Learning Precise Affordances from Egocentric Videos for Robotic Manipulation
{kind=link}
Abstract
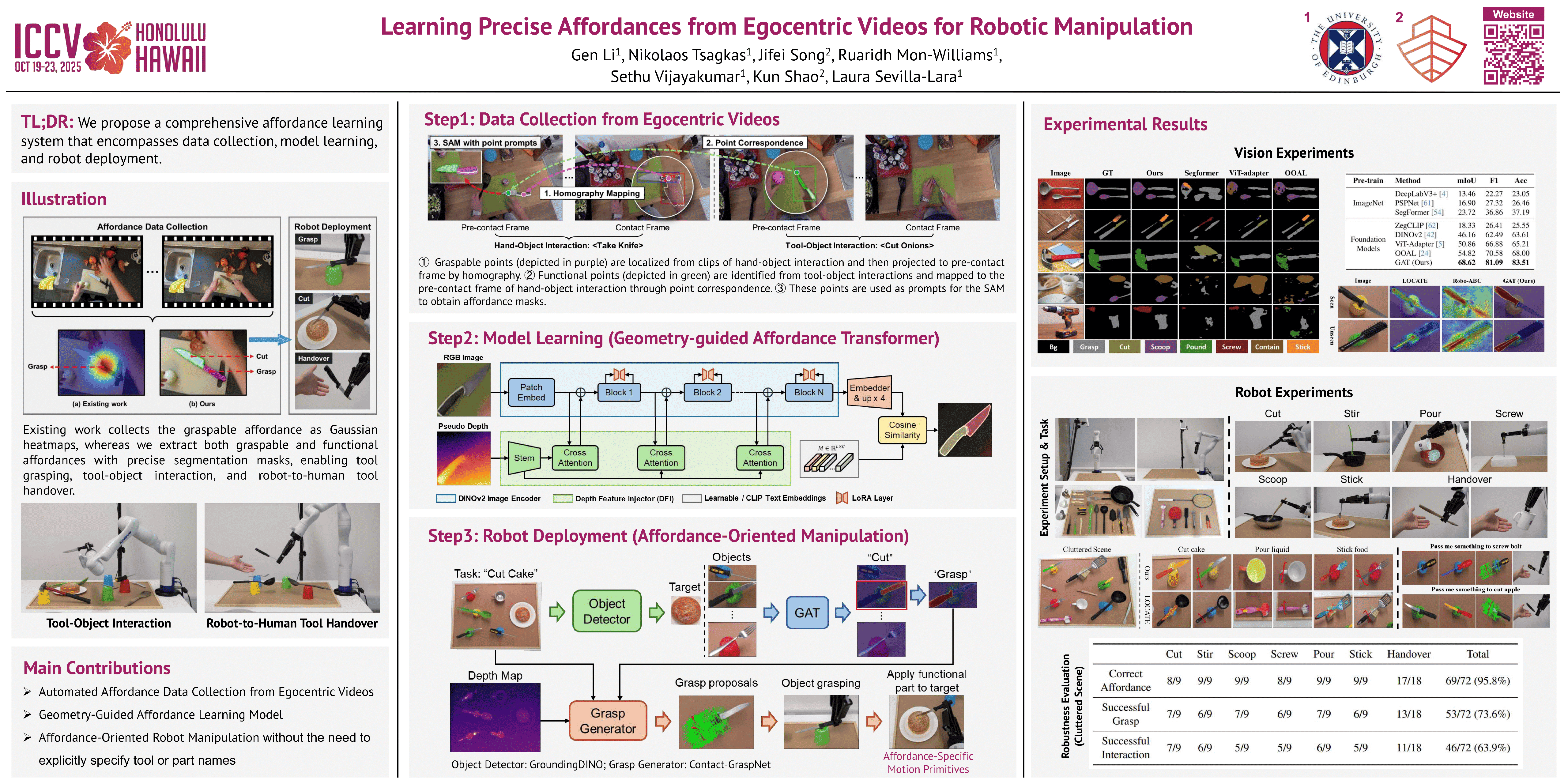
Affordance, defined as the potential actions that an object offers, is crucial for embodied AI agents. For example, such knowledge directs an agent to grasp a knife by the handle for cutting or by the blade for safe handover. While existing approaches have made notable progress, affordance research still faces three key challenges: data scarcity, poor generalization, and real-world deployment. Specifically, there is a lack of large-scale affordance datasets with precise segmentation maps, existing models struggle to generalize across different domains or novel object and affordance classes, and little work demonstrates deployability in real-world scenarios. In this work, we address these issues by proposing a complete affordance learning system that (1) takes in egocentric videos and outputs precise affordance annotations without human labeling, (2) leverages geometric information and vision foundation models to improve generalization, and (3) introduces a framework that facilitates affordance-oriented robotic manipulation such as tool grasping and robot-to-human tool handover. Experimental results show that our model surpasses the state-of-the-art by 13.8% in mIoU, and the framework achieves 77.1% successful grasping among 179 trials, including evaluations on seen, unseen classes, and cluttered scenes.