DACoN: DINO for Anime Paint Bucket Colorization with Any Number of Reference Images
{kind=link}
Abstract
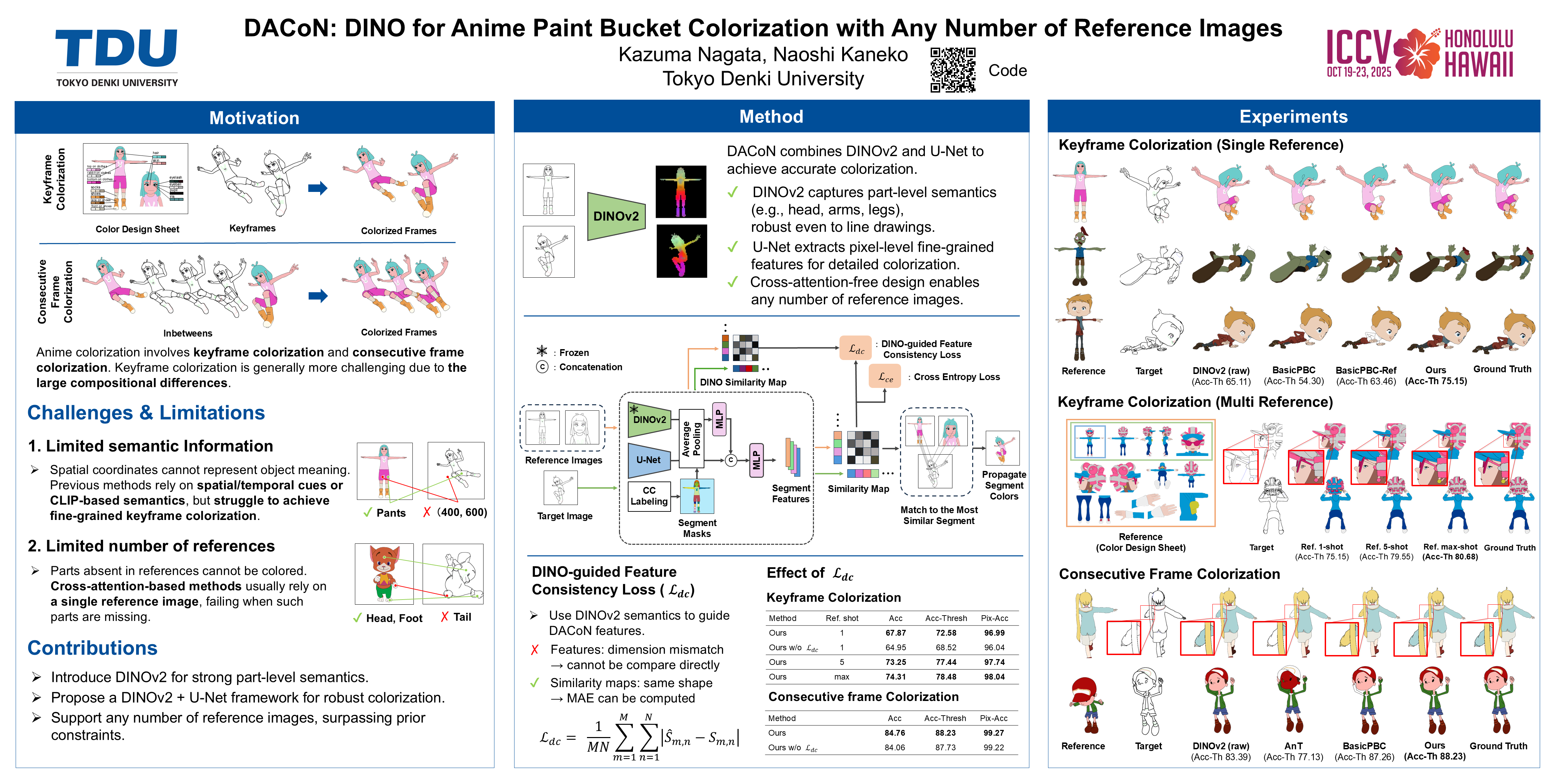
Automatic colorization methods for line drawings have been widely studied to reduce the labor cost of hand-drawn anime production. Deep learning approaches, including image/video generation and feature-based correspondence, have improved accuracy but struggle with occlusions, pose variations, and viewpoint changes. To address these challenges, we propose DACoN, a framework that leverages foundation models to capture part-level semantics, even in line drawings. Our method fuses low-resolution semantic features from foundation models with high-resolution spatial features from CNNs for fine-grained yet robust feature extraction.In contrast to previous methods that rely on Multiplex Transformer and support only one or two reference images, DACoN removes this constraint, allowing any number of references. Quantitative evaluations demonstrate the advantages of using multiple reference images, achieving superior colorization performance.Our code and model will be released upon acceptance.