A Lesson in Splats: Teacher-Guided Diffusion for 3D Gaussian Splats Generation with 2D Supervision
{kind=link}
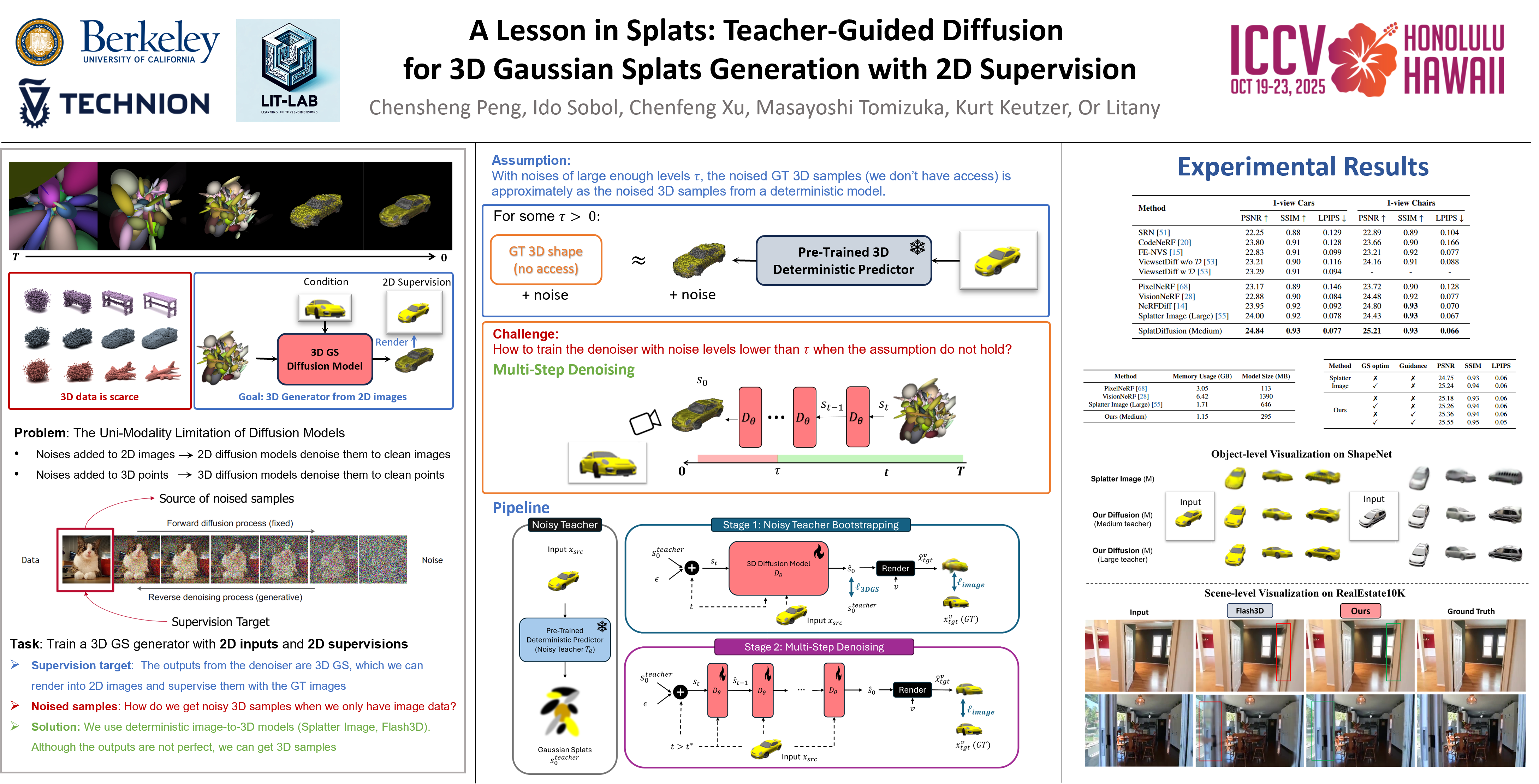
Abstract
We present a novel framework for training 3D image-conditioned diffusion models using only 2D supervision. Recovering 3D structure from 2D images is inherently ill-posed due to the ambiguity of possible reconstructions, making generative models a natural choice. However, most existing 3D generative models rely on full 3D supervision, which is impractical due to the scarcity of large-scale 3D datasets. To address this, we propose leveraging sparse-view supervision as a scalable alternative. While recent reconstruction models use sparse-view supervision with differentiable rendering to lift 2D images to 3D, they are predominantly deterministic, failing to capture the diverse set of plausible solutions and producing blurry predictions in uncertain regions. A key challenge in training 3D diffusion models with 2D supervision is that the standard training paradigm requires both the denoising process and supervision to be in the same modality. We address this by decoupling the noisy samples being denoised from the supervision signal, allowing the former to remain in 3D while the latter is provided in 2D. Our approach leverages suboptimal predictions from a deterministic image-to-3D model—acting as a "teacher"—to generate noisy 3D inputs, enabling effective 3D diffusion training without requiring full 3D ground truth. We validate our framework on both object-level and scene-level datasets, using two different 3D Gaussian Splat (3DGS) teachers. Our results show that our approach consistently improves upon these deterministic teachers, demonstrating its effectiveness in scalable and high-fidelity 3D generative modeling.