Boosting Multimodal Learning via Disentangled Gradient Learning
{kind=link}
Abstract
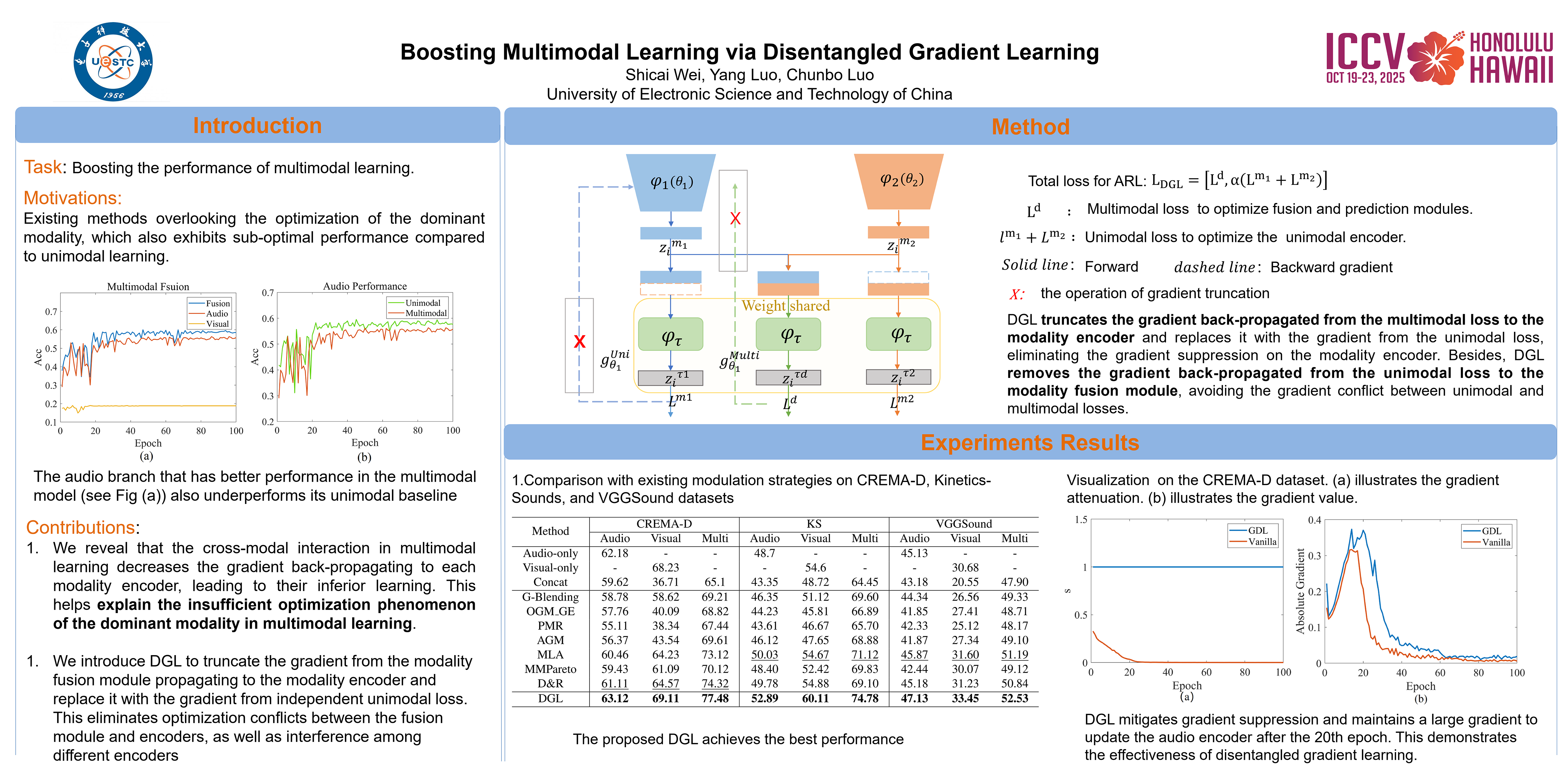
Multimodal learning often encounters the under-optimized problem and may have worse performance than unimodal learning. Existing methods attribute this problem to the imbalanced learning between modalities and rebalance them through gradient modulation. However, they fail to explain why the dominant modality in multimodal models also underperforms that in unimodal learning. In this work, we reveal the optimization conflict between the modality encoder and modality fusion module in multimodal models. Specifically, we prove that the cross-modal fusion in multimodal models decreases the gradient passed back to each modality encoder compared with unimodal models. Consequently, the performance of each modality in the multimodal model is inferior to that in the unimodal model. To this end, we propose a disentangled gradient learning (DGL) framework to decouple the optimization of the modality encoder and modality fusion module in the multimodal model. DGL truncates the gradient back-propagated from the multimodal loss to the modality encoder and replaces it with the gradient from unimodal loss. Besides, DGL removes the gradient back-propagated from the unimodal loss to the modality fusion module. This helps eliminate the gradient interference between the modality encoder and modality fusion module while ensuring their respective optimization processes. Finally, extensive experiments on multiple types of modalities, tasks, and frameworks with dense cross-modal interaction demonstrate the effectiveness and versatility of the proposed DGL.