled with a stability score obtained from the physics simulator. We can then fine-tune the 3D generator using the stability score as the alignment metric, via direct preference optimization (DPO) or direct reward optimization (DRO), a novel objective, which we introduce, to align diffusion models without requiring pairwise preferences. Our experiments show that the fine-tuned feed-forward generator, using either DPO or DRO objective, is much faster and more likely to produce stable objects than test-time optimization. Notably, the DSO framework works even without any ground-truth 3D objects for training, allowing the 3D generator to self-improve by automatically collecting simulation …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. We introduce a method for reconstructing generic dynamic scenes, featuring explicit, persistent 3D motion trajectories in the world coordinate frame, from casually captured monocular videos.We tackle the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE(3) motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we take advantage of off-the-shelf data-driven priors such as monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, very dense captures involving many images are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow-matching model that learns a flow to connect novel views generated from possibly-sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with generated novel views to improve the overall reconstruction quality.Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in few-view and many-view scenarios, leading to higher-quality reconstructions than prior works …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Lidar has become crucial for autonomous driving, providing high-resolution 3D scans that are key for accurate scene understanding. To this end, lidar sensors measure the time-resolved full waveforms from the returning laser light, which a subsequent digital signal processor (DSP) converts to point clouds by identifying peaks in the waveform. Conventional automotive lidar DSP pipelines process each waveform individually, ignoring potentially valuable context from neighboring waveforms. As a result, lidar point clouds are prone to artifacts from low signal-to-noise ratio (SNR) regions, highly reflective objects, and environmental conditions like fog. While leveraging neighboring waveforms has been investigated extensively in transient imaging, the application has been limited to scientific or experimental hardware. In this work, we propose a learned DSP that directly processes full waveforms using a transformer architecture leveraging features from adjacent waveforms to generate high-fidelity multi-echo point clouds. To assess our method, we modify a conventional automotive lidar and capture data in real-world driving scenarios. Furthermore, we collect dedicated test sets in a weather chamber to asses our method in different environmental conditions. Trained on both synthetic and real data, the method improves Chamfer distance by 32 cm and 20 cm compared to on-device peak finding methods and existing …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The Reflow operation aims to straighten the inference trajectories of the rectified flow during training by constructing deterministic couplings between noises and images, thereby improving the quality of generated images in single-step or few-step generation. However, we identify critical limitations in Reflow, particularly its inability to rapidly generate high-quality images due to a distribution gap between images in its constructed deterministic couplings and real images. To address these shortcomings, we propose a novel alternative called Straighten Viscous Rectified Flow via Noise Optimization (VRFNO), which is a joint training framework integrating an encoder and a neural velocity field. VRFNO introduces two key innovations: (1) a historical velocity term that enhances trajectory distinction, enabling the model to more accurately predict the velocity of the current trajectory, and (2) the noise optimization through reparameterization to form optimized couplings with real images which are then utilized for training, effectively mitigating errors caused by Reflow's limitations. Comprehensive experiments on synthetic data and real datasets with varying resolutions show that VRFNO significantly mitigates the limitations of Reflow, achieving state-of-the-art performance in both one-step and few-step generation tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to the limited amount of 3D training data, such a model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as a model inversion process by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides a meaningful initialization for model fitting, enforces 3D regularization, and helps in refining pose estimation. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 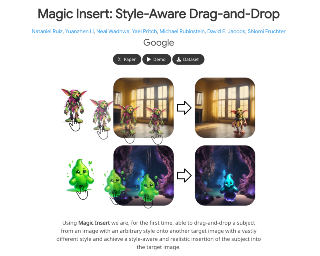
Abstract
