Towards Fine-grained Interactive Segmentation in Images and Videos
{kind=link}
Abstract
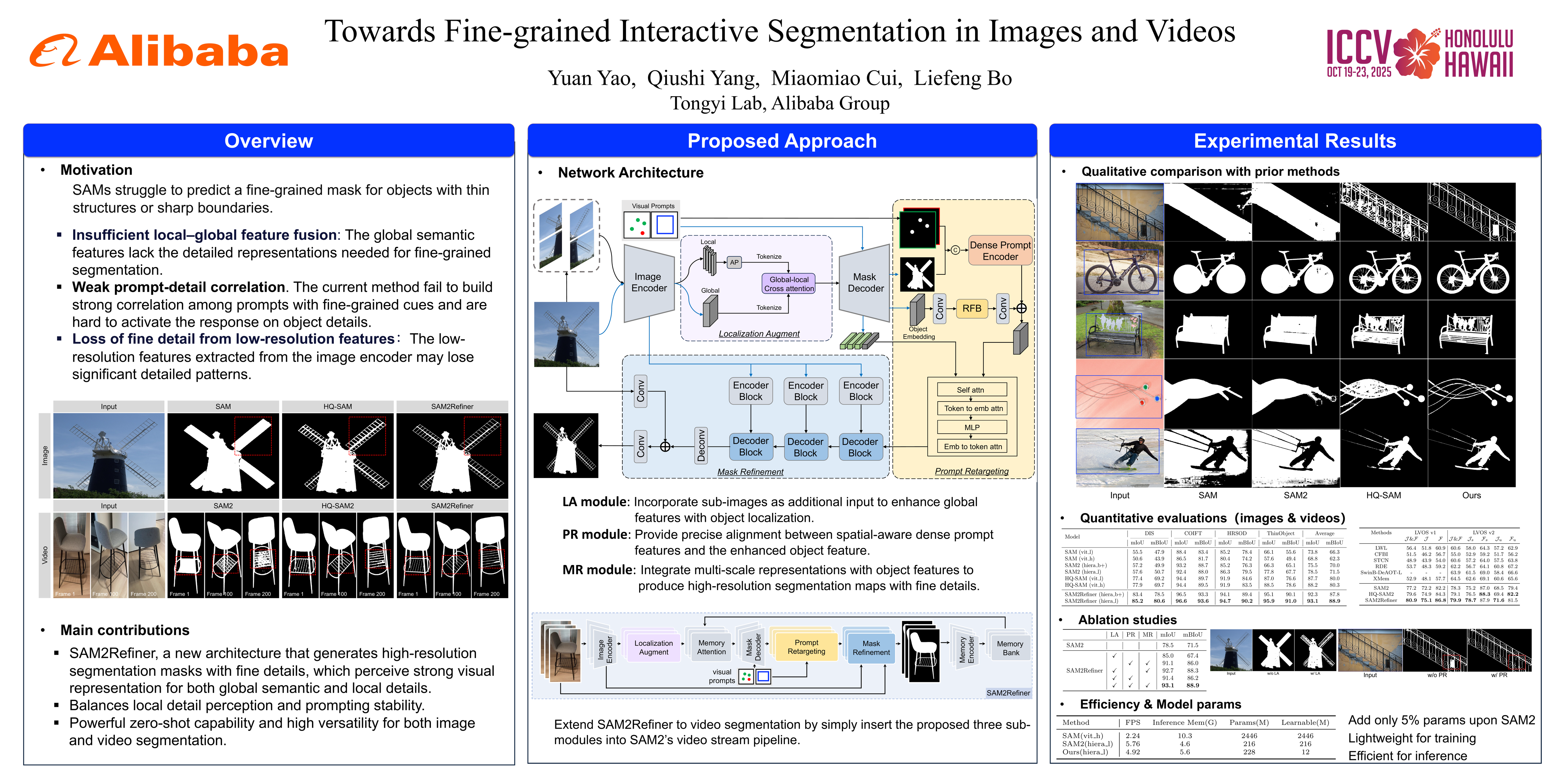
The recent Segment Anything Models (SAMs) have emerged as foundational visual models for general interactive segmentation. Despite demonstrating robust generalization abilities, they still suffer from performance degradations in scenarios that demand accurate masks. Existing methods for high-precision interactive segmentation face a trade-off between perceiving intricate local details and maintaining stable prompting capability, which hinders the applicability and effectiveness of foundational segmentation models. In this paper, we present a SAM2Refiner framework built upon the SAM2 backbone. This architecture allows SAM2 to generate fine-grained segmentation masks for both images and videos while preserving its inherent strengths. Specifically, we design a localization augment module, which incorporates local contextual cues to enhance global features via a cross-attention mechanism, thereby exploiting potential detailed patterns while maintaining semantic information. Moreover, to strengthen the prompting ability toward the enhanced object embeddings, we introduce a prompt retargeting module that renews the embedding with spatially aligned prompt features. In addition, to obtain accurate high resolution segmentation masks, a mask refinement module is devised by employing a multi-scale cascaded structure to fuse mask features with hierarchical representations from the encoder. Extensive experiments demonstrate the effectiveness of our approach, revealing that the proposed method can produce highly precise masks for both images and videos, surpassing state-of-the-art methods.