Harnessing Text-to-Image Diffusion Models for Point Cloud Self-Supervised Learning
{kind=link}
Abstract
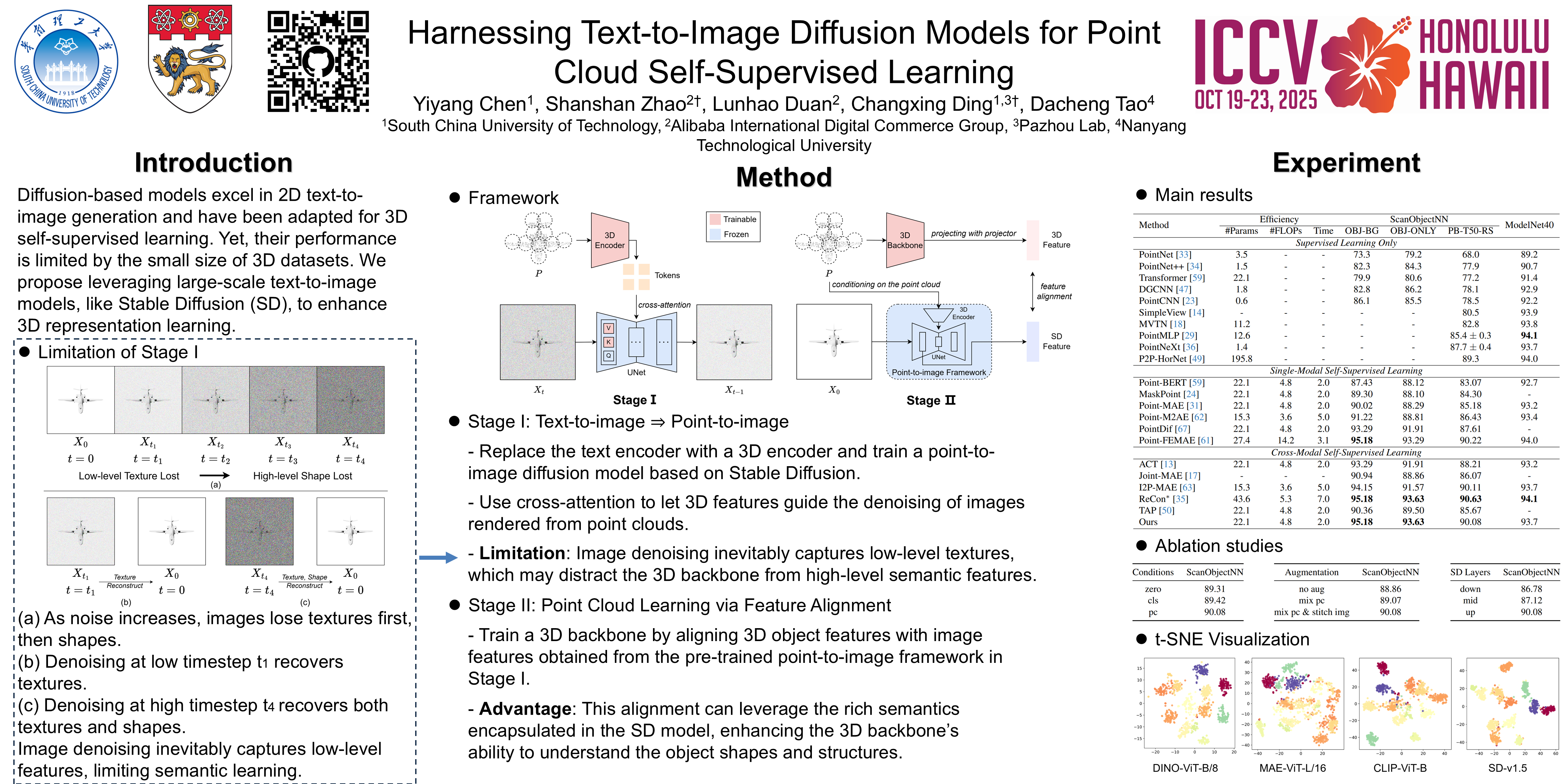
Diffusion-based models, widely used in text-to-image generation, have proven effective in 2D representation learning. Recently, this framework has been extended to 3D self-supervised learning by constructing a conditional point generator for enhancing 3D representations. However, its performance remains constrained by the 3D diffusion model, which is trained on the available 3D datasets with limited size. We hypothesize that the robust capabilities of text-to-image diffusion models, particularly Stable Diffusion (SD), which is trained on large-scale datasets, can help overcome these limitations. To investigate this hypothesis, we propose PointSD, a framework that leverages the SD model for 3D self-supervised learning. By replacing the SD model's text encoder with a 3D encoder, we train a point-to-image diffusion model that allows point clouds to guide the denoising of rendered noisy images. With the trained point-to-image diffusion model, we use noise-free images as the input and point clouds as the condition to extract SD features. Next, we train a 3D backbone by aligning its features with these SD features, thereby facilitating direct semantic learning. Comprehensive experiments on downstream point cloud tasks and ablation studies demonstrate that the SD model can enhance point cloud self-supervised learning. Our code will be publicly available.