We present Magic Insert, a method to drag-and-drop subjects from a user-provided image into a target image of a different style in a plausible manner while matching the style of the target image. This work formalizes our version of the problem of style-aware drag-and-drop and proposes to tackle it by decomposing it into two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, we cast our method as a weight-and-text-embedding finetuning method with inference-time module-targeted style injection. For subject insertion, we propose Bootstrapped Domain Adaption (BDA) to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional and state-of-the-art approaches that struggle with quality, subject fidelity and harmonious stylization. Finally, we present a new dataset, SubjectPlop, to facilitate evaluation and future progress in this area.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 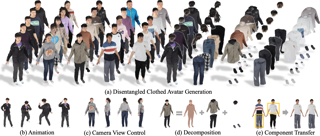
Abstract
Clothed avatar generation has wide applications in virtual and augmented reality, filmmaking, and more. While existing methods have made progress in creating animatable digital avatars, generating avatars with disentangled components (e.g., body, hair, and clothes) has long been a challenge. In this paper, we propose LayerAvatar, a novel feed-forward diffusion-based method capable of generating high-quality component-disentangled clothed avatars in seconds. We propose a layered UV feature plane representation, where components are distributed in different layers of the Gaussian-based UV feature plane with corresponding semantic labels. This representation can be effectively learned with current feed-forward generation pipelines, facilitating component disentanglement and enhancing details of generated avatars. Based on the well-designed representation, we train a single-stage diffusion model and introduce constrain terms to mitigate the severe occlusion issue of the innermost human body layer. Extensive experiments demonstrate the superior performances of our method in generating highly detailed and disentangled clothed avatars. In addition, we explore its applications in component transfer.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Miniaturized endoscopy has advanced accurate visual perception within the human body. Prevailing research remains limited to conventional cameras employing convex lenses, where the physical constraints with millimetre-scale thickness impose serious impediments on the micro-level clinical. Recently, with the emergence of meta-optics, ultra-micro imaging based on metalenses (micron-scale) has garnered great attention, serving as a promising solution. However, due to the physical difference of metalens, there is a large gap in data acquisition and algorithm research. In light of this, we aim to bridge this unexplored gap, advancing the novel metalens endoscopy. First, we establish datasets for metalens endoscopy and conduct preliminary optical simulation, identifying two derived optical issues that physically adhere to strong optical priors. Second, we propose MetaScope, a novel optics-driven neural network tailored for metalens endoscopy driven by physical optics. MetaScope comprises two novel designs: Optics-informed Intensity Adjustment (OIA), rectifying intensity decay by learning optical embeddings, and Optics-informed Chromatic Correction (OCC), mitigating chromatic aberration by learning spatial deformations informed by learned Point Spread Function (PSF) distributions. To enhance joint learning, we deploy a gradient-guided distillation to adaptively transfer knowledge from the foundational model. Extensive experiments demonstrate that our method surpasses state-of-the-art methods in metalens segmentation and restoration by …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes ("trends") across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., "what are the frequent types of changes in the city?") without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to injest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., "addition of outdoor dining,", "overpass was painted blue," etc.).
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
The research focus of GUI agents is shifting from text-dependent to pure-vision-based approaches, which, though promising, prioritize comprehensive pre-training data collection while neglecting contextual modeling challenges. We probe the characteristics of element and history contextual modeling in GUI agent and summarize: **1) the high-density and loose-relation of element context** highlight the existence of many unrelated elements and their negative influence; **2) the high redundancy of history context** reveals the inefficient history modeling in current GUI agents. In this work, we propose a context-aware simplification framework for building an efficient and effective GUI Agent, termed **SimpAgent**. To mitigate potential interference from numerous unrelated elements, we introduce a **masking-based element pruning** method that circumvents the intractable relation modeling through an efficient masking mechanism. To reduce the redundancy in historical information, we devise a **consistency-guided history compression** module, which enhances implicit LLM-based compression through innovative explicit guidance, achieving an optimal balance between performance and efficiency. With the above components, SimpAgent reduces 27\% FLOPs and achieves superior GUI navigation performances. Comprehensive navigation experiments across diverse web and mobile environments demonstrate the effectiveness and potential of our agent.