DiTFastAttnV2: Head-wise Attention Compression for Multi-Modality Diffusion Transformers
{kind=link}
Abstract
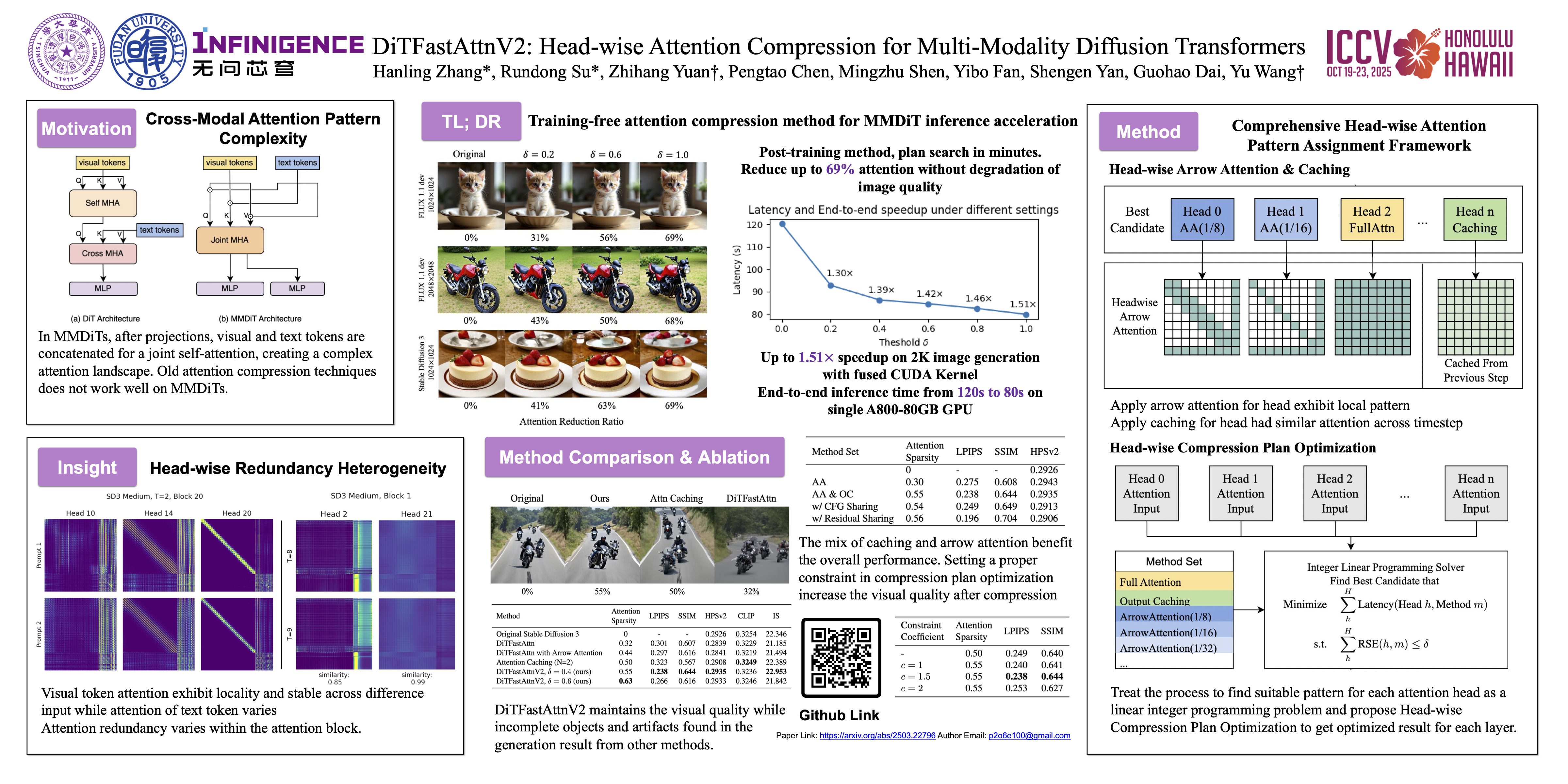
Text-to-image generation models, especially Multimodal Diffusion Transformers (MMDiT), have shown remarkable progress in generating high-quality images. However, these models often face significant computational bottlenecks, particularly in attention mechanisms, which hinder their scalability and efficiency. In this paper, we introduce DiTFastAttnV2, a post-training compression method designed to accelerate attention in MMDiT. Through an in-depth analysis of MMDiT’s attention patterns, we identify key differences from prior DiT-based methods and propose head-wise arrow attention and caching mechanisms to dynamically adjust attention heads, effectively bridging this gap. We also design an Efficient Fused Kernel for further acceleration. By leveraging local metric methods and optimization techniques, our approach significantly reduces the search time for optimal compression schemes to just minutes while maintaining generation quality. Furthermore, with the customized kernel, DiTFastAttnV2 achieves a 68\% reduction in attention FLOPs on 2K image generation without compromising visual fidelity.