KDA: Knowledge Diffusion Alignment with Enhanced Context for Video Temporal Grounding
{kind=link}
Abstract
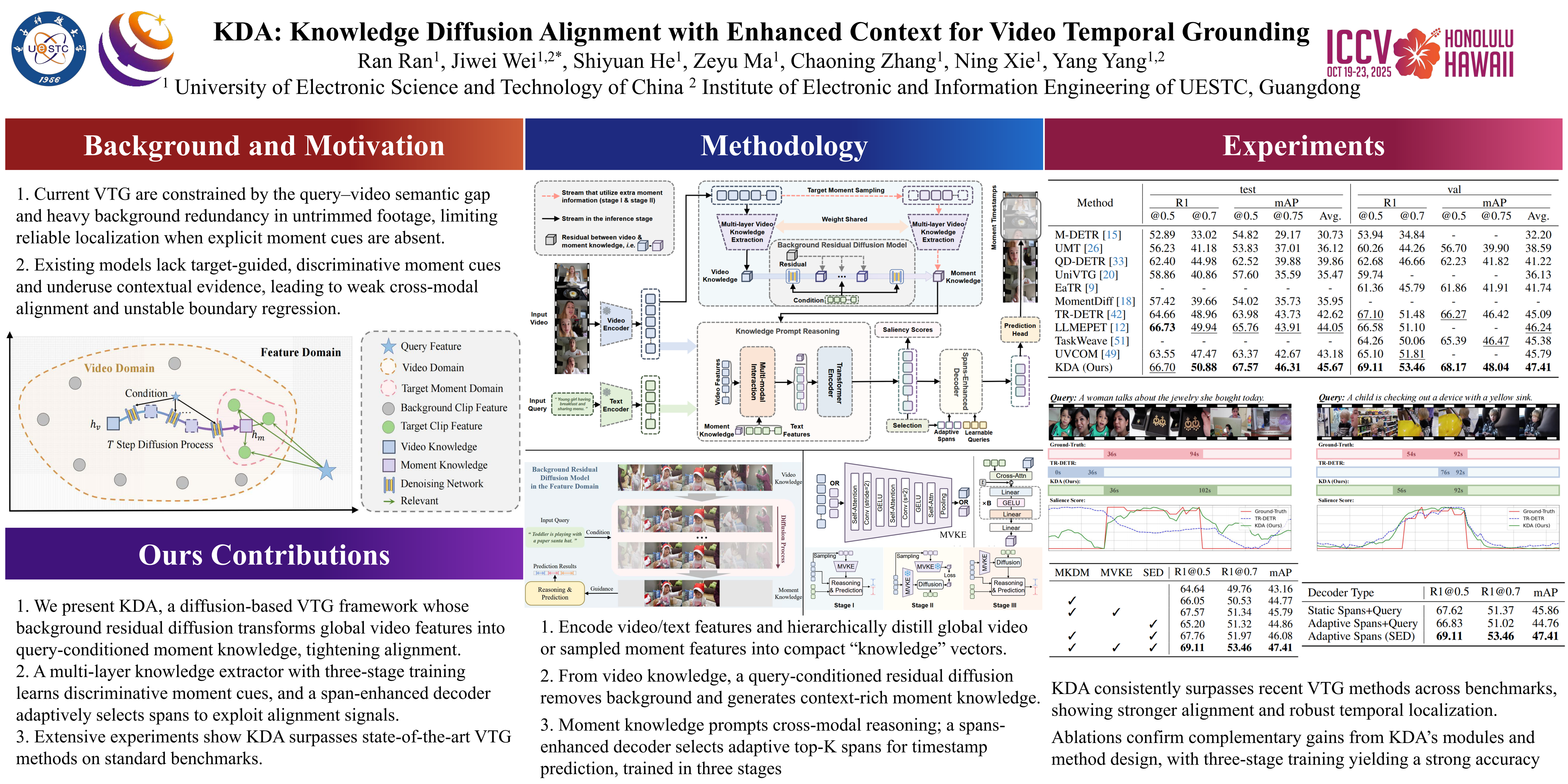
Video Temporal Grounding (VTG) confronts the challenge of bridging the semantic gap between concise textual queries and the rich complexity of video content, compounded by the difficulty of capturing discriminative features without external priors. To address these challenges, we propose Knowledge Diffusion Alignment (KDA), a framework that leverages the generative prowess of diffusion models. KDA introduces a multi-layer video knowledge extraction module alongside a background residual diffusion model that progressively prunes irrelevant background information from global video features, thereby distilling query-relevant moment knowledge enriched with visual context. By a three-stage training approach that harnesses external priors, KDA guarantees that the extracted moment knowledge incorporates the discriminative features necessary for accurate localization. A knowledge prompt reasoning module facilitates the comprehensive interaction and utilization of moment knowledge and multimodal features. Moreover, we introduce a spans-enhanced decoder that selectively integrates spans from multi-modal features, capitalizing on intrinsic alignment cues. Comprehensive experiments on three datasets demonstrate performance that surpasses state-of-the-art methods, attesting to the effectiveness of the proposed framework.