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Image editing techniques have rapidly advanced, facilitating both innovative use cases and malicious manipulation of digital images. Deep learning-based methods have recently achieved high accuracy in pixel-level forgery localization, yet they frequently struggle with computational overhead and limited representation power, particularly for subtle or complex tampering. In this paper, we propose M2SFormer, a novel Transformer encoder-based framework designed to overcome these challenges. Unlike approaches that process spatial and frequency cues separately, M2SFormer unifies multi-frequency and multi-scale attentions in the skip connection, harnessing global context to better capture diverse forgery artifacts. Additionally, our framework addresses the loss of fine detail during upsampling by utilizing a global prior map—a curvature metric indicating the difficulty of forgery localization—which then guides a difficulty-guided attention module to preserve subtle manipulations more effectively. Extensive experiments on multiple benchmark datasets demonstrate that M2SFormer outperforms existing state-of-the-art models, offering superior generalization in detecting and localizing forgeries across unseen domains.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent advances in monocular depth estimation have significantly improved its robustness and accuracy. Despite these improvements, relative depth models, which offer strong generalization capability, fail to provide real-world depth measurements. Notably, these models exhibit severe flickering and 3D inconsistency when applied to video data, limiting their application for 3D reconstruction. To address these challenges, we introduce StableDepth, a scene-consistent and scale-invariant depth estimation method that achieves stable predictions with scene-level 3D consistency. We propose a dual decoder structure to learn smooth depth supervised by large-scale unlabeled video data. Our approach not only enhances the generalization capability but also reduces flickering during video depth estimation. Leveraging the vast amount of unlabeled video data, our method offers extensive stability and is easy to scale up with low cost. Unlike previous methods requiring full video sequences, StableDepth enables online inference at 13$\times$ faster speed, while achieving significant accuracy improvements (6.4\%-86.8\%) across multiple benchmarks and delivering comparable temporal consistency to video diffusion based depth estimators. We highly encourage viewing the supplementary video materials to gain a better understanding of the effectiveness of our approach.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Unsupervised object discovery (UOD) aims to detect and segment objects in 2D images without handcrafted annotations. Recent progress in self-supervised representation learning has led to some success in UOD algorithms. However, the absence of ground truth provides existing UOD methods with two challenges: 1) determining if a discovered region is foreground or background, and 2) knowing how many objects remain undiscovered. To address these two problems, previous solutions rely on foreground priors to distinguish if the discovered region is foreground, and conduct one or fixed iterations of discovery. However, the existing foreground priors are heuristic and not always robust, and a fixed number of discoveries leads to under or over-segmentation, since the number of objects in images varies. This paper introduces UnionCut, a robust foreground prior based on ensemble methods that detects the union of foreground areas of an image, allowing UOD algorithms to identify foreground objects and stop discovery once the majority of the foreground union in the image is segmented. On top of that, we propose UnionSeg, a vision transformer distilled from UnionCut that outputs the foreground union faster and more accurately. Our experiments show that by combining with UnionCut or UnionSeg, previous state-of-the-art UOD methods witness an …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
We present Video Motion Graphs, a system designed to generate realistic human motion videos. Using a reference video and conditional signals such as music or motion tags, the system synthesizes new videos by first retrieving video clips with gestures matching the conditions and then generating interpolation frames to seamlessly connect clip boundaries. The core of our approach is HMInterp, a robust Video Frame Interpolation (VFI) model that enables seamless interpolation of discontinuous frames, even for complex motion scenarios like dancing. HMInterp i) employs a dual-branch interpolation approach, combining a Motion Diffusion Model for human skeleton motion interpolation with a diffusion-based video frame interpolation model for final frame generation. ii) adopts condition progressive training to effectively leverage identity strong and weak conditions, such as images and pose. These designs ensure both high video texture quality and accurate motion trajectory. Our Video Motion Graphs outperforms existing generative- and retrieval-based methods for human motion video generation. Our codes and pretrained models are public available.