MUG: Pseudo Labeling Augmented Audio-Visual Mamba Network for Audio-Visual Video Parsing
{kind=link}
Abstract
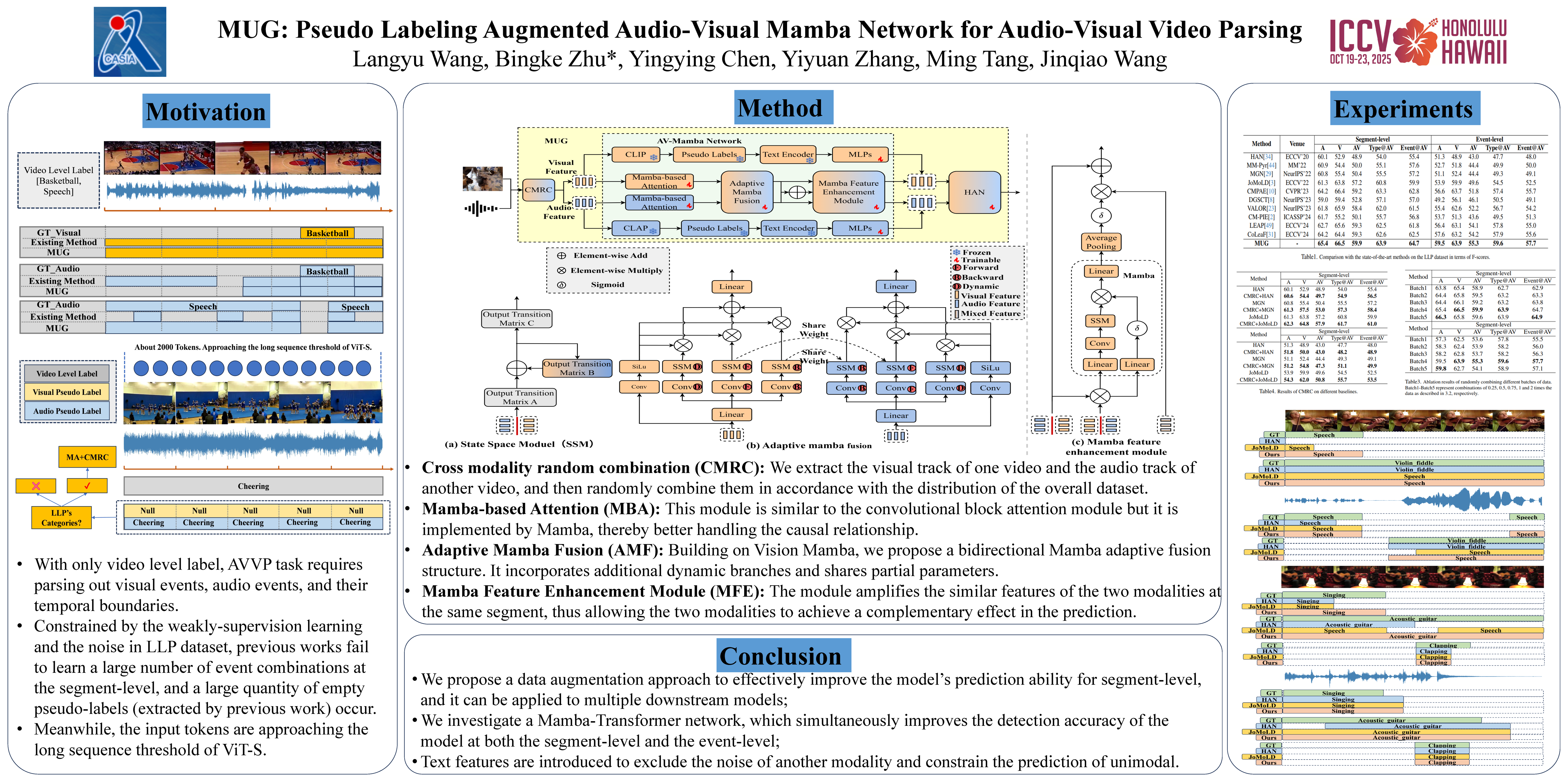
The weakly-supervised audio-visual video parsing (AVVP) aims to predict all modality-specific events and locate their temporal boundaries. Despite significant progress, due to the limitations of the weakly-supervised and the deficiencies of the model architecture, existing methods are lacking in simultaneously improving both the segment-level prediction and the event-level prediction. In this work, we propose a audio-visual Mamba network with pseudo labeling aUGmentation (MUG) for emphasising the uniqueness of each segment and excluding the noise interference from the alternate modalities. Specifically, we annotate some of the pseudo-labels based on previous work. Using unimodal pseudo-labels, we perform cross-modal random combinations to generate new data, which can enhance the model’s ability to parse various segment-level event combinations. For feature processing and interaction, we employ a audio-visual mamba network. The AV-Mamba enhances the ability to perceive different segments and excludes additional modal noise while sharing similar modal information. Our extensive experiments demonstrate that MUG improves state-of-the-art results on LLP dataset, especially in visual metrics (e.g., gains of 2.8\% and 1.1\% in terms of Segment-level visual and Event-level visual metrics).