GECKO: Gigapixel Vision-Concept Contrastive Pretraining in Histopathology
 Highlight
Highlight
{kind=link}
Abstract
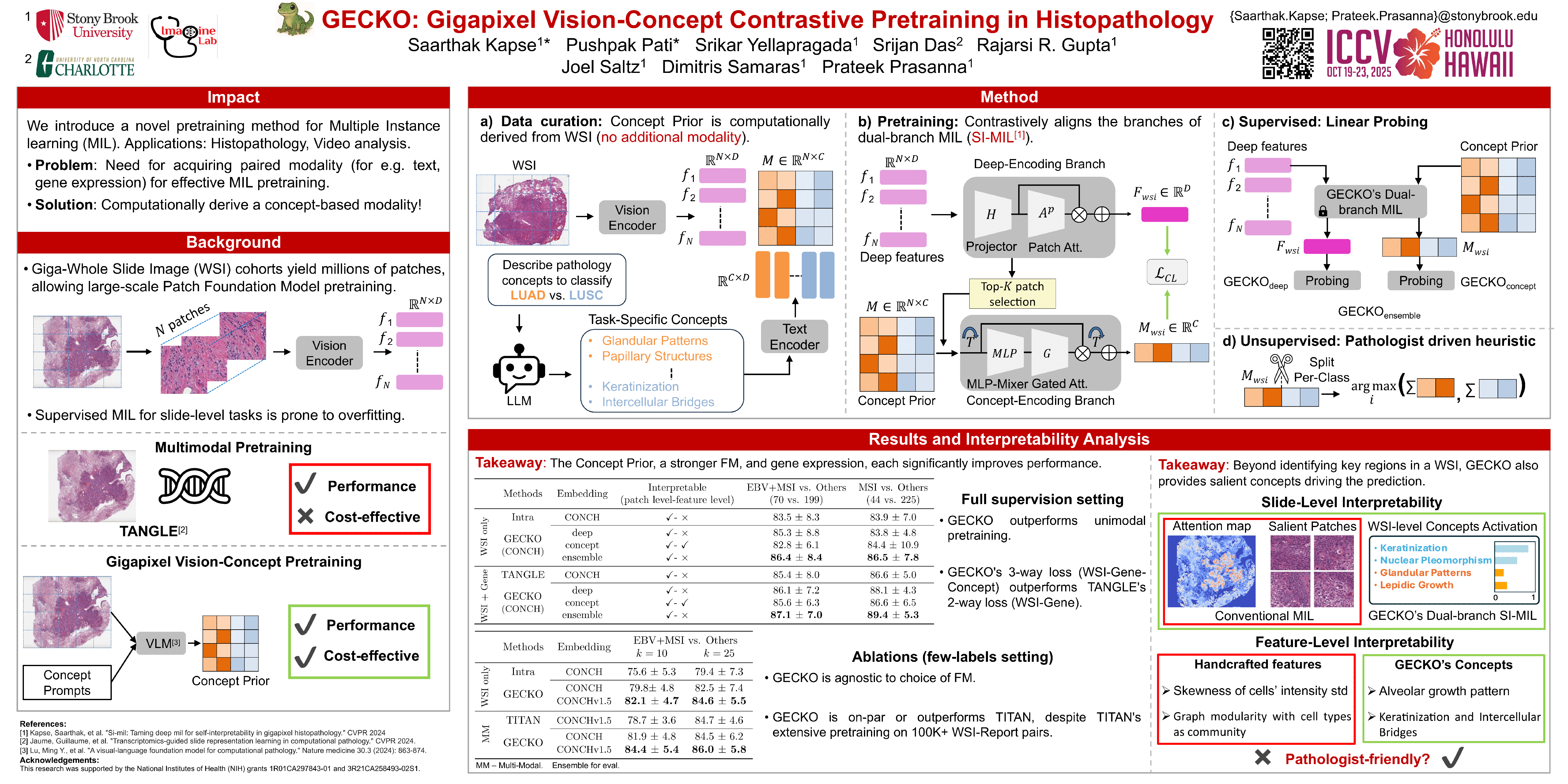
Pretraining a Multiple Instance Learning (MIL) aggregator enables the derivation of Whole Slide Image (WSI)-level embeddings from patch-level representations without supervision. While recent multimodal MIL pretraining approaches leveraging auxiliary modalities have demonstrated performance gains over unimodal WSI pretraining, the acquisition of these additional modalities necessitates extensive clinical profiling. This requirement increases costs and limits scalability in existing WSI datasets lacking such paired modalities. To address this, we propose Gigapixel Vision-Concept Knowledge Contrastive pretraining (GECKO), which aligns WSIs with a Concept Prior derived from the available WSIs. First, we derive an inherently interpretable concept prior by computing the similarity between each WSI patch and textual descriptions of predefined pathology concepts. GECKO then employs a dual-branch MIL network: one branch aggregates patch embeddings into a WSI-level deep embedding, while the other aggregates the concept prior to a corresponding WSI-level concept embedding. Both aggregated embeddings are aligned using a contrastive objective, thereby pretraining the entire dual-branch MIL model. Moreover, when auxiliary modalities such as transcriptomics data are available, GECKO seamlessly integrates them. Across five diverse tasks, GECKO consistently outperforms prior unimodal and multimodal pretraining approaches while also delivering clinically meaningful interpretability that bridges the gap between computational models and pathology expertise.