Beyond Label Semantics: Language-Guided Action Anatomy for Few-shot Action Recognition
{kind=link}
Abstract
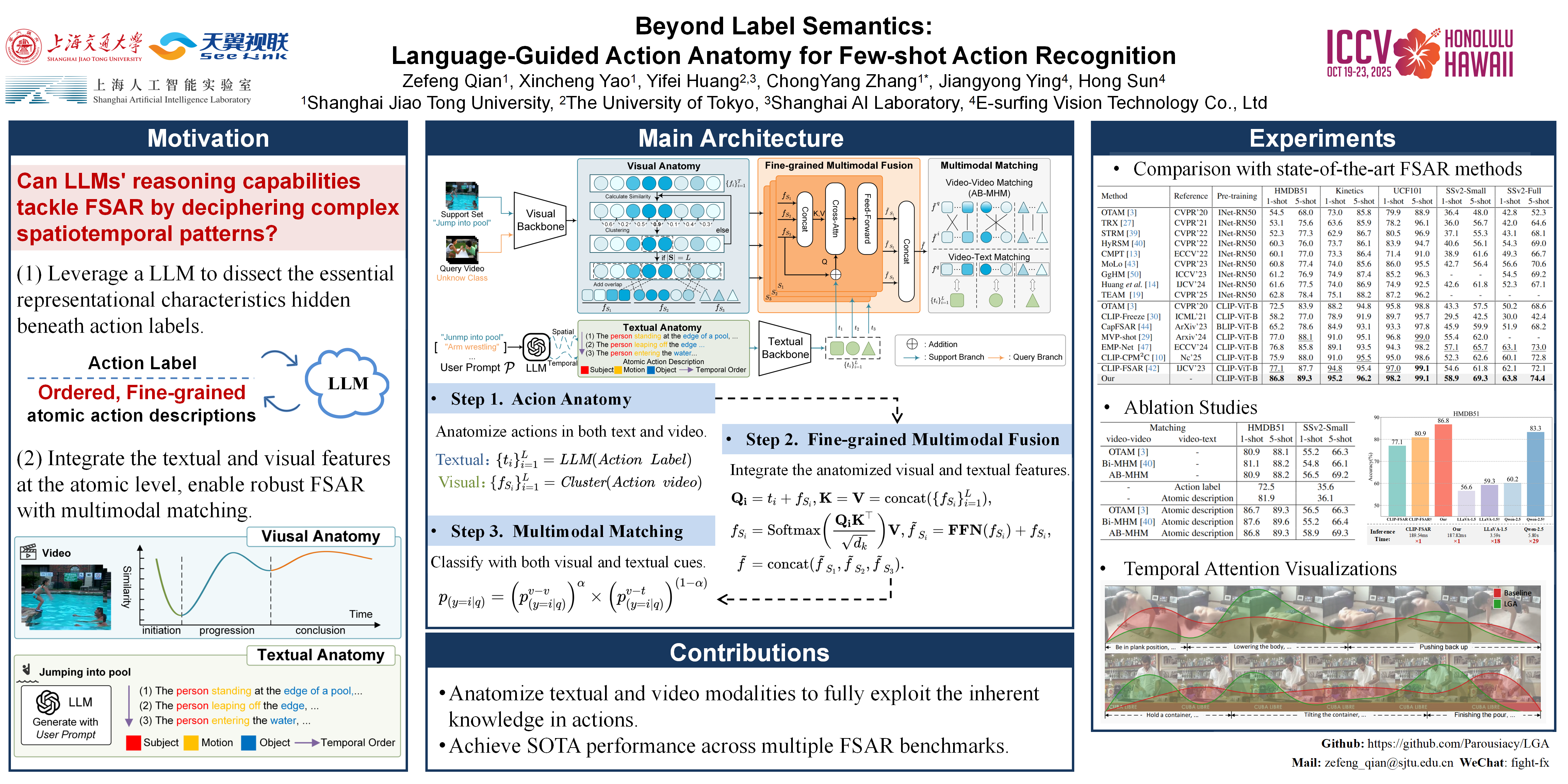
Few-shot action recognition (FSAR) aims to classify human actions in videos with only a small number of labeled samples per category. The scarcity of training data has driven recent efforts to incorporate additional modalities, particularly text. However, the subtle variations in human posture, object interactions, and the motion dynamics that occur during different phases of an action, are critical inherent knowledge of actions that cannot be fully exploited by relying solely on text within action labels.In this work, we propose Language-Guided Action Anatomy (LGA), a novel framework for FSAR that goes beyond label semantics by modeling actions at a finer granularity. LGA anatomizes both the textual and visual modalities, effectively exploring rich spatiotemporal cues across different temporal phases of actions.For text, prompt an off-the-shelf Large Language Model to anatomize labels into sequences of atomic action descriptions, focusing on the three core elements of action (subject, motion, object).For videos, we design a Visual Anatomy Module to segment actions into atomic video phases, capturing the sequential structure of actions.A fine-grained fusion strategy then integrates textual and visual features at the atomic level, resulting in more generalizable prototypes. Finally, we introduce a Multimodal Matching mechanism, comprising both video-video and video-text matching, to ensure robust few-shot classification. Experimental results demonstrate that LGA achieves state-of-the-art performance across multiple FSAR benchmarks.