Scaling Omni-modal Pretraining with Multimodal Context: Advancing Universal Representation Learning Across Modalities
{kind=link}
Abstract
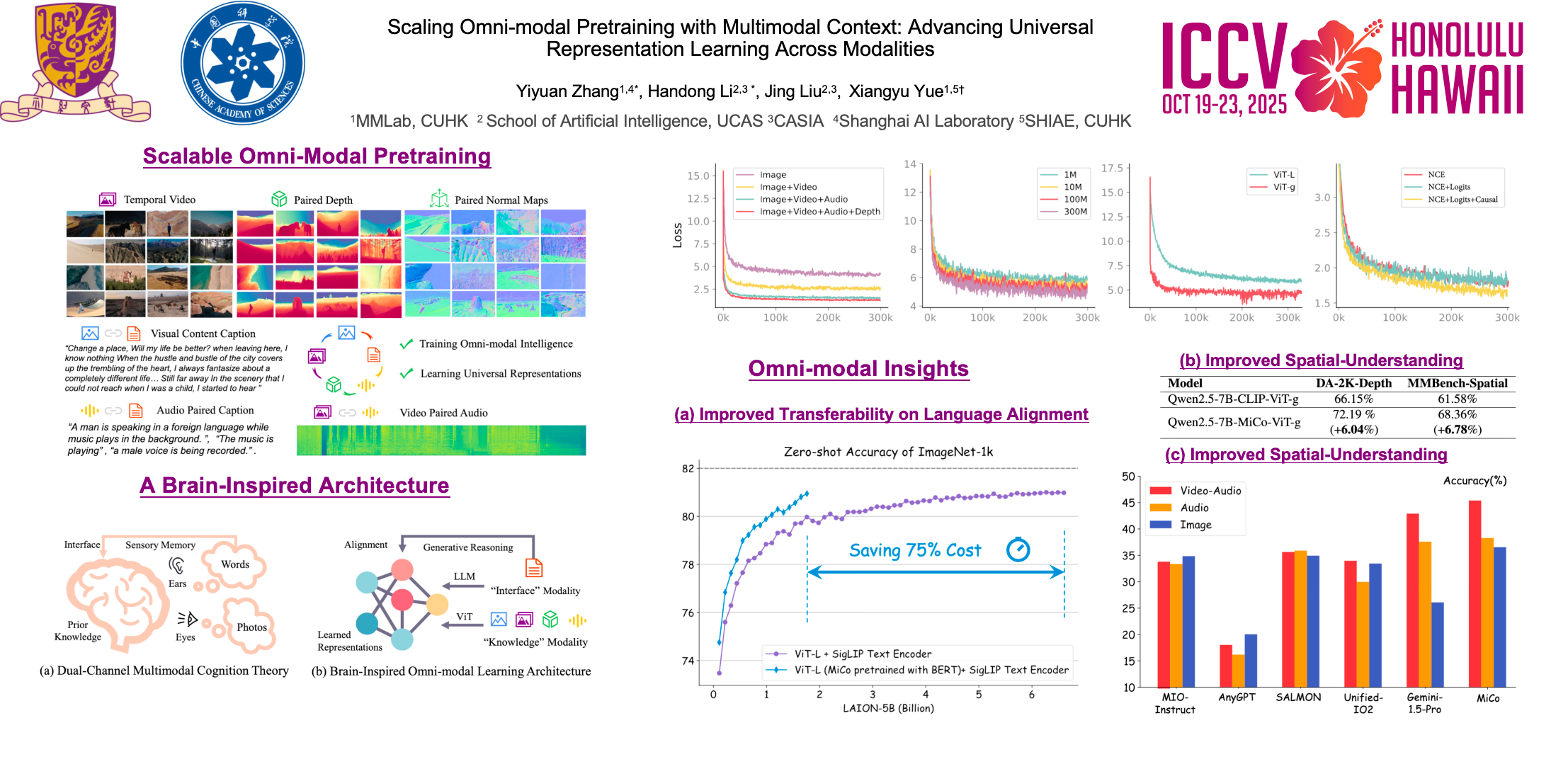
This work introduces Multimodal Context (MiCo), a scalable pretraining framework designed to advance omni-modal intelligence—an AI system capable of understanding and learning from multiple modalities to achieve universal representation learning. MiCo allows for efficient scaling of both the number of modalities and the volume of data, along with model parameters, during the pretraining phase. We evaluate the pretrained models across a diverse set of tasks, including: (i) single-modality perception benchmarks covering 10 distinct modalities, (ii) 25 cross-modal tasks spanning retrieval, question-answering, and captioning, and (iii) 18 large-scale multimodal language model benchmarks. MiCo consistently delivers state-of-the-art results, setting 37 new benchmarks across these tasks. The pretrained models, along with the collected datasets and codebase, will be made publicly available to support the development of omni-modal intelligence and broader research in multimodal learning.