VLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
{kind=link}
Abstract
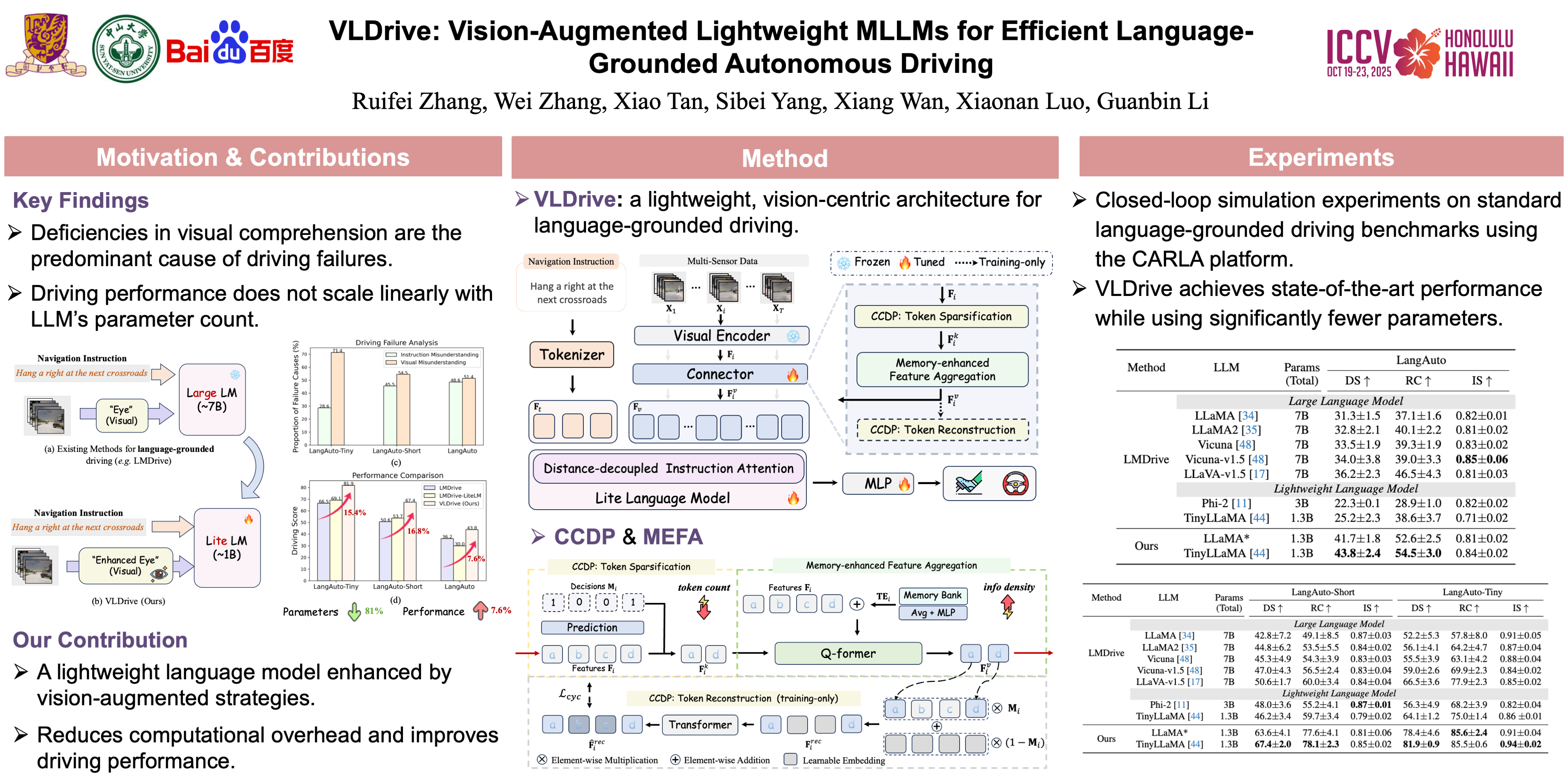
Recent advancements in language-grounded autonomous driving have been significantly promoted by the sophisticated cognition and reasoning capabilities of large language models (LLMs). However, current LLM-based approaches encounter critical challenges: (1) Failure analysis reveals that frequent collisions and obstructions, stemming from limitations in visual representations, remain primary obstacles to robust driving performance. (2) The substantial parameters of LLMs poses considerable deployment hurdles. To address these limitations, we introduce VLDrive, a novel approach featuring a lightweight MLLM architecture with enhanced vision components. VLDrive achieves compact visual tokens through innovative strategies, including cycle-consistent dynamic visual pruning and memory-enhanced feature aggregation. Furthermore, we propose a distance-decoupled instruction attention mechanism to improve joint visual-linguistic feature learning, particularly for long-range visual tokens. Extensive experiments conducted in the CARLA simulator demonstrate VLDrive's effectiveness. Notably, VLDrive achieves state-of-the-art driving performance while reducing parameters by 81\% (from 7B to 1.3B), yielding substantial driving score improvements of \textbf{15.4}\%, \textbf{16.8}\%, and \textbf{7.6}\% at tiny, short, and long distances, respectively, in closed-loop evaluations.