LayerLock: Non-collapsing Representation Learning with Progressive Freezing
{kind=link}
Abstract
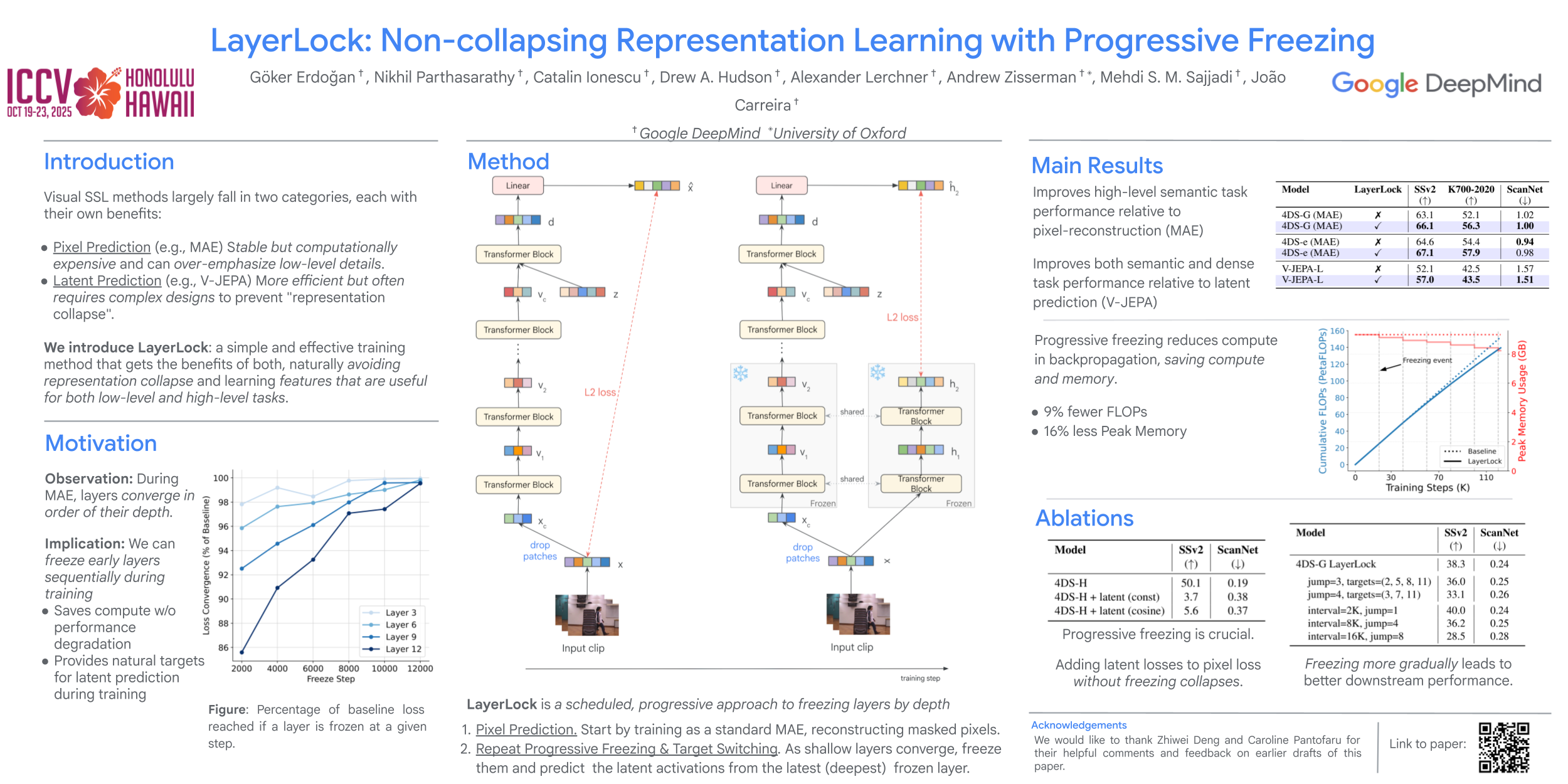
We introduce LayerLock, a simple yet effective approach for self-supervised visual representation learning, that gradually transitions from pixel to latent prediction through progressive layer freezing. First, we make the observation that during training of video masked-autoencoding (MAE) models, ViT layers converge in the order of their depth: shallower layers converge early, deeper layers converge late. We then show that this observation can be exploited to accelerate standard MAE by progressively freezing the model according to an explicit schedule, throughout training. Furthermore, this same schedule can be used in a simple and scalable approach to latent prediction that does not suffer from "representation collapse". We apply our proposed approach, LayerLock, to large models of up to 4B parameters with results surpassing those of non-latent masked prediction on the 4DS perception suite.