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Vision-Language Models (VLMs) excel at visual understanding by leveraging pretrained image encoders to generate visual tokens. However, they struggle with high-resolution images and zoomed-in regions due to the computational burden and token redundancy of uniform patch-based processing, often leading to the loss of critical details. To address these challenges, we propose Token-Efficient Vision Language Model (TEVA), a novel framework that detects key regions and applies dynamic patch sampling to efficiently capture fine-grained details while preserving global context. Our approach first identifies subject-oriented regions using an adaptive detection strategy. Then, a dynamic patch sampling mechanism selects and arranges patches at varying scales, ensuring efficient processing without increasing token count. Extensive experiments demonstrate that Token-Efficient Vision Language Model (TEVA) significantly enhances VLM performance in handling visual details, seamlessly integrating with various decoders and LLMs. Code and dataset will be released upon publication.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] Abstract
Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
We develop a neural parametric model for 3D plant leaves for modeling and reconstruction of plants that are essential for agriculture and computer graphics. While parametric modeling has been actively studied for human and animal shapes, plant leaves present unique challenges due to their diverse shapes and flexible deformation, making common approaches inapplicable. To this problem, we introduce a learning-based parametric model, NeuraLeaf, disentangling the leaves' geometry into their 2D base shapes and 3D deformations. Since the base shapes represent flattened 2D leaves, it allows learning from rich sources of 2D leaf image datasets, and also has the advantage of simultaneously learning texture aligned with the geometry. To model the 3D deformation, we propose a novel skeleton-free skinning model and a newly captured 3D leaf dataset called DeformLeaf. We establish a parametric deformation space by converting the sample-wise skinning parameters into a compact latent representation, allowing for flexible and efficient modeling of leaf deformations. We show that NeuraLeaf successfully generates a wide range of leaf shapes with deformation, resulting in accurate model fitting to 3D observations like depth maps and point clouds. Our implementation and datasets will be released upon acceptance.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Embodied scene understanding requires not only comprehending visual-spatial information that has been observed but also determining where to explore next in the 3D physical world. Existing 3D Vision-Language (3D-VL) models primarily focus on grounding objects in static observations from 3D reconstruction, such as meshes and point clouds, but lack the ability to actively perceive and explore their environment. To address this limitation, we introduce \underline{\textbf{M}}ove \underline{\textbf{t}}o \underline{\textbf{U}}nderstand (\textbf{MTU3D}), a unified framework that integrates active perception with \underline{\textbf{3D}} vision-language learning, enabling embodied agents to effectively explore and understand their environment. This is achieved by three key innovations 1) Online query-based representation learning, enabling direct spatial memory construction from RGB-D frames, eliminating the need for explicit 3D reconstruction. 2) A unified objective for grounding and exploration that represents unexplored locations as frontier queries and jointly optimizes object grounding and frontier selection. 3) End-to-end trajectory learning that combines \textbf{V}ision-\textbf{L}anguage-\textbf{E}xploration pre-training over a million diverse trajectories collected from both simulated and real-world RGB-D sequences. Extensive evaluations across various embodied navigation and question-answering benchmarks show that MTU3D outperforms state-of-the-art reinforcement learning and modular navigation approaches by 14\%, 27\%, 11\%, and 3\% in success rate on HM3D-OVON, GOAT-Bench, SG3D, and A-EQA, respectively. MTU3D's versatility enables navigation …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper introduces a new shape-matching methodology, combinative matching, to combine interlocking parts for geometric shape assembly. Previous methods for geometric assembly typically rely on aligning parts by finding identical surfaces between the parts as in conventional shape matching and registration. In contrast, we explicitly model two distinct properties of interlocking shapes: 'identical surface shape' and 'opposite volume occupancy.' Our method thus learns to establish correspondences across regions where their surface shapes appear identical but their volumes occupy the inverted space to each other. To facilitate this process, we also learn to align regions in rotation by estimating their shape orientations via equivariant neural networks. The proposed approach significantly reduces local ambiguities in matching and allows a robust combination of parts in assembly. Experimental results on geometric assembly benchmarks demonstrate the efficacy of our method, consistently outperforming the state of the art.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
