Bitrate-Controlled Diffusion for Disentangling Motion and Content in Video
{kind=link}
Abstract
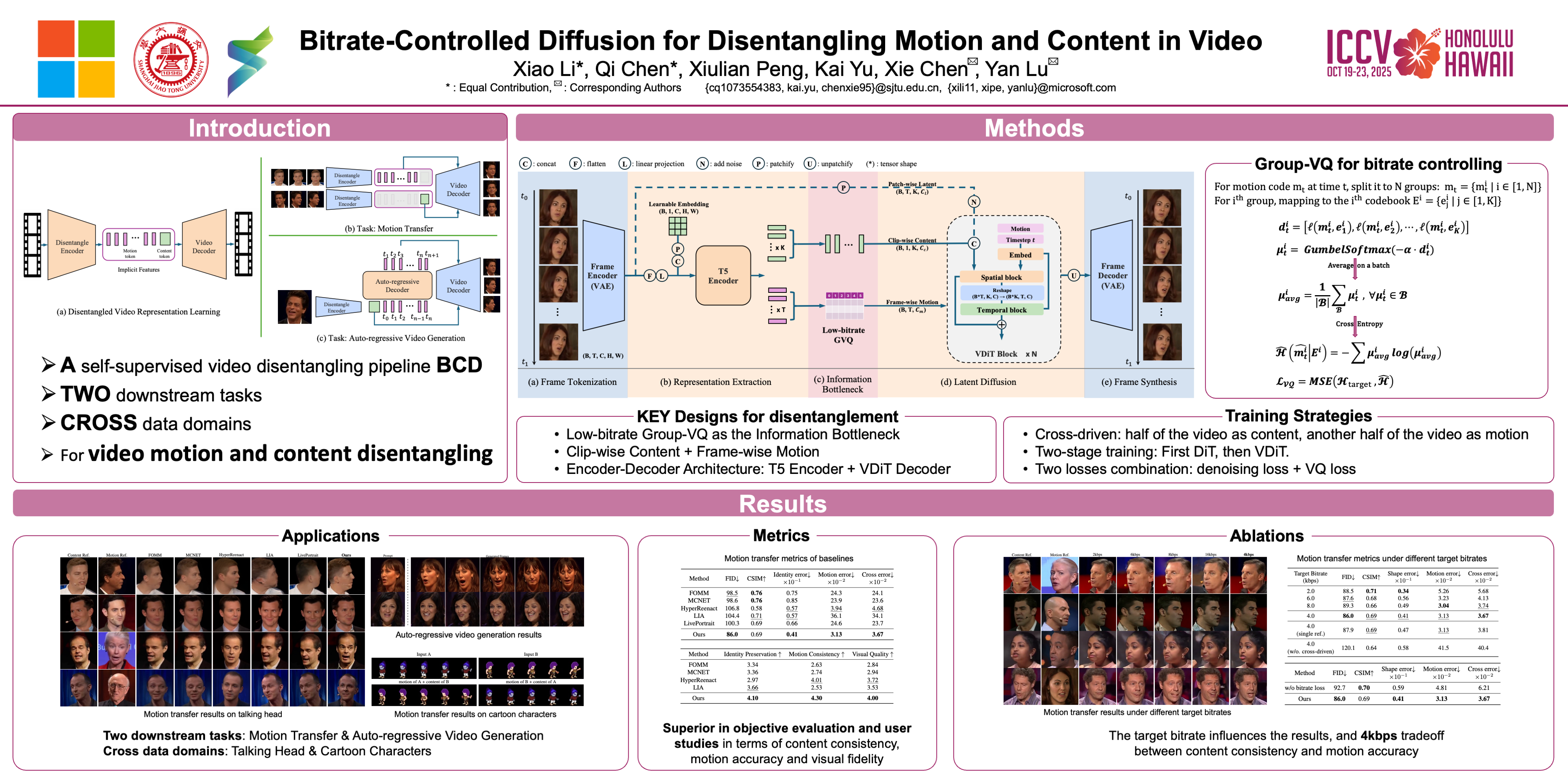
We propose a novel and general framework to disentangle video data into its dynamic motion and static content components. Our proposed method is a self-supervised pipeline with less assumptions and inductive biases than previous works: it utilizes a transformer-based architecture to jointly generate flexible implicit features for frame-wise motion and clip-wise content, and incorporates a low-bitrate vector quantization as an information bottleneck to promote disentanglement and form a meaningful discrete motion space. The bitrate-controlled latent motion and content are used as conditional inputs to a denoising diffusion model to facilitate self-supervised representation learning. We validate our disentangled representation learning framework on real world talking head videos with motion transfer and auto-regressive motion generation tasks. Furthermore, we also show that our method can generalize to other type of video data, such as pixel sprites of 2D cartoon characters. Our work presents a new perspective on self-supervised learning of disentangled video representations, contributing to the broader field of video analysis and generation.