HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
{kind=link}
Abstract
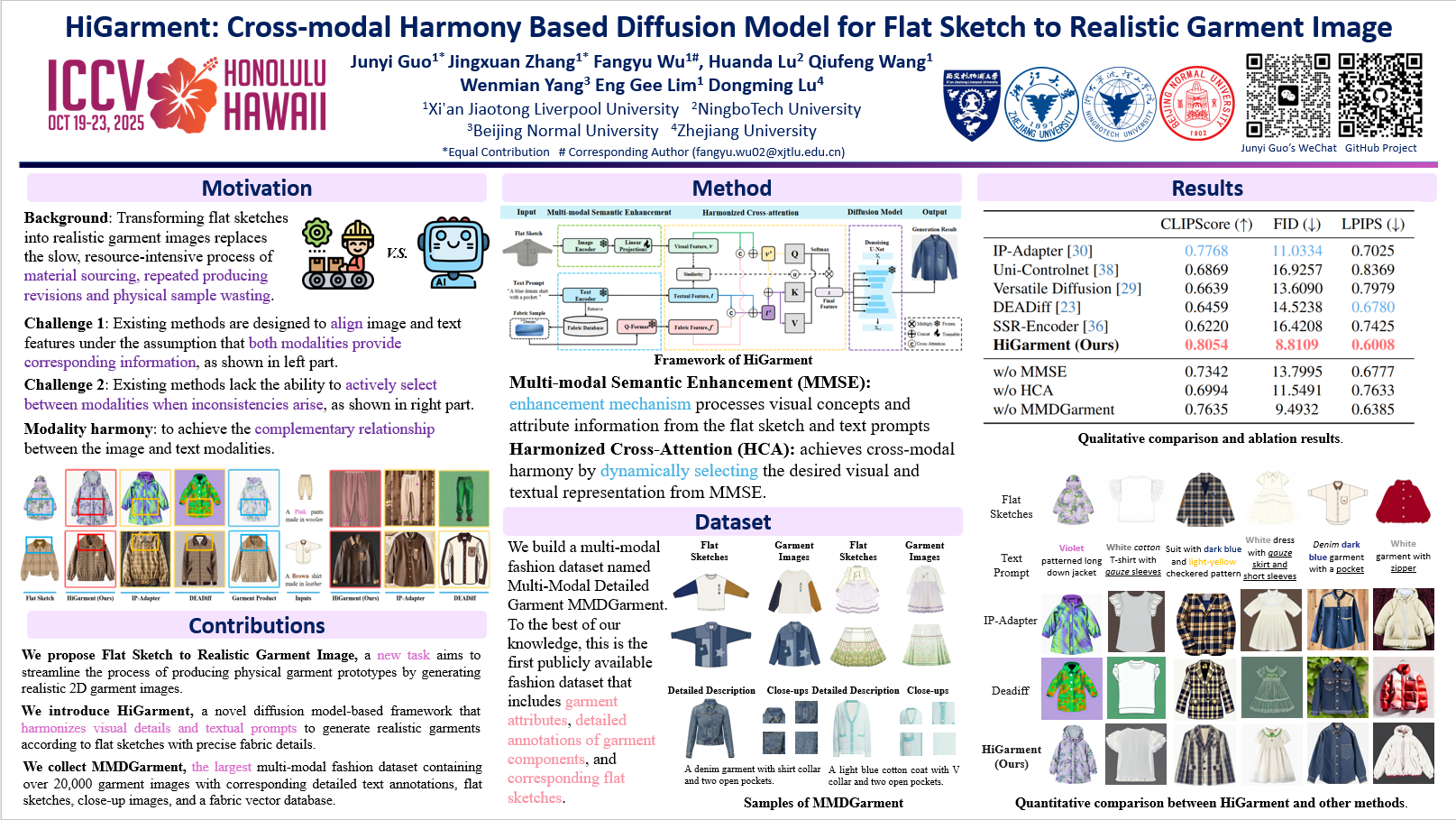
Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence.To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.