2D irregular packing is a classic combinatorial optimization problem with various applications, such as material utilization and texture atlas generation. Due to its NP-hard nature, conventional numerical approaches typically encounter slow convergence and high computational costs. Previous research (GFPack) introduced a generative method for gradient-based packing, providing early evidence of its feasibility but faced limitations such as insufficient rotation support, poor boundary adaptability, and high overlap ratios. In this paper, we propose GFPack++, a deeply investigated framework that adopts attention-based geometry and relation encoding, enabling more comprehensive modeling of complex packing relationships. We further design a constrained gradient and a weighting function to enhance both the feasibility of the produced solutions and the learning effectiveness. Experimental results on multiple datasets demonstrate that GFPack++ achieves higher space utilization, supports continuous rotation, generalizes well to arbitrary boundaries, and infers orders of magnitude faster than previous approaches. We plan to release our code and datasets to advance further research in 2D irregular packing.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
This paper presents SANA-Sprint, an efficient diffusion model for ultra-fast text-to-image (T2I) generation. SANA-Sprint is built on a pre-trained foundation model and augmented with hybrid distillation, dramatically reducing inference steps from 20 to 1-4.We introduce three key innovations: $\textbf{(1)}$ We propose a training-free approach that transforms a pre-trained flow-matching model for continuous-time consistency distillation (sCM), eliminating costly training from scratch and achieving high training efficiency. Our hybrid distillation strategy combines sCM with latent adversarial distillation (LADD): sCM ensures alignment with the teacher model, while LADD enhances single-step generation fidelity. $\textbf{(2)}$ SANA-Sprint is a unified step-adaptive model that achieves high-quality generation in 1-4 steps, eliminating step-specific training and improving efficiency. $\textbf{(3)}$ We integrate ControlNet with SANA-Sprint for real-time interactive image generation, enabling instant visual feedback for user interaction. SANA-Sprint establishes a new Pareto frontier in speed-quality tradeoffs, achieving state-of-the-art performance with 7.59 FID and 0.74 GenEval in just 1 step — outperforming FLUX-schnell (7.94 FID / 0.71 GenEval) while being 10× faster (0.1s vs 1.1s on H100). It also achieves 0.1s (T2I) and 0.25s (ControlNet) latency for 1024$\times$1024 images on H100, and 0.31s (T2I) on an RTX 4090, showcasing its exceptional efficiency and potential for AI-powered consumer applications (AIPC). Code and …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Why don't we have foundation models in 3D yet? A key limitation is data scarcity. For 3D object part segmentation, existing datasets are small in size and lack diversity. We show that it is possible to break this data barrier by building a data engine powered by 2D foundation models. Our data engine automatically annotates any number of object parts: 1755x more unique part types than existing datasets combined. By training on our annotated data with a simple contrastive objective, we obtain an open-world model that generalizes to any part in any object based on any text query. Even when evaluated zero-shot, we outperform existing methods on the datasets they train on. We achieve 260% improvement in mIoU and boost speed by 6x to 300x. Our scaling analysis confirms that this generalization stems from the data scale, which underscores the impact of our data engine. Finally, to advance general-category open-world 3D part segmentation, we release a benchmark covering a wide range of objects and parts.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent artificial intelligence (AI) generative models have demonstrated remarkable capabilities in image production, and have been widely applied to face image generation, customization, and restoration. However, many AI-generated faces (AIGFs) still suffer from issues such as unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation method for AIGFs. To this end, we introduce **FaceQ**, the first comprehensive AI-generated Face image database with fine-grained Quality annotations aligned with human preferences, which consists of 12K images and 491K ratings across multiple dimensions. Using the FaceQ database, we establish **F-Bench**, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA) methods on FaceQ, and further propose a large multimodal model (LMM) based Face quality Evaluator (**F-Eval**) to accurately assess the multi-dimensional quality of generated faces in a one-for-all manner. Extensive experimental results demonstrate the state-of-the-art performance of our F-Eval. FaceQ, F-Bench, and F-Eval will be publicly available upon publication.