UniDxMD: Towards Unified Representation for Cross-Modal Unsupervised Domain Adaptation in 3D Semantic Segmentation
 Highlight
Highlight
{kind=link}
Abstract
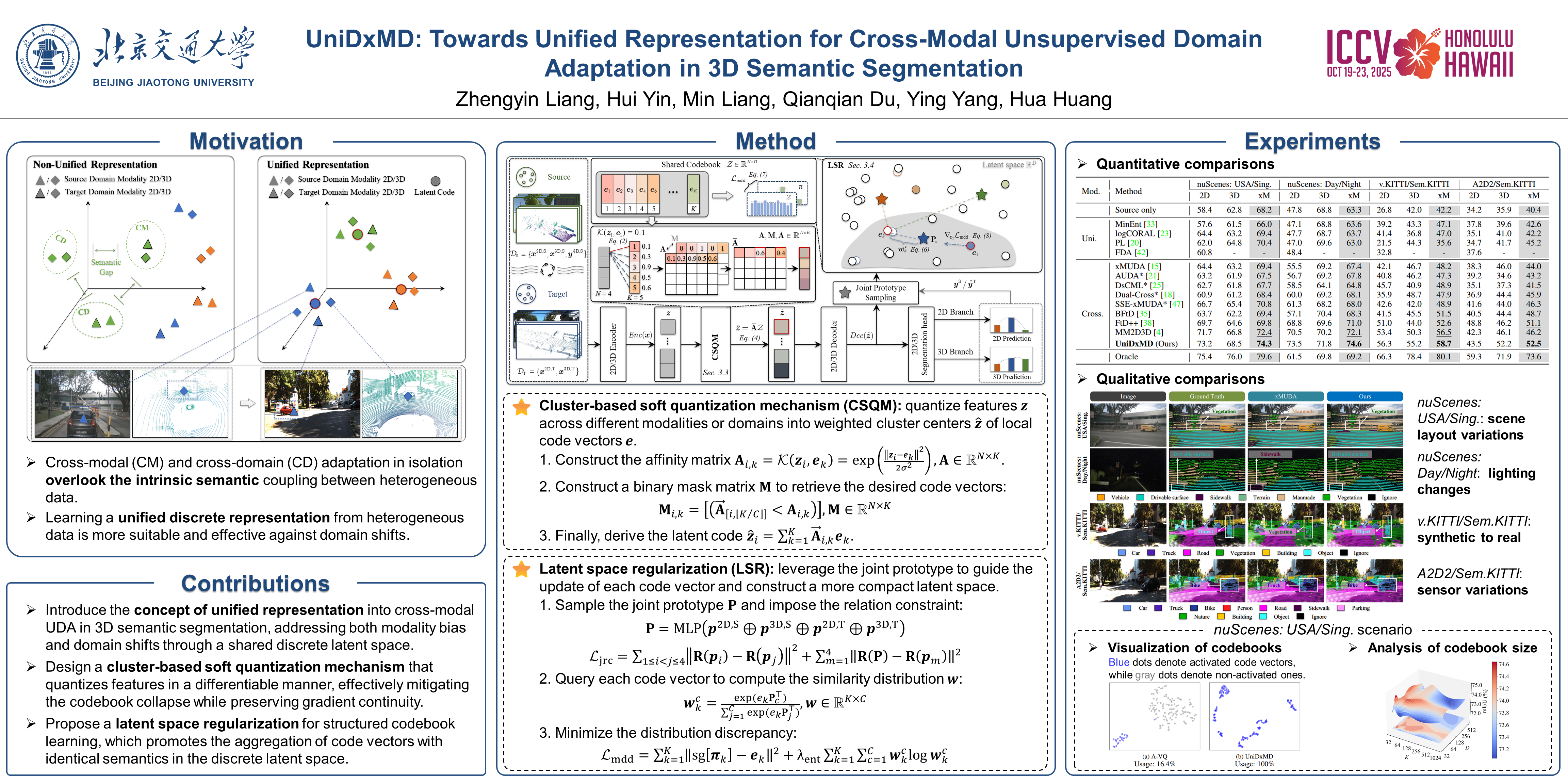
Modality or domain distribution shifts pose formidable challenges in 3D semantic segmentation. Existing methods predominantly address either cross-modal or cross-domain adaptation in isolation, leading to insufficient exploration of semantic associations and complementary features in heterogeneous data. To bridge this gap, we present UniDxMD, a unified representation method for cross-modal unsupervised domain adaptation (UDA) in 3D semantic segmentation that simultaneously tackles both cross-modal and cross-domain adaptation objectives. Our core insight is deriving a unified discrete representation from heterogeneous data to mitigate distribution shifts, inspired by vector quantization. Specifically, we propose a differentiable, cluster-based soft quantization mechanism (CSQM) that maps heterogeneous data (spanning modalities and domains) into a shared discrete latent space. Then, we introduce latent space regularization (LSR), leveraging joint prototypes that satisfy semantic relational consistency as learnable anchors to enhance the compactness and semantic discriminability of the discrete latent space. Our method paves the way for advancing cross-modal UDA in 3D semantic segmentation towards the unified representation. Extensive results across four challenging cross-modal UDA scenarios demonstrate the superiority of our method, achieving state-of-the-art performance on multiple benchmarks. Code will be available publicly.