Vision-Language Interactive Relation Mining for Open-Vocabulary Scene Graph Generation
{kind=link}
Abstract
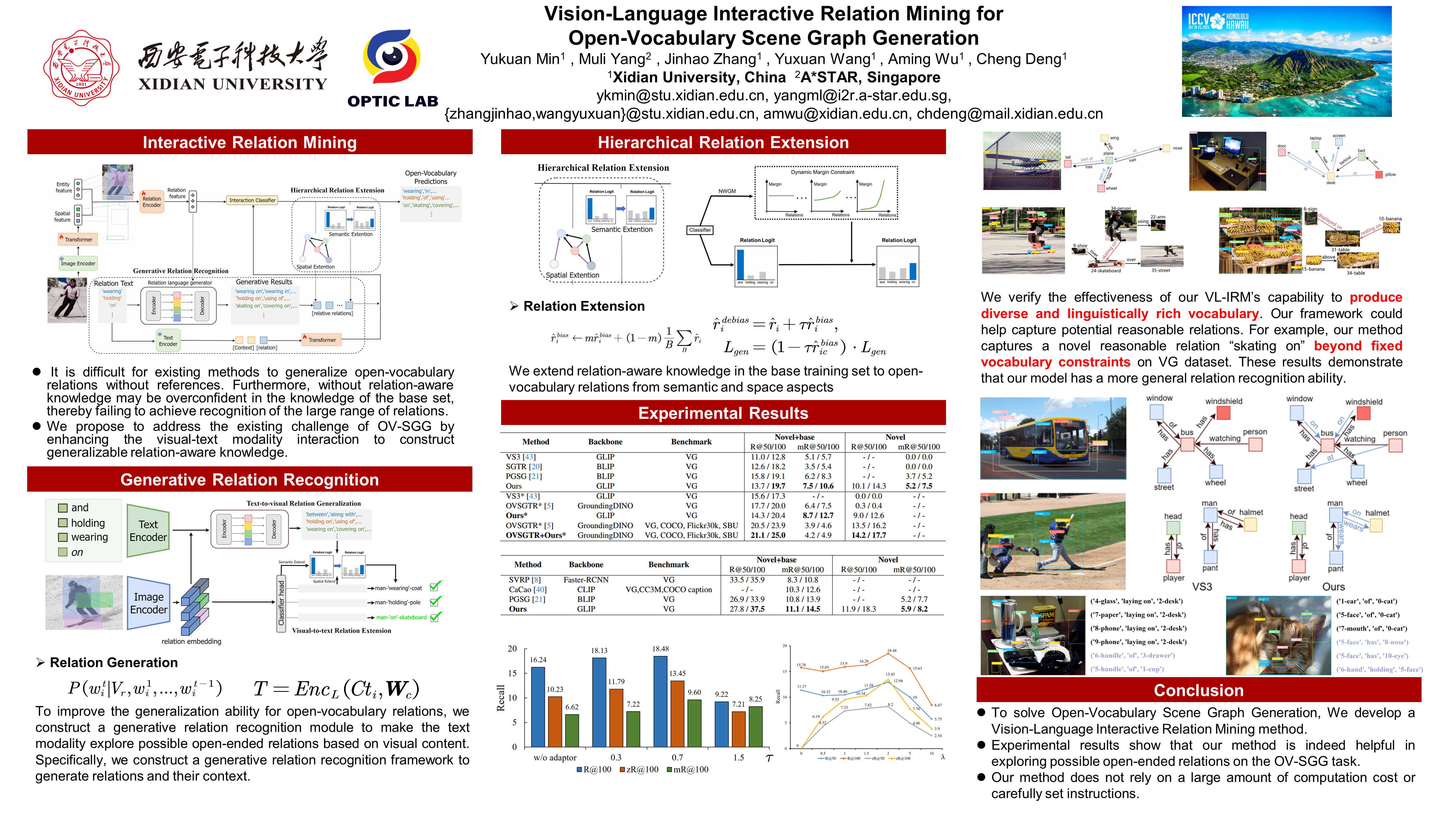
To promote the deployment of scenario understanding in the real world, Open-Vocabulary Scene Graph Generation (OV-SGG) has attracted much attention recently, aiming to generalize beyond the limited number of relation categories labeled during training and detect those unseen relations during inference. Towards OV-SGG, one feasible solution is to leverage the large-scale pre-trained vision-language models (VLMs) containing plentiful category-level content to capture accurate correspondences between images and text. However, due to the lack of quadratic relation-aware knowledge in VLMs, directly using the category-level correspondence in the base dataset could not sufficiently represent generalized relations involved in open world. Therefore, designing an effective open-vocabulary relation mining framework is challenging and meaningful. To this end, we propose a novel Vision-Language Interactive Relation Mining model (VL-IRM) for OV-SGG, which explores learning generalized relation-aware knowledge through multi-modal interaction. Specifically, first, to enhance the generalization of the relation text to visual content, we present a generative relation model to make the text modality explore possible open-ended relations based on visual content. Then, we employ visual modality to guide the relation text for spatial and semantic extension. Extensive experiments demonstrate the superior OV-SGG performance of our method.