TITAN-Guide: Taming Inference-Time Alignment for Guided Text-to-Video Diffusion Models
{kind=link}
Abstract
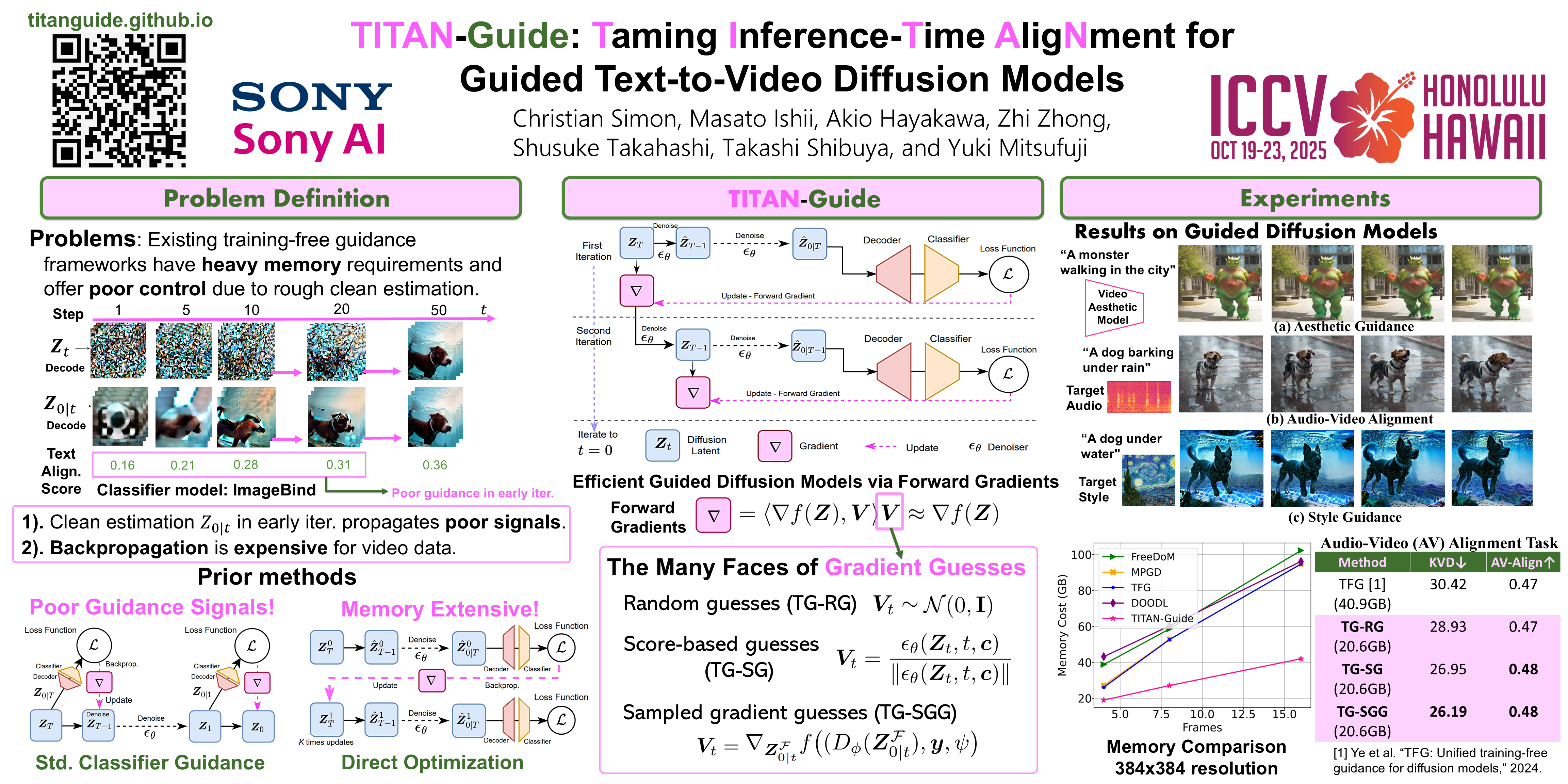
In the recent development of conditional diffusion models still require heavy supervised fine-tuning for performing control on a category of tasks. Training-free conditioning via guidance with off-the-shelf models is a favorable alternative to avoid further fine-tuning on the base model. However, the existing training-free guidance frameworks either heavy memory requirements or sub-optimal control due to rough estimation. These shortcomings limit the applicability to control diffusion models that require intense computation, such as Text-to-Video (T2V) diffusion models. In this work, we propose Taming Inference Time Alignment for Guided Text-to-Video Diffusion Model, so-called TITAN-Guide, which overcomes memory space issues, and provides more optimal control in the guidance process compared to the counterparts. In particular, we develop an efficient method for optimizing diffusion latents without backpropagation from a discriminative guiding model. In particular, we study forward gradient descents for guided diffusion tasks with various options on directional directives. In our experiments, we demonstrate the effectiveness of our approach in efficiently managing memory during latent optimization, while previous methods fall short. Our proposed approach not only minimizes memory requirements but also significantly enhances T2V performance across a range of diffusion guidance benchmarks.