SemTalk: Holistic Co-speech Motion Generation with Frame-level Semantic Emphasis
{kind=link}
Abstract
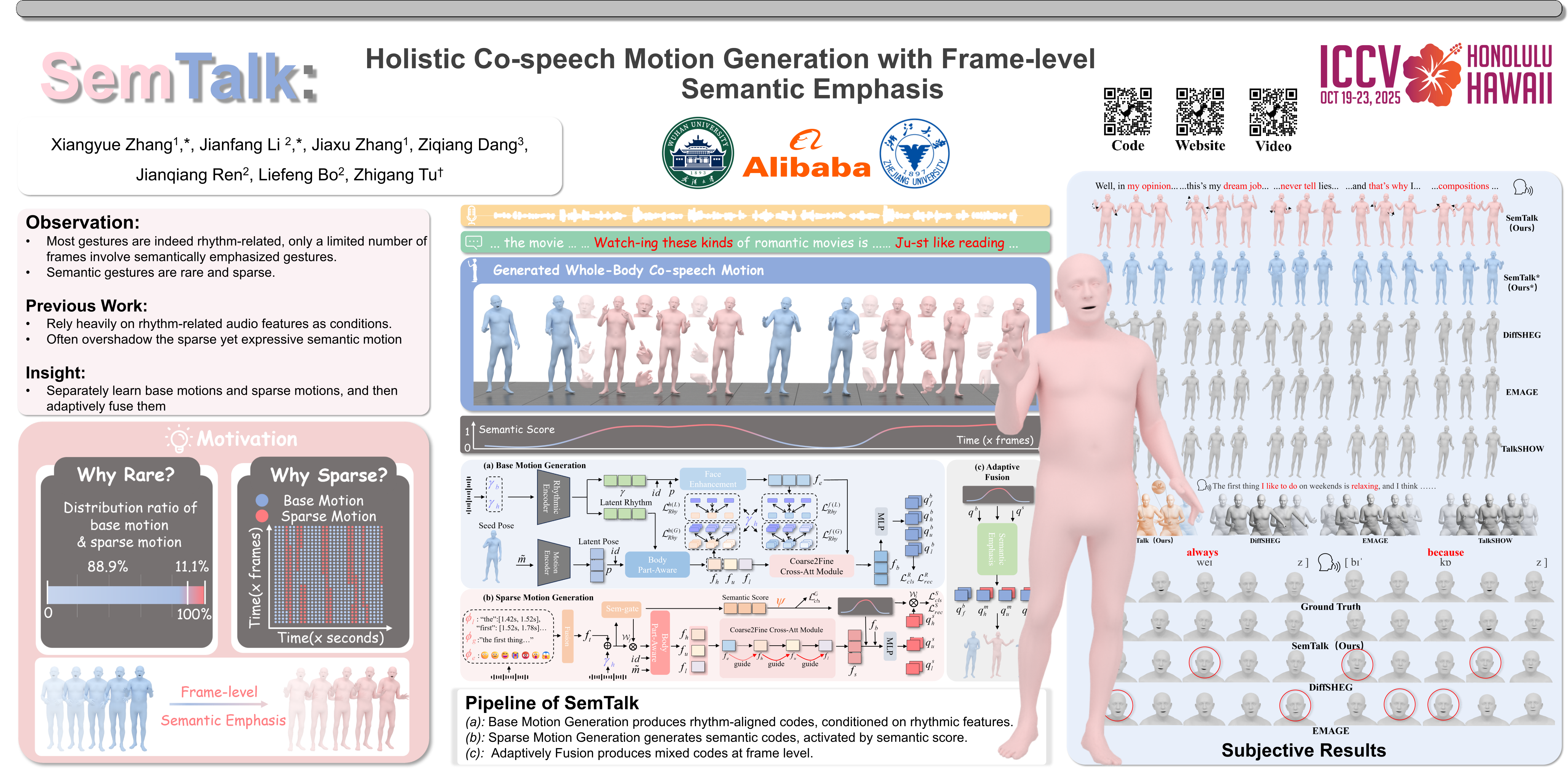
A good co-speech motion generation cannot be achieved without a careful integration of common rhythmic motion and rare yet essential semantic motion. In this work, we propose SemTalk for holistic co-speech motion generation with frame-level semantic emphasis. Our key insight is to separately learn base motions and sparse motions, and then adaptively fuse them. In particular, coarse2fine cross-attention module and rhythmic consistency learning are explored to establish rhythm-related base motion, ensuring a coherent foundation that synchronizes gestures with the speech rhythm. Subsequently, semantic emphasis learning is designed to generate semantic-aware sparse motion, focusing on frame-level semantic cues. Finally, to integrate sparse motion into the base motion and generate semantic-emphasized co-speech gestures, we further leverage a learned semantic score for adaptive synthesis. Qualitative and quantitative comparisons on two public datasets demonstrate that our method outperforms the state-of-the-art, delivering high-quality co-speech motion with enhanced semantic richness over a stable base motion.