Entropy-Adaptive Diffusion Policy Optimization with Dynamic Step Alignment
{kind=link}
Abstract
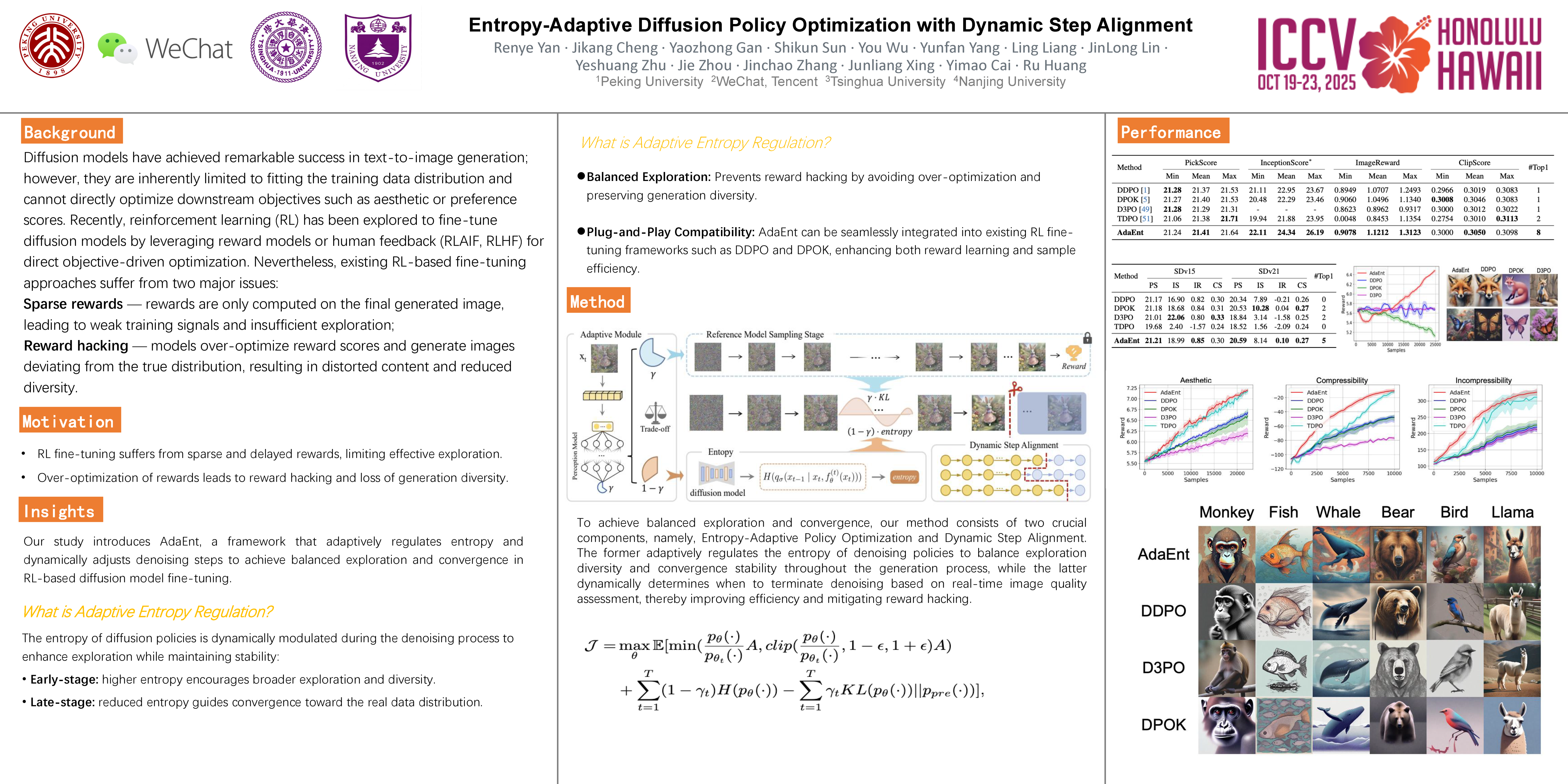
While fine-tuning diffusion models with reinforcement learning (RL) has demonstrated effectiveness in directly optimizing downstream objectives, existing RL frameworks are prone to overfitting the rewards, leading to outputs that deviate from the true data distribution and exhibit reduced diversity. To address this issue, we introduce entropy as a quantitative measure to enhance the exploratory capacity of diffusion models' denoising policies. We propose an adaptive mechanism that dynamically adjusts the application and magnitude of entropy and regularization, guided by real-time quality estimation of intermediate noised states. Theoretically, we prove the convergence of our entropy-enhanced policy optimization and establish two critical properties: 1) global entropy increases through training, ensuring robust exploration capabilities, and 2) entropy systematically decreases during the denoising process, enabling a phase transition from early-stage diversity promotion to late-stage distributional fidelity. Building on this foundation, we propose a plug-and-play RL module that adaptively controls entropy and optimizes denoising steps. Extensive evaluations demonstrate our method's theoretical soundness and empirical robustness, achieving state-of-the-art quality-diversity trade-offs across benchmarks. Notably, our framework significantly improves the rewards and reduces denoising steps in training by up to 40\%. The code is available in the supplementary.