MV-Adapter: Multi-View Consistent Image Generation Made Easy
{kind=link}
Abstract
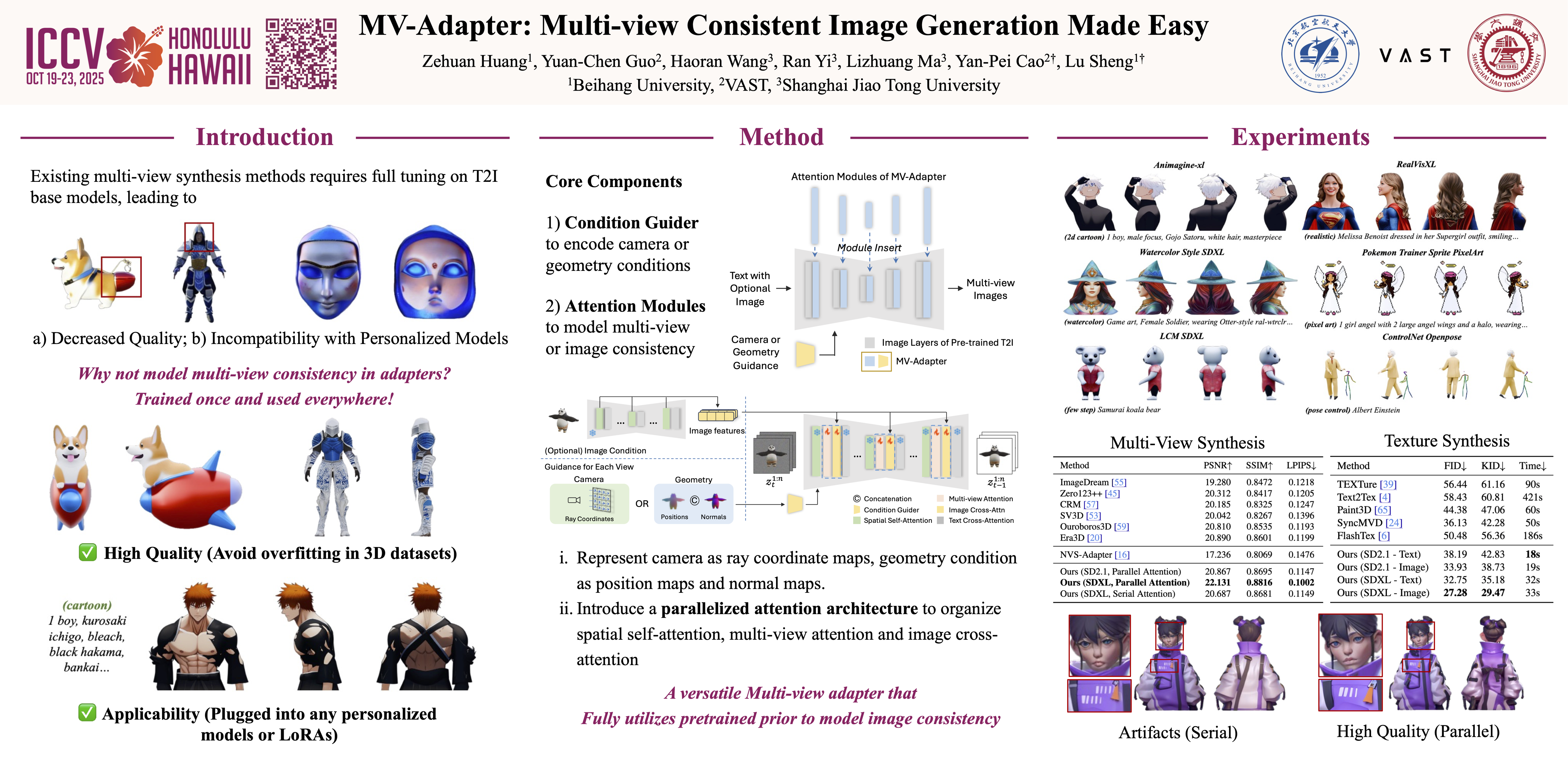
Existing multi-view image generation methods often make invasive modifications to pre-trained text-to-image (T2I) models and require full fine-tuning, leading to high computational costs and degradation in image quality due to scarce high-quality 3D data. This paper introduces MV-Adapter, an efficient and versatile adapter that enhances T2I models and their derivatives without altering the original network structure or feature space. To efficiently model the 3D geometric knowledge within the adapter, we introduce innovative designs that include duplicated self-attention layers and parallel attention architecture, enabling the adapter to inherit the powerful priors of the pre-trained models to model the novel 3D knowledge. Moreover, we present a unified condition encoder that seamlessly integrates camera parameters and geometric information, facilitating applications such as text- and image-based 3D generation and texturing. MV-Adapter achieves multi-view generation at 768 resolution on Stable Diffusion XL (SDXL), and demonstrates adaptability and versatility. It can also be extended to arbitrary view generation, enabling broader applications. We demonstrate that MV-Adapter sets a new quality standard for multi-view image generation, and opens up new possibilities due to its efficiency, adaptability and versatility.