FOLDER: Accelerating Multi-Modal Large Language Models with Enhanced Performance
{kind=link}
Abstract
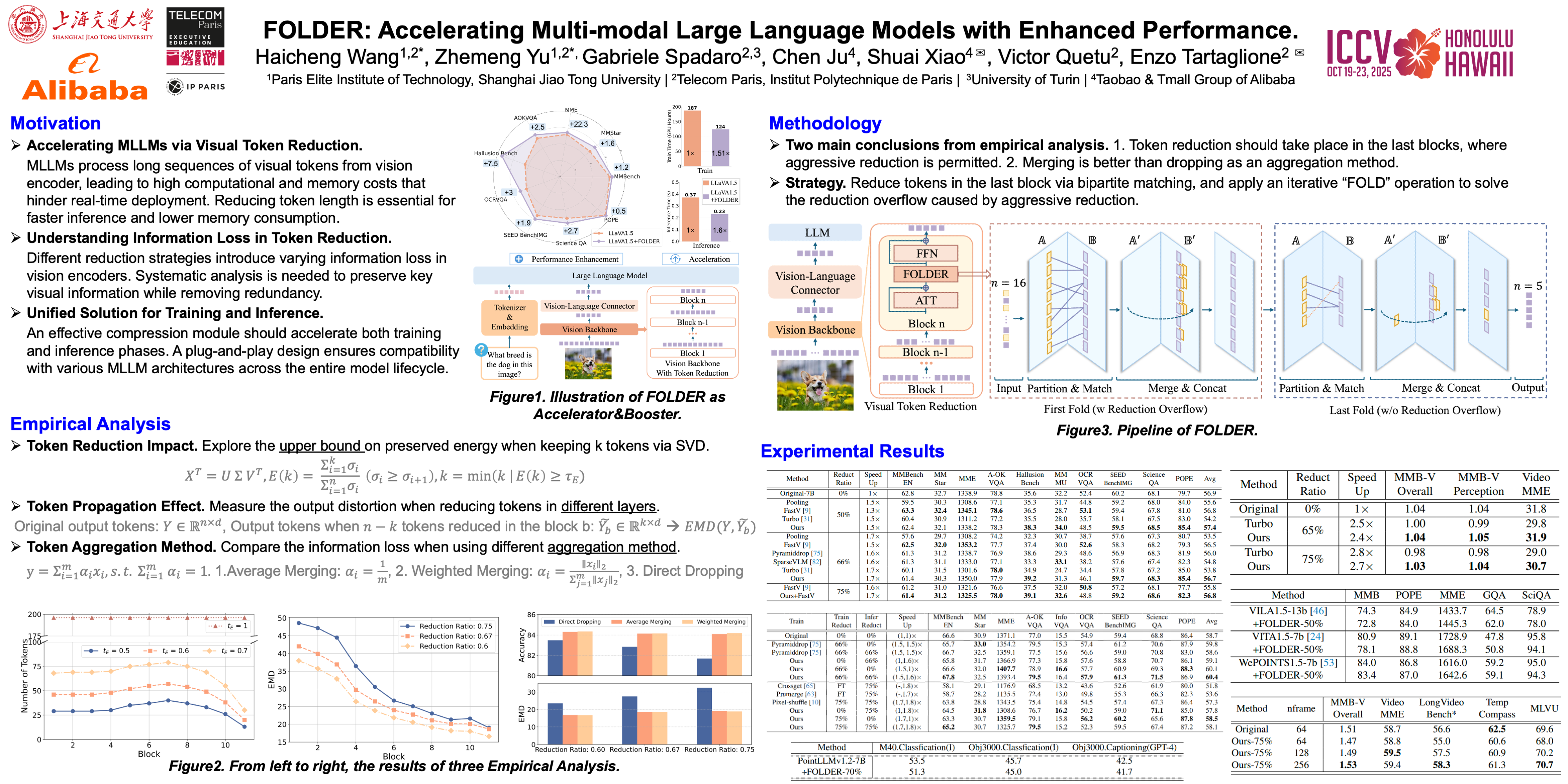
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating computational and memory demands during both training and inference. Through a comprehensive analysis of the token reduction process in vision encoder, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We show the effectiveness of FOLDER by integrating it into the visual backbone of various MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens. The source code will be open-sourced upon acceptance of the article.