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Recent breakthroughs in large multimodal models (LMMs) have significantly advanced both text-to-image (T2I) generation and image-to-text (I2T) interpretation. However, many generated images still suffer from issues related to perceptual quality and text-image alignment. Given the high cost and inefficiency of manual evaluation, an automatic metric that aligns with human preferences is desirable. To this end, we present EvalMi-50K, a comprehensive dataset and benchmark for evaluating large-multimodal image generation,which features (i) comprehensive tasks, encompassing 2,100 extensive prompts across 20 fine-grained task dimensions, and (ii) large-scale human-preference annotations, including 100K mean-opinion scores (MOSs) and 50K question-answering (QA) pairs annotated on 50,400 images generated from 24 T2I models.Based on EvalMi-50K, we propose LMM4LMM, an LMM-based metric for evaluating large multimodal T2I generation from multiple dimensions including perceptual quality, text-image correspondence, and task-specific accuracy.Extensive experimental results show that LMM4LMM achieves state-of-the-art performance on EvalMi-50K, and exhibits strong generalization ability on other AI-generated image evaluation benchmark datasets, manifesting the generality of both the EvalMi-50K dataset and LMM4LMM metric.Both EvalMi-50K and LMM4LMM will be released upon the publication.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Open-set counting is garnering increasing attention due to its capability to enumerate objects of arbitrary category. It can be generally categorized into two methodologies: text-guided zero-shot counting methods and exemplar-guided few-shot counting methods. Previous text-guided zero-shot methods only provide limited object information through text, resulting in poor performance. Besides, though exemplar-guided few-shot approaches gain better results, they rely heavily on manually annotated visual exemplars, resulting in low efficiency and high labor intensity. Therefore, we propose CountSE, which simultaneously achieves high efficiency and high performance. CountSE is a new text-guided zero-shot object counting algorithm that generates multiple precise soft exemplars at different scales to enhance counting models driven solely by semantics. Specifically, to obtain richer object information and address the diversity in object scales, we introduce Semantic-guided Exemplar Selection, a module that generates candidate soft exemplars at various scales and selects those with high similarity scores. Then, to ensure accuracy and representativeness, Clustering-based Exemplar Filtering is introduced to refine the candidate exemplars by effectively eliminating inaccurate exemplars through clustering analysis. In the text-guided zero-shot setting, CountSE outperforms all state-of-the-art methods on the FSC-147 benchmark by at least 15\%. Additionally, experiments on two other widely used datasets demonstrate that CountSE significantly outperforms …
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Reconstructing structured 3D scenes from RGB images using CAD objects unlocks efficient and compact scene representations that maintain compositionality and interactability. Existing works propose training-heavy methods relying on either expensive yet inaccurate real-world annotations or controllable yet monotonous synthetic data that do not generalize well to unseen objects or domains. We present Diorama, the first zero-shot open-world system that holistically models 3D scenes from single-view RGB observations without requiring end-to-end training or human annotations. We show the feasibility of our approach by decomposing the problem into subtasks and introduce better solutions to each: architecture reconstruction, 3D shape retrieval, object pose estimation, and scene layout optimization. We evaluate our system on both synthetic and real-world data to show we significantly outperform baselines from prior work. We also demonstrate generalization to real-world internet images and the text-to-scene task.