Seeing the Trees for the Forest: Rethinking Weakly-Supervised Medical Visual Grounding
 Highlight
Highlight
{kind=link}
Abstract
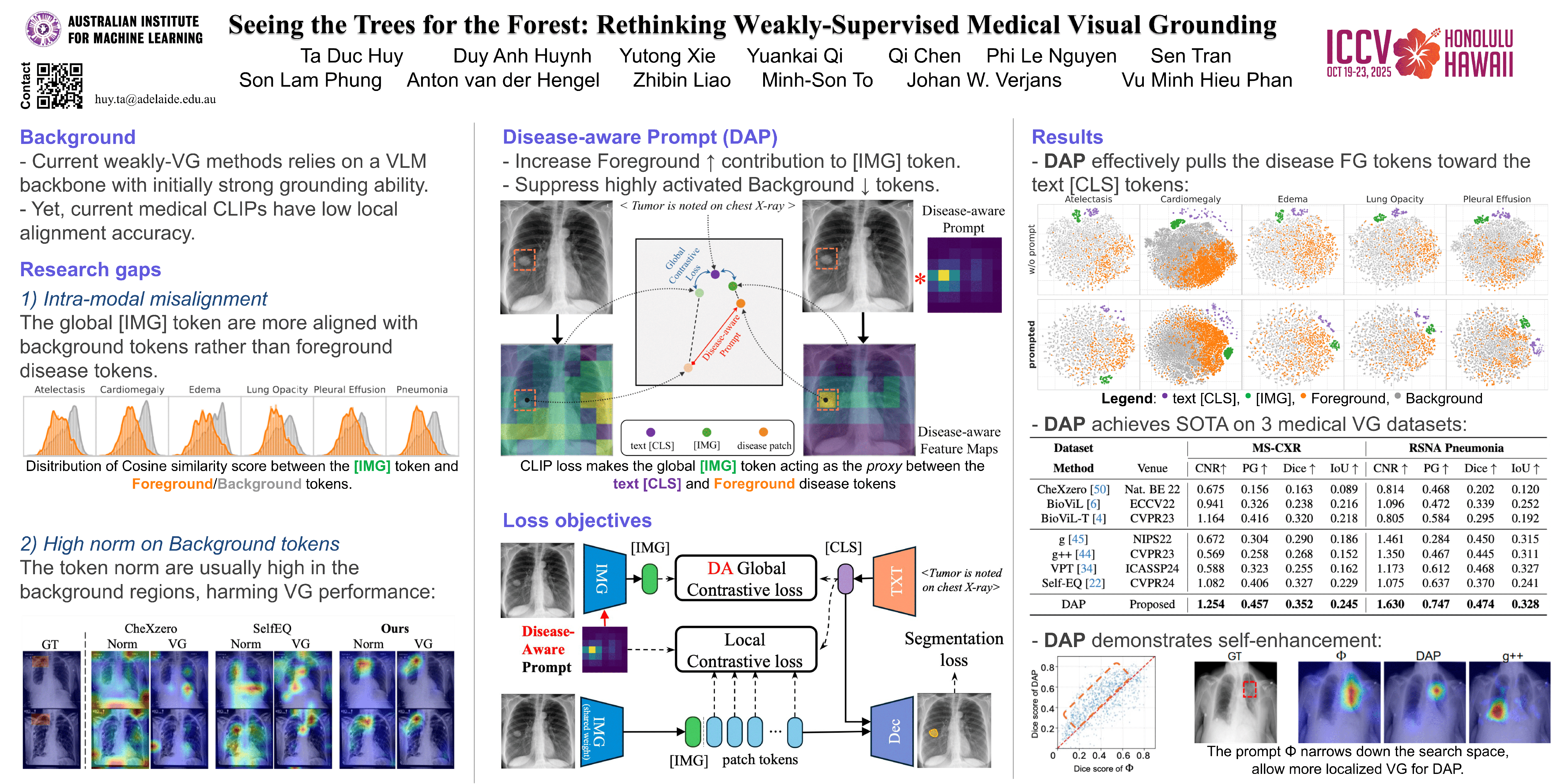
Visual grounding (VG) is the capability to identify the specific regions in an image associated with a particular text description. In medical imaging, VG enhances interpretability by highlighting relevant pathological features corresponding to textual descriptions, improving model transparency and trustworthiness for wider adoption of deep learning models in clinical practice. Current models struggle to associate textual descriptions with disease regions due to inefficient attention mechanisms and a lack of fine-grained token representations. In this paper, we empirically demonstrate two key observations. First, current VLMs assign high norms to background tokens, diverting the model's attention from regions of disease. Second, the global tokens used for cross-modal learning are not representative of local disease tokens. This hampers identifying correlations between the text and disease tokens. To address this, we introduce simple, yet effective Disease-Aware Prompting (DAP) process, which uses the explainability map of a VLM to identify the appropriate image features. This simple strategy amplifies disease-relevant regions while suppressing background interference. Without any additional pixel-level annotations, DAP improves visual grounding accuracy by 20.74\% compared to state-of-the-art methods across three major chest X-ray datasets.