MagicMirror: ID-Preserved Video Generation in Video Diffusion Transformers
{kind=link}
Abstract
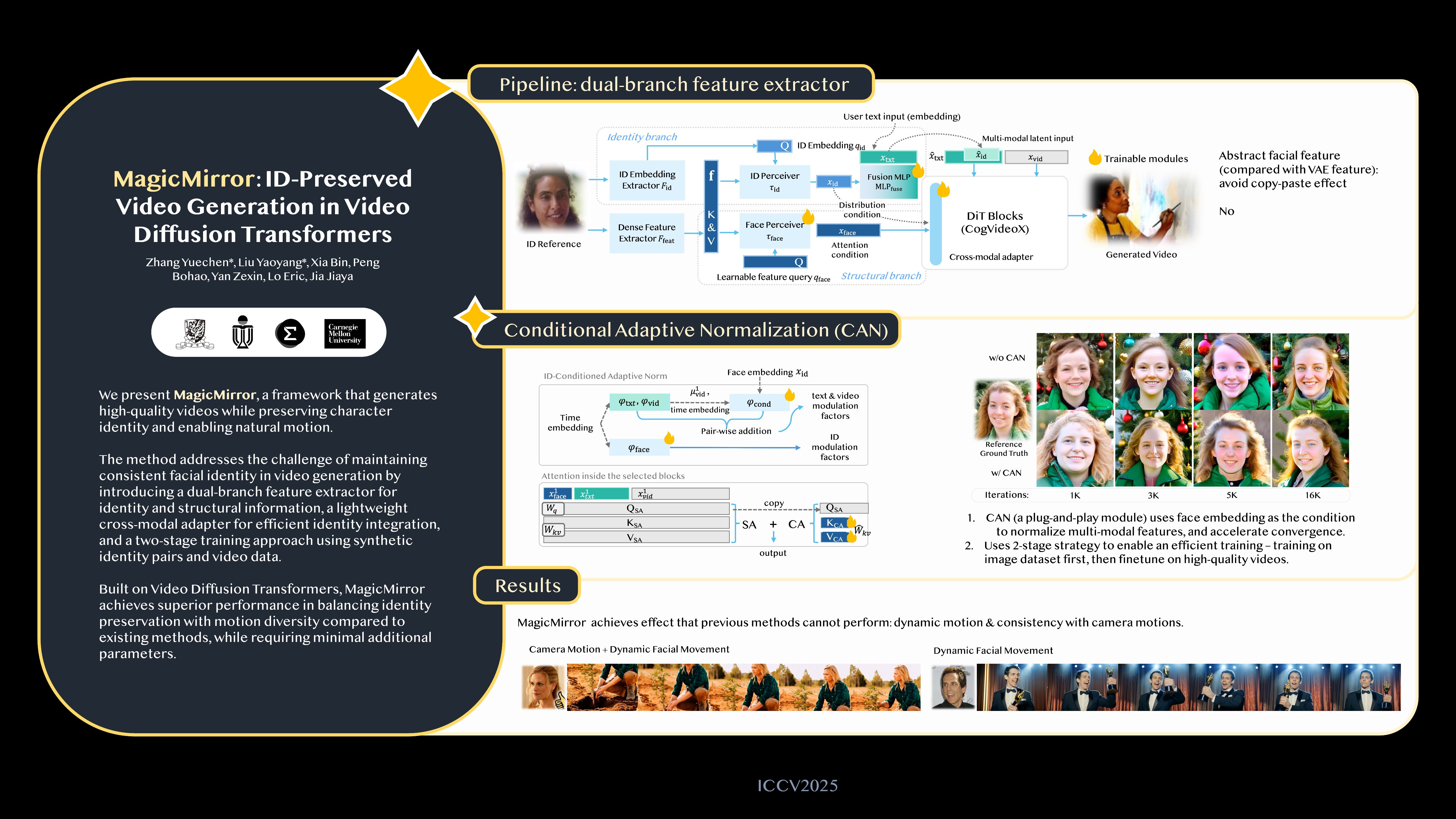
We present MagicMirror, a framework for generating identity-preserved videos with cinematic-level quality and dynamic motion. While recent advances in video diffusion models have shown impressive capabilities in text-to-video generation, maintaining consistent identity while producing natural motion remains challenging. Previous methods either require person-specific fine-tuning or struggle to balance identity preservation with motion diversity. Built upon Video Diffusion Transformers, our method introduces three key components: (1) a dual-branch facial feature extractor that captures both identity and structural features, (2) a lightweight cross-modal adapter with Conditioned Adaptive Normalization for efficient identity integration, and (3) a two-stage training strategy combining synthetic identity pairs with video data. Extensive experiments demonstrate that MagicMirror effectively balances identity consistency with natural motion, outperforming existing methods across multiple metrics while requiring minimal parameters added. The code and model will be made publicly available.