From Enhancement to Understanding: Build a Generalized Bridge for Low-light Vision via Semantically Consistent Unsupervised Fine-tuning
{kind=link}
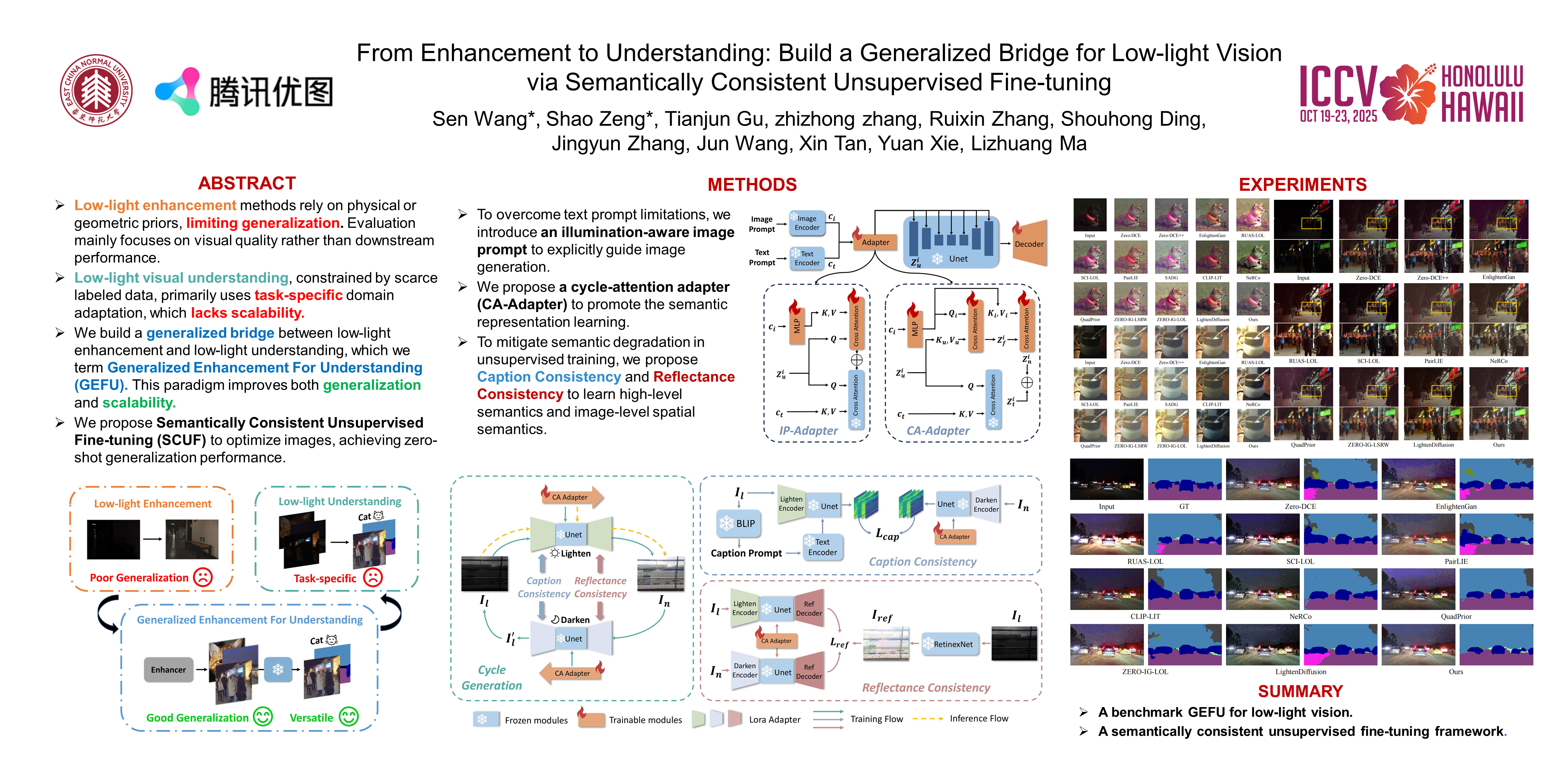
Abstract
Low-level enhancement and high-level visual understanding in low-light vision have traditionally been treated separately. Low-light enhancement improves image quality for downstream tasks, but existing methods rely on physical or geometric priors, limiting generalization. Evaluation mainly focuses on visual quality rather than downstream performance. Low-light visual understanding, constrained by scarce labeled data, primarily uses task-specific domain adaptation, which lacks scalability. To address these challenges, we build a generalized bridge between low-light enhancement and low-light understanding, which we term Generalized Enhancement For Understanding (GEFU). This paradigm improves both generalization and scalability. To address the diverse causes of low-light degradation, we leverage pretrained generative diffusion models to optimize images, achieving zero-shot generalization performance. Building on this, we propose Semantically Consistent Unsupervised Fine-tuning (SCUF). Specifically, to overcome text prompt limitations, we introduce an illumination-aware image prompt to explicitly guide image generation and propose a cycle-attention adapter to maximize its semantic potential. To mitigate semantic degradation in unsupervised training, we propose caption and reflectance consistency to learn high-level semantics and image-level spatial semantics. Extensive experiments demonstrate that our proposed method outperforms current state-of-the-art methods in traditional image quality and GEFU tasks including classification, detection, and semantic segmentation.