Aligning Global Semantics and Local Textures in Generative Video Enhancement
{kind=link}
Abstract
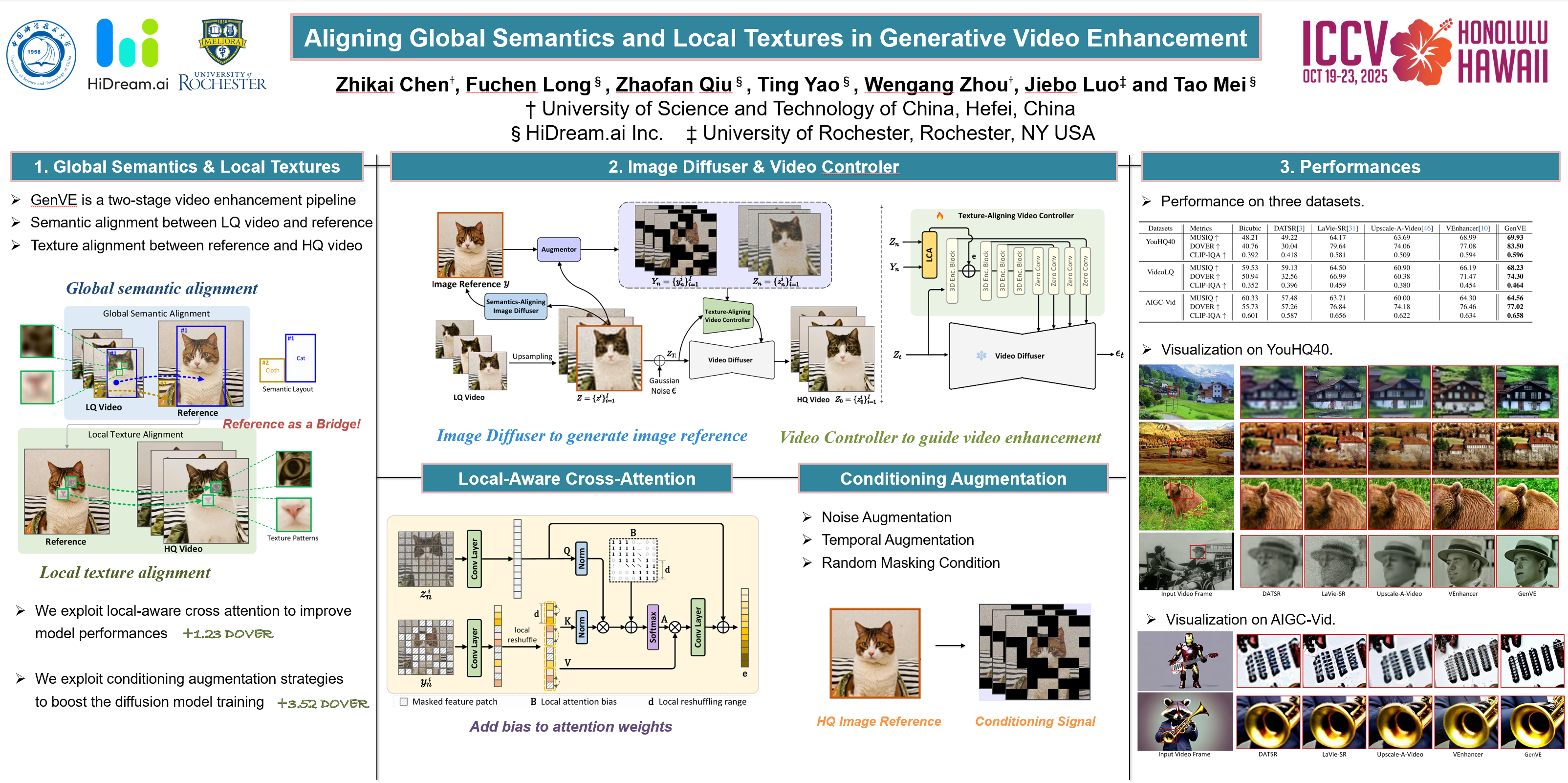
Recent advances in video generation have demonstrated the utility of powerful diffusion models. One important direction among them is to enhance the visual quality of the AI-synthesized videos for artistic creation. Nevertheless, solely relying on the knowledge embedded in the pre-trained video diffusion models might limit the generalization ability of local details (e.g., texture). In this paper, we address this issue by exploring the visual cues from a high-quality (HQ) image reference to facilitate visual details generation in video enhancement. We present GenVE, a new recipe of generative video enhancement framework that pursues the semantic and texture alignment between HQ image reference and denoised video in diffusion. Technically, GenVE first leverages an image diffusion model to magnify a key frame of the input video to attain a semantics-aligned HQ image reference. Then, a video controller is integrated into 3D-UNet to capture patch-level texture of the image reference to enhance fine-grained details generation at the corresponding region of low-quality (LQ) video. Moreover, a series of conditioning augmentation strategies are implemented for effective model training and algorithm robustness. Extensive experiments conducted on the public YouHQ40 and VideoLQ, as well as self-built AIGC-Vid dataset, quantitatively and qualitatively demonstrate the efficacy of our GenVE over the state-of-the-art video enhancement approaches.