EA-Vit: Efficient Adaptation for Elastic Vision Transformer
{kind=link}
Abstract
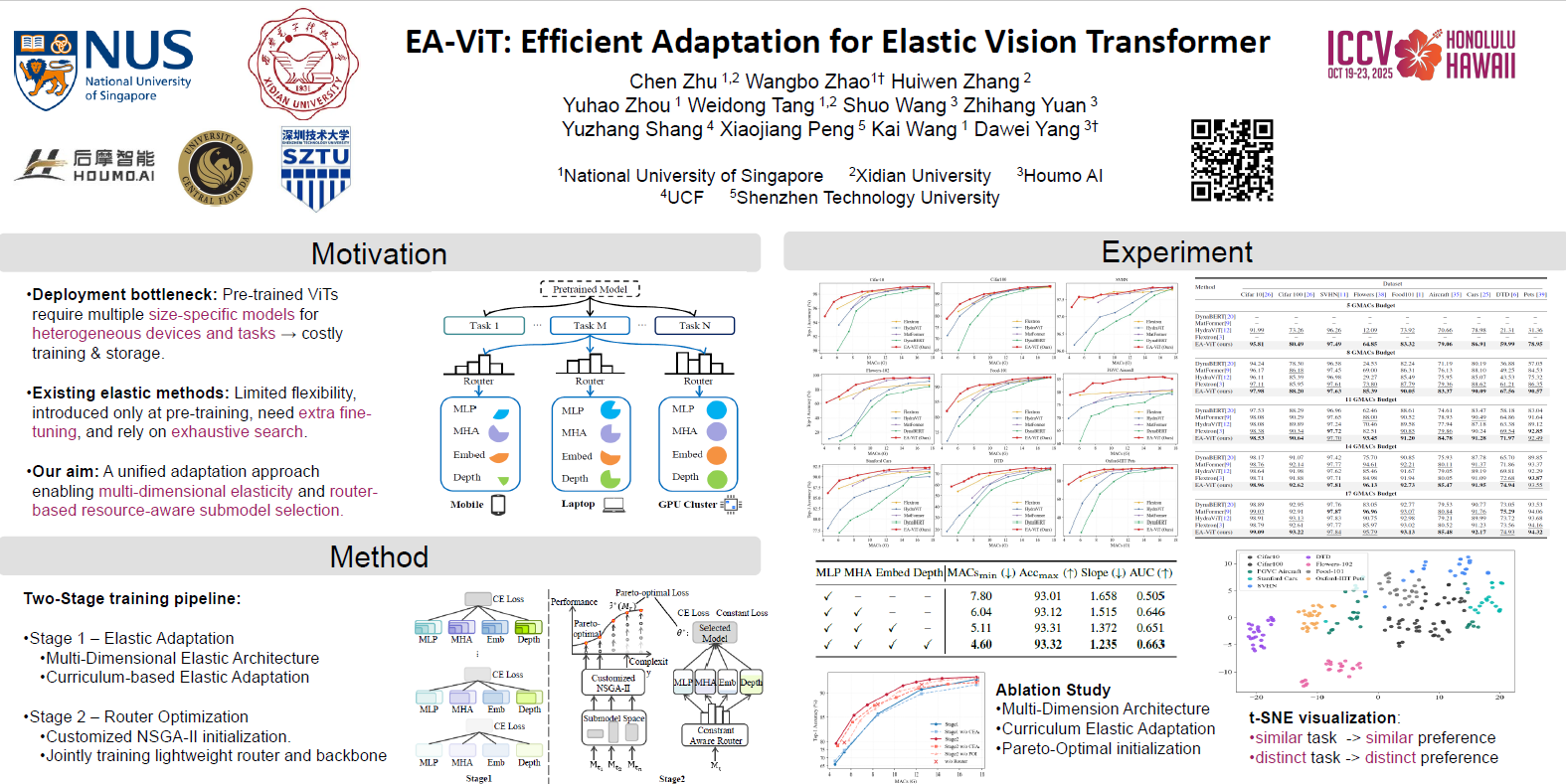
Vision Transformer (ViT) has emerged as a foundational model in computer vision, excelling in generalization and adaptation to downstream tasks. However, supporting diverse resource constraints typically requires retraining multiple, size-specific ViTs, which is both time-consuming and expensive. In this paper, we propose \emph{Efficient Elastic ViT Adaptation}, a single ViT framework that encapsulates multiple submodels of varying sizes, eliminating the need for repeated adaptation.We introduce elastic configurations along four key dimensions—embedding dimension, attention heads, MLP expansion ratio, and layer depth—and a lightweight router that selects the optimal submodel under different computational budgets. Training proceeds in two stages: \emph{Staged Elastic Adaptation} progressively introduces complexity for efficient joint training of submodels while preserving as much pre-trained knowledge as possible; Subsequently, we integrate the router to refine the model by balancing accuracy and MACs, guiding it to initially focus on a small set of promising submodels for faster convergence within the large design space.Our approach captures an exponentially large family of submodels in a single adaptation process. Extensive experiments demonstrate that, for any resource constraint, the router identifies the best submodel, delivering high performance and reduced overhead compared to previous methods.