DIH-CLIP: Unleashing the Diversity of Multi-Head Self-Attention for Training-Free Open-Vocabulary Semantic Segmentation
{kind=link}
Abstract
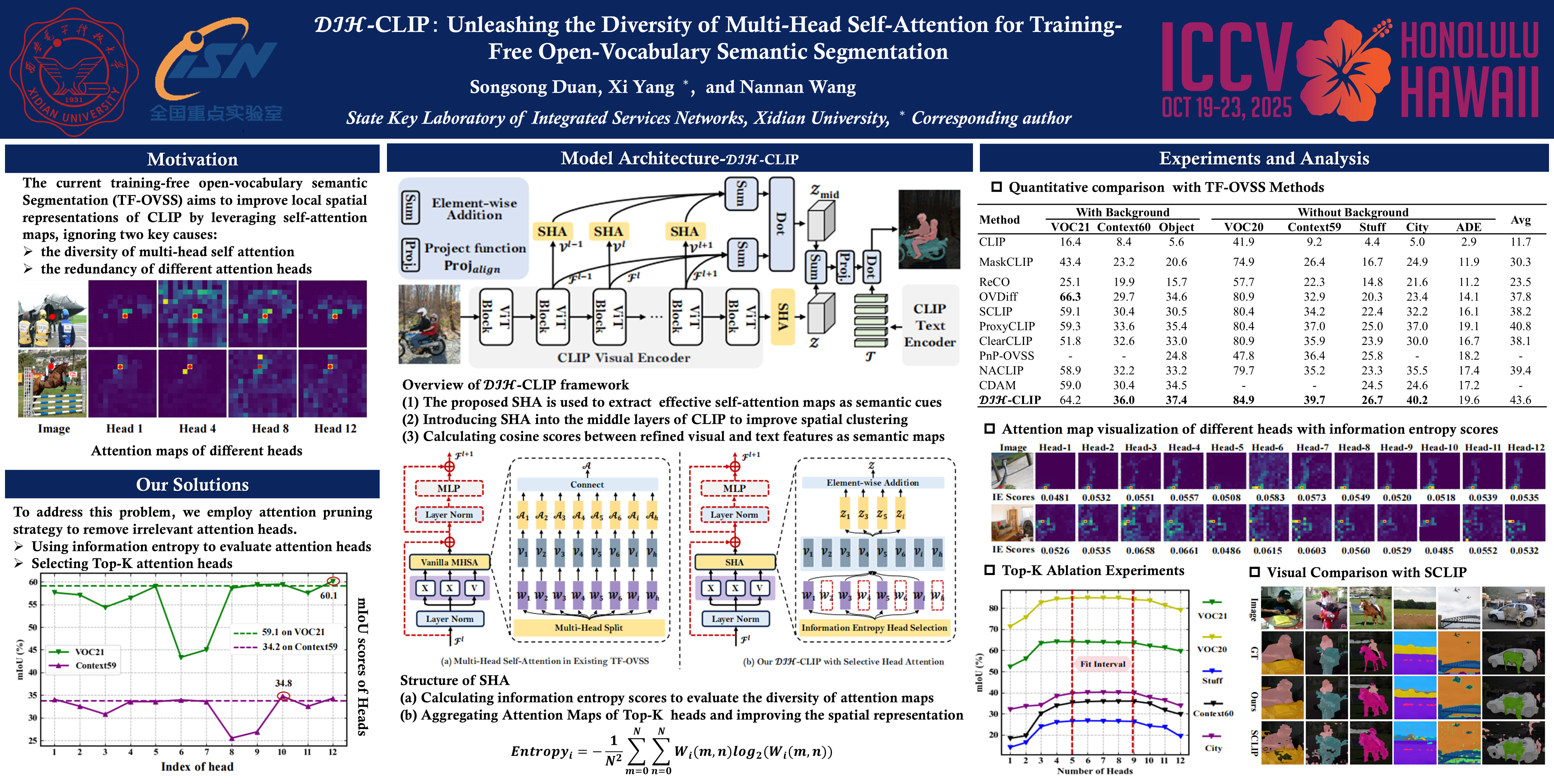
Recent Training-Free Open-Vocabulary Semantic Segmentation (TF-OVSS) leverages a pre-training vision-language model to segment images from open-set visual concepts without training and fine-tuning. The key of TF-OVSS is to improve the local spatial representation of CLIP by leveraging self-correlation maps, thus preserving its zero-sample capability and achieving open understanding. However, most TF-OVSS methods utilize the Multi-Head Self-Attention (MHSA) mechanism to generate self-correlation maps, neglecting the diversity among multiple heads. In this paper, we explore the diversity of MHSA, revealing that the contributions of single-head attention to the final results are varied and redundant. To address this issue, we introduce DIH-CLIP, a training-free CLIP model for open-vocabulary semantic segmentation. Specifically, we propose a Selective Head Attention (SHA) to replace the traditional MHSA in CLIP, which contains two key designs: (1) evaluating the diversity of multi-head attention via calculating information entropy scores of per head attention map and removing the redundant attention head with threshold; (2) transferring the local representation of single-head attention to the global CLIP feature to enhance the local spatial representation capability of CLIP. Furthermore, we embed SHA into the middle layers of CLIP to extract the plentiful details. Experiments on six benchmark datasets demonstrate the effectiveness of DIH-CLIP.