Describe, Adapt and Combine: Empowering CLIP Encoders for Open-set 3D Object Retrieval
{kind=link}
Abstract
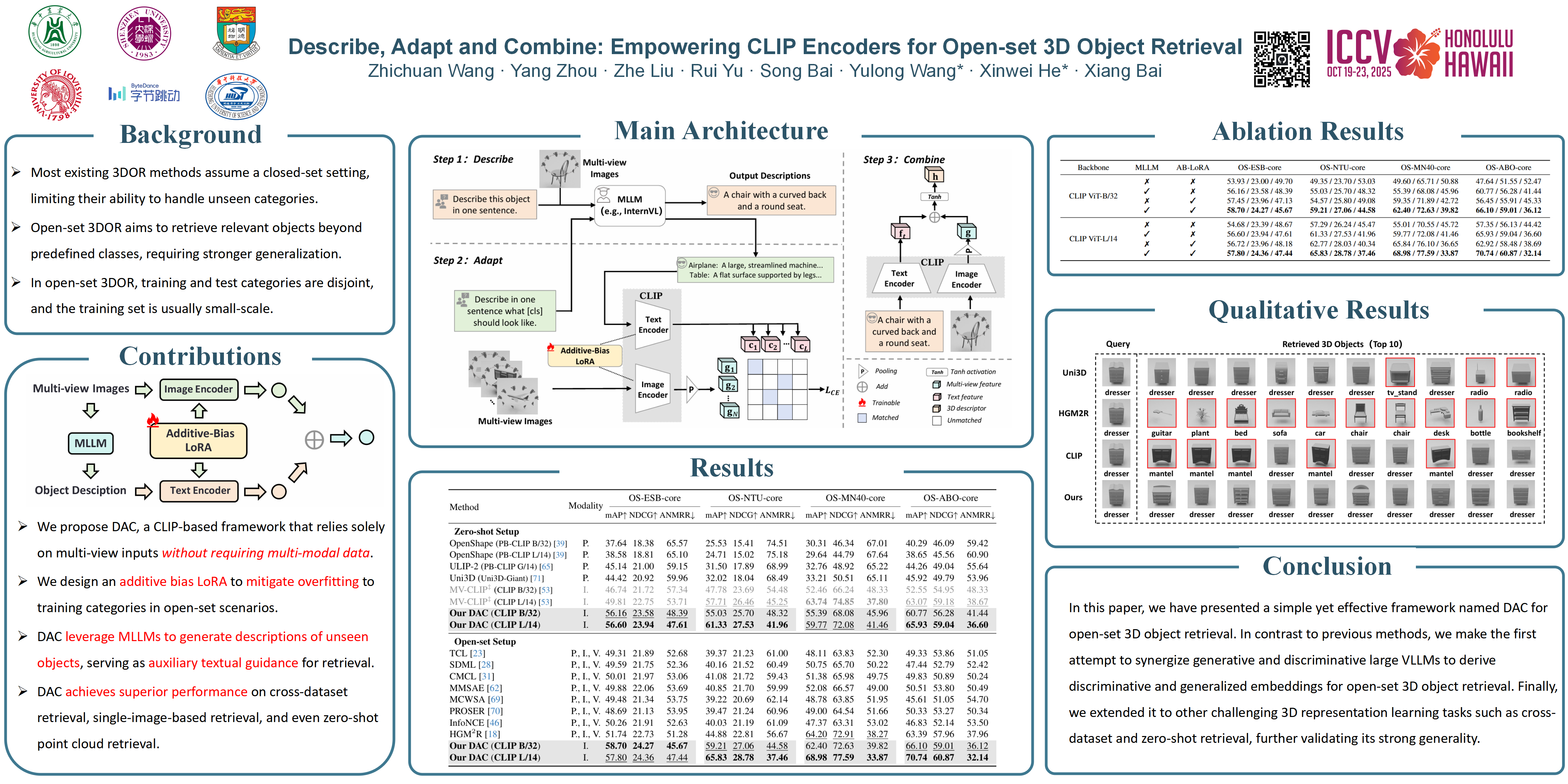
Open-set 3D object retrieval (3DOR) is an emerging task aiming to retrieve 3D objects of unseen categories beyond the training set. Existing methods typically utilize all modalities (i.e., voxels, point clouds, multi-view images) and train specific backbones before fusion. However, they still struggle to produce generalized representations due to insufficient 3D training data. Being contrastively pre-trained on web-scale image-text pairs, CLIP inherently produces generalized representations for a wide range of downstream tasks. Building upon it, we present a simple yet effective framework named Describe, Adapt and Combine (DAC) by taking only multi-view images for open-set 3DOR. DAC innovatively synergizes a CLIP model with a multi-modal large language model (MLLM) to learn generalized 3D representations, where the MLLM is used for dual purposes. First, it describes the seen category information to align with CLIP's training objective for adaptation during training. Second, it provides external hints about unknown objects complementary to visual cues during inference. To improve the synergy, we introduce an Additive-Bias Low-Rank adaptation (AB-LoRA), which alleviates overfitting and further enhances the generalization to unseen categories. With only multi-view images, DAC significantly surpasses prior arts by an average of +10.01\% mAP on four open-set 3DOR datasets. Moreover, its generalization is also validated on image-based and cross-dataset setups.