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Training-free open-vocabulary semantic segmentation has advanced with vision-language models like CLIP, which exhibit strong zero-shot abilities. However, CLIP's attention mechanism often wrongly emphasises specific image tokens, namely outliers, which results in irrelevant over-activation. Existing approaches struggle with these outliers that arise in intermediate layers and propagate through the model, ultimately degrading spatial perception. In this paper, we propose a Self-adaptive Feature Purifier framework (SFP) to suppress propagated outliers and enhance semantic representations for open-vocabulary semantic segmentation. Specifically, based on an in-depth analysis of attention responses between image and class tokens, we design a self-adaptive outlier mitigator to detect and mitigate outliers at each layer for propagated feature purification. In addition, we introduce a semantic-aware attention enhancer to augment attention intensity in semantically relevant regions, which strengthens the purified feature to focus on objects. Further, we introduce a hierarchical attention integrator to aggregate multi-layer attention maps to refine spatially coherent feature representations for final segmentation. Our proposed SFP enables robust outlier suppression and object-centric feature representation, leading to a more precise segmentation. Extensive experiments show that our method achieves state-of-the-art performance and surpasses existing methods by an average of 4.6% mIoU on eight segmentation benchmarks. The code will be released.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Vision Language Models (VLMs) have exhibited remarkable generalization capabilities, yet their robustness in dynamic real-world scenarios remains largely unexplored. To systematically evaluate VLMs' robustness to real-world 3D variations, we propose AdvDreamer, the first framework capable of generating physically reproducible Adversarial 3D Transformation (Adv-3DT) samples from single-view observations. In AdvDreamer, we integrate three key innovations: Firstly, to characterize real-world 3D variations with limited prior knowledge precisely, we design a zero-shot Monocular Pose Manipulation pipeline built upon generative 3D priors. Secondly, to ensure the visual quality of worst-case Adv-3DT samples, we propose Naturalness Reward Model that provides continuous naturalness regularization during adversarial optimization, effectively preventing convergence to hallucinated or unnatural elements. Thirdly, to enable systematic evaluation across diverse VLM architectures and visual-language tasks, we introduce the Inverse Semantic Probability loss as the adversarial optimization objective, which solely operates in the fundamental visual-textual alignment space. Based on the captured Adv-3DT samples with high aggressiveness and transferability, we establish MM3DTBench, the first VQA benchmark dataset tailored to evaluate VLM robustness under challenging 3D variations. Extensive evaluations of representative VLMs with varying architectures reveal that real-world 3D variations can pose severe threats to model performance across various tasks.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Low-Rank Adaptation (LoRA) has emerged as a powerful and popular technique for personalization, enabling efficient adaptation of pre-trained image generation models for specific tasks without comprehensive retraining. While employing individual pre-trained LoRA models excels at representing single concepts, such as those representing a specific dog or a cat, utilizing multiple LoRA models to capture a variety of concepts in a single image still poses a significant challenge. Existing methods often fall short, primarily because the attention mechanisms within different LoRA models overlap, leading to scenarios where one concept may be completely ignored (e.g., omitting the dog) or where concepts are incorrectly combined (e.g., producing an image of two cats instead of one cat and one dog). We introduce CLoRA, a training-free approach that addresses these limitations by updating the attention maps of multiple LoRA models at test-time, and leveraging the attention maps to create semantic masks for fusing latent representations. This enables the generation of composite images that accurately reflect the characteristics of each LoRA. Our comprehensive qualitative and quantitative evaluations demonstrate that CLoRA significantly outperforms existing methods in multi-concept image generation using LoRAs.
|
|
Highlight
|
Poster
[ Exhibit Hall I ] 
Abstract
Vision Transformers (ViTs) have revolutionized large-scale visual modeling, yet remain underexplored in face recognition (FR) where CNNs still dominate. We identify a critical bottleneck: CNN-inspired training paradigms fail to unlock ViT's potential, leading to suboptimal performance and convergence instability.To address this challenge, we propose LVFace, a ViT-based FR model that integrates Progressive Cluster Optimization (PCO) to achieve superior results. Specifically, PCO sequentially applies negative class sub-sampling (NCS) for robust and fast feature alignment from random initialization, feature expectation penalties for centroid stabilization, performing cluster boundary refinement through full-batch training without NCS constraints. LVFace establishes a new state-of-the-art face recognition baseline, surpassing leading approaches such as UniFace and TopoFR across multiple benchmarks. Extensive experiments demonstrate that LVFace delivers consistent performance gains, while exhibiting scalability to large-scale datasets and compatibility with mainstream VLMs and LLMs. Notably, LVFace secured 1st place in the ICCV 2021 Masked Face Recognition (MFR)-Ongoing Challenge (March 2025), proving its efficacy in real-world scenarios.
|