MSQ: Memory-Efficient Bit Sparsification Quantization
{kind=link}
Abstract
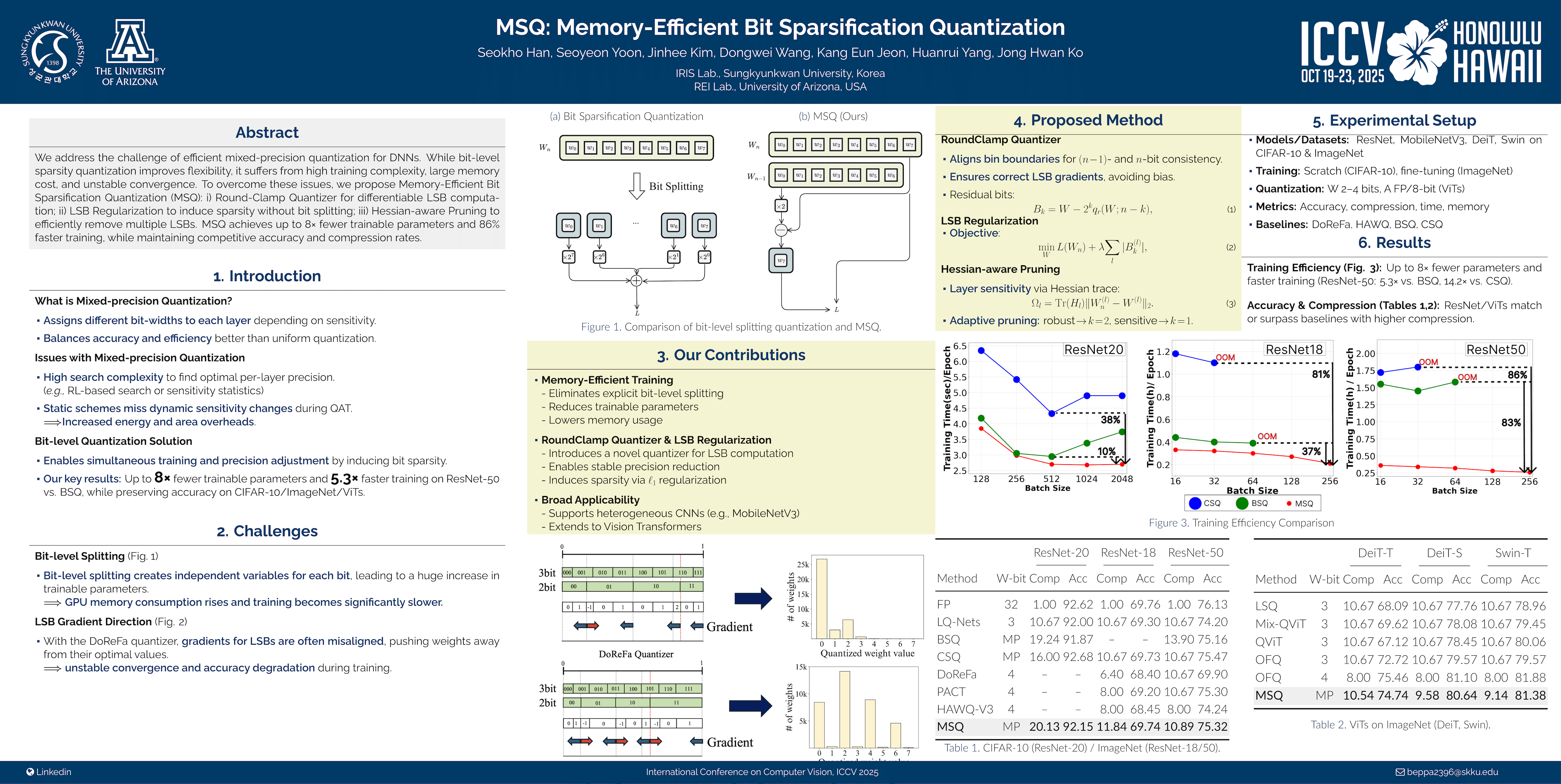
As deep neural networks (DNNs) see increased deployment on mobile and edge devices, optimizing model efficiency has become crucial. Mixed-precision quantization is widely favored, as it offers a superior balance between efficiency and accuracy compared to uniform quantization. However, finding the optimal precision for each layer is challenging. Recent studies using bit-level training have shown promise, yet they often introduce substantial training complexity and high GPU memory requirements. In this paper, we propose Memory-Efficient Bit Sparsification Quantization (MSQ), a novel approach that addresses these limitations. MSQ applies a round-clamp quantizer and leverages least significant bit (LSB) regularization to induce sparsity in LSBs, enabling effective precision reduction without splitting parameters at the bit level, thereby minimizing memory use and training time. Additionally, MSQ incorporates Hessian information, allowing the simultaneous pruning of multiple LSBs to further enhance training efficiency. Experimental results show that MSQ effectively reduces resource demands while maintaining competitive accuracy and compression rates, making it a practical solution for training efficient DNNs on resource-constrained devices.