Unified Video Generation via Next-Set Prediction in Continuous Domain
{kind=link}
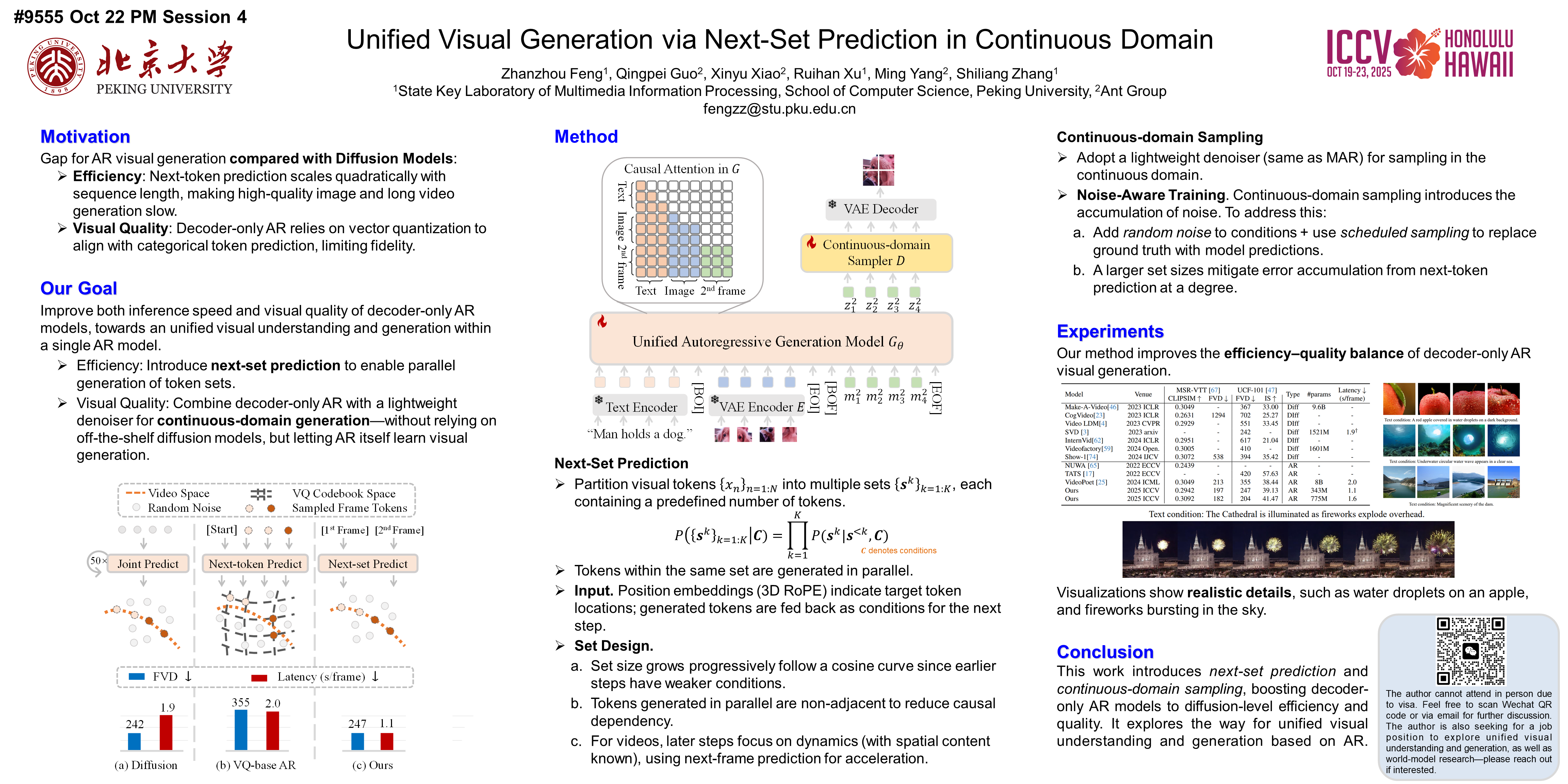
Abstract
Existing video generation strategies can be categorized into two categories, i.e., the diffusion and autoregressive (AR) methods. While AR methods achieves high efficiency by predicting the next token based on known visual cues, they generally fall short of diffusion models in terms of video quality. To bridge this gap, this paper introduces a novel continuous-domain next-set prediction strategy.Our approach groups related tokens to be generated into one single set, and simultaneously predicts their probability distributions, thereby better exploiting their spatial and temporal dependencies. Specifically, we propose two token partitioning strategies: Spatial Progressive Partitioning for image tokens and Temporal Next-Frame Partitioning for video tokens. Additionally, we construct a denoising sampler to generate outputs from the token set distribution within a continuous domain. This method unifies image and video generation under a cohesive next-set prediction framework.Experimental results indicate that our method achieves video quality comparable to recent diffusion models, while significantly reducing inference costs. Notably, our method surpasses the recent next token prediction approach Emu3, in video quality despite using approximately 90\% fewer parameters. Visualizations further confirm the effectiveness of our method in capturing intricate details and movements, such as water droplets and facial expressions.All implementations will be released.