OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
{kind=link}
Abstract
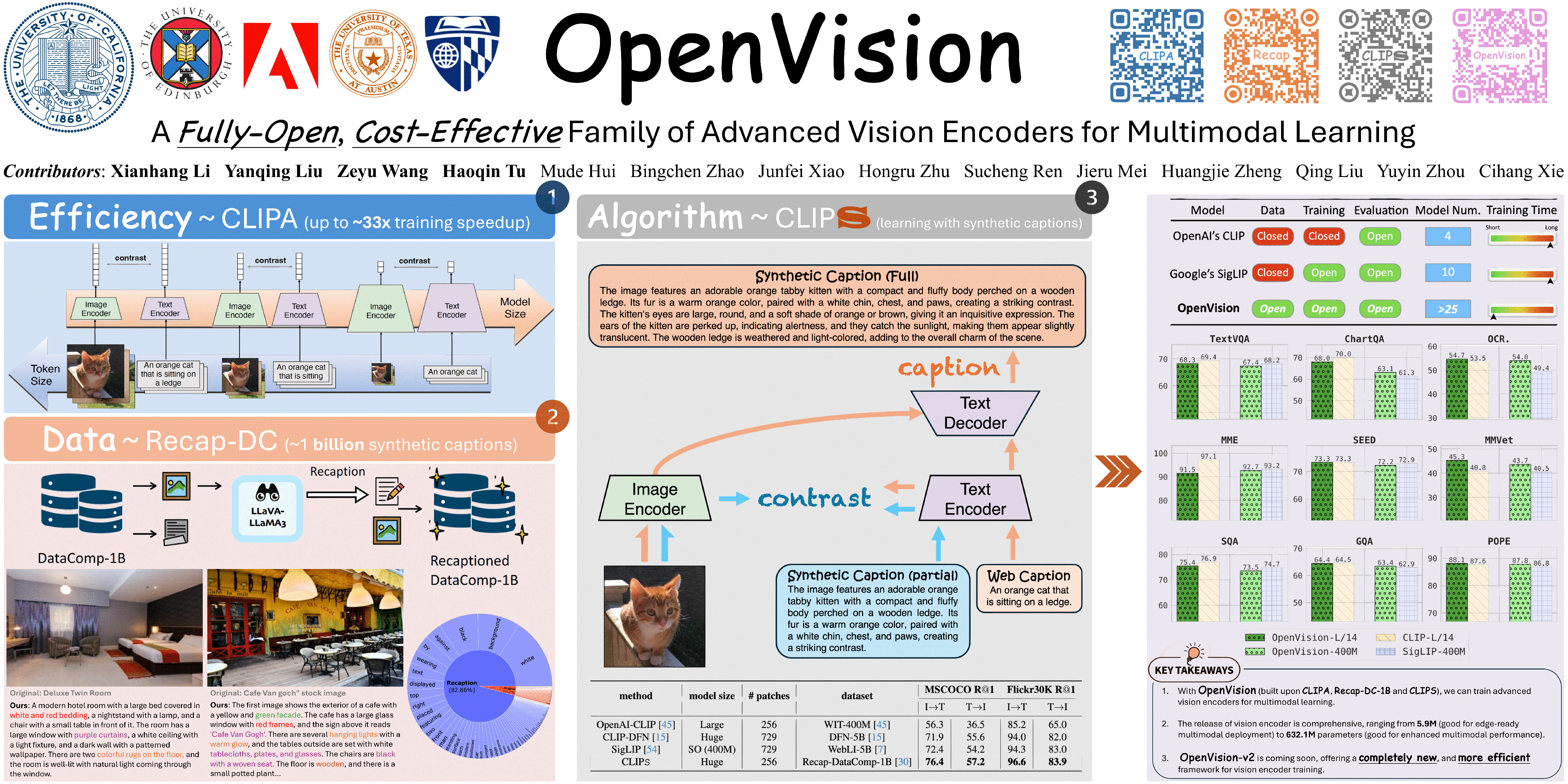
OpenAI's CLIP models, released in early 2021, have long been the only viable choice for the research community in building multimodal foundation models. This dominance has only recently been challenged by a few alternatives like SigLIP. However, to the best of our knowledge, all these solutions are still not fully open, \eg, their training data remains proprietary and/or their training frameworks are unreleased. In this paper, we address this challenge by introducing a family of fully open vision encoders that are as competitive as, or even surpass, OpenAI's CLIP in building multimodal foundation models like LLaVA. Moreover, due to their fully open nature, we offer these vision encoders in a wide range of sizes, from as few as 5.9 million parameters to 632.1 million parameters. We further demonstrate that these variable-sized vision encoders provide significant flexibility: larger models deliver enhanced multimodal performance, while smaller models enable efficient and portable multimodal foundation models suitable for edge device deployment. The training data, code and trained models will be released soon.