NavQ: Learning a Q-Model for Foresighted Vision-and-Language Navigation
{kind=link}
Abstract
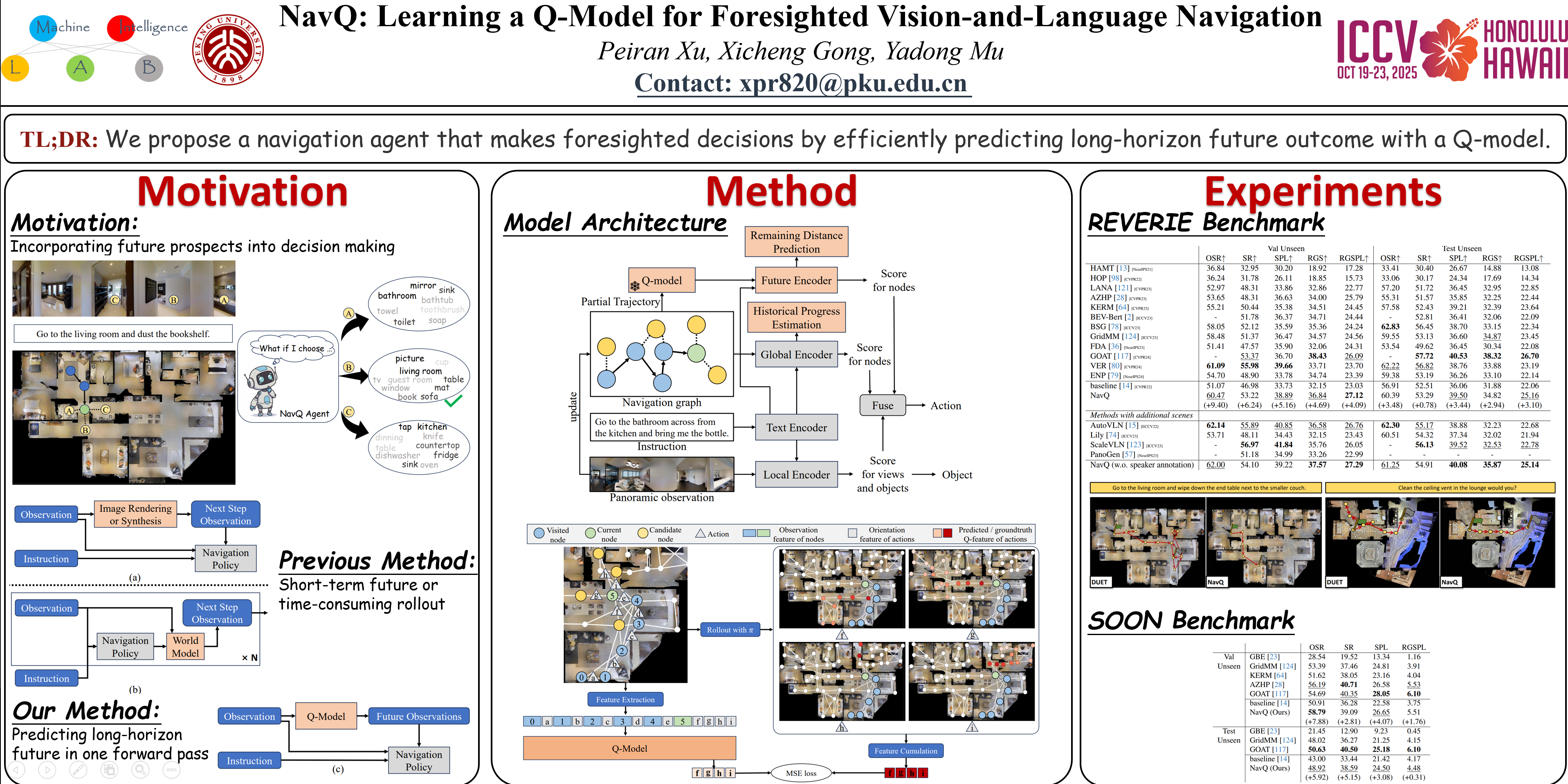
In this work we concentrate on the task of goal-oriented Vision-and-Language Navigation (VLN). Existing methods often make decisions based on historical information, overlooking the future implications and long-term outcomes of the actions. In contrast, we aim to develop a foresighted agent. Specifically, we draw upon Q-learning to train a Q-model using large-scale unlabeled trajectory data, in order to learn the general knowledge regarding the layout and object relations within indoor scenes. This model can generate a Q-feature, analogous to the Q-value in traditional Q-network, for each candidate action, which describes the potential future information that may be observed after taking the specific action. Subsequently, a cross-modal future encoder integrates the task-agnostic Q-feature with navigation instructions to produce a set of action scores reflecting future prospects. These scores, when combined with the original scores based on history, facilitate an A*-style searching strategy to effectively explore the regions that are more likely to lead to the destination. Extensive experiments conducted on widely used goal-oriented VLN datasets validate the effectiveness of the proposed method.