F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
 Highlight
Highlight
{kind=link}
Abstract
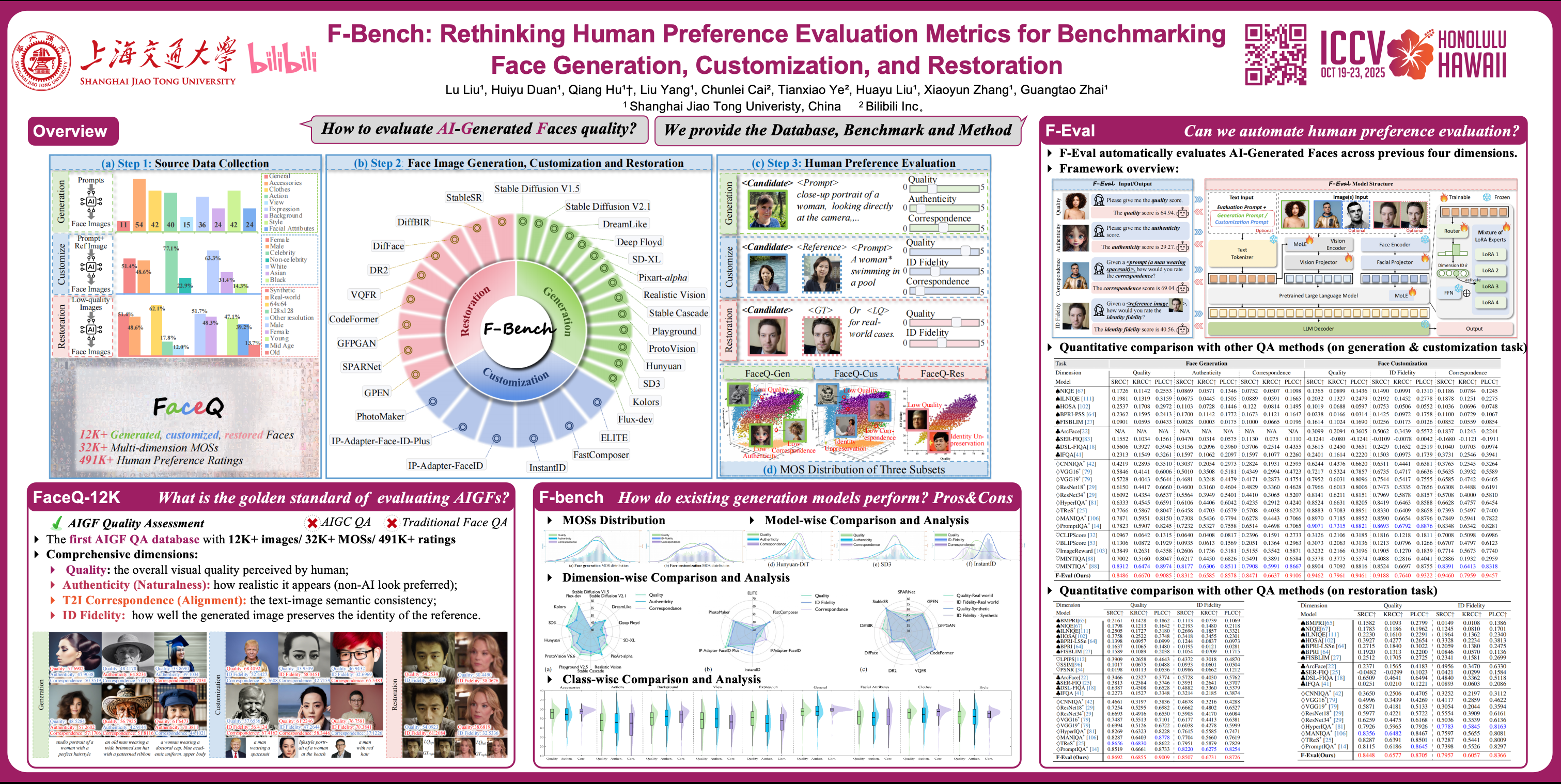
Recent artificial intelligence (AI) generative models have demonstrated remarkable capabilities in image production, and have been widely applied to face image generation, customization, and restoration. However, many AI-generated faces (AIGFs) still suffer from issues such as unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation method for AIGFs. To this end, we introduce FaceQ, the first comprehensive AI-generated Face image database with fine-grained Quality annotations aligned with human preferences, which consists of 12K images and 491K ratings across multiple dimensions. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA) methods on FaceQ, and further propose a large multimodal model (LMM) based Face quality Evaluator (F-Eval) to accurately assess the multi-dimensional quality of generated faces in a one-for-all manner. Extensive experimental results demonstrate the state-of-the-art performance of our F-Eval. FaceQ, F-Bench, and F-Eval will be publicly available upon publication.