EVDM: Event-based Real-world Video Deblurring with Mamba
{kind=link}
Abstract
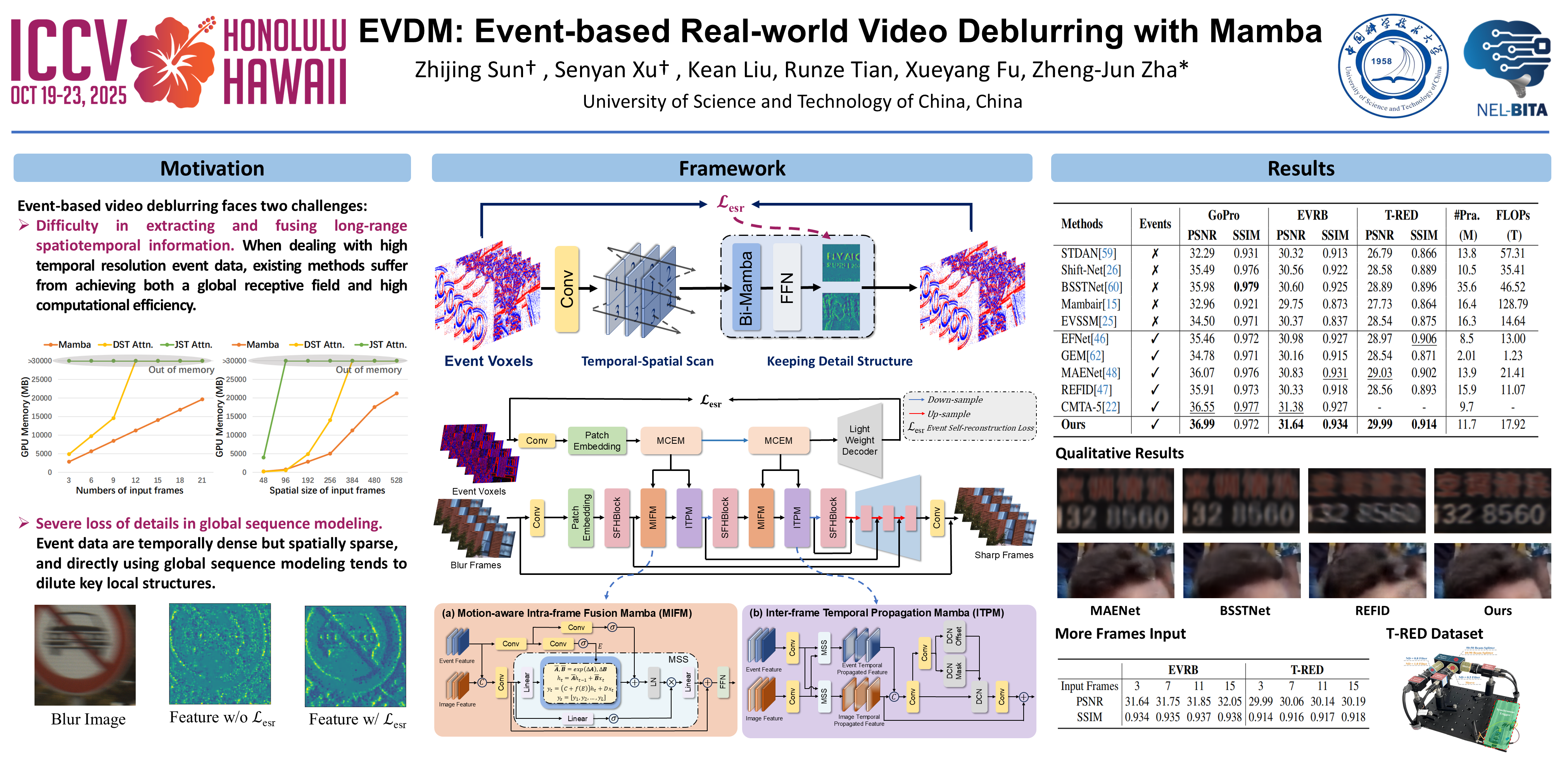
Existing event-based video deblurring methods face limitations in extracting and fusing long-range spatiotemporal motion information from events, primarily due to restricted receptive fields or low computational efficiency, resulting in suboptimal deblurring performance.To address these issues, we introduce the state space model, which leverages linear complexity and global receptive fields for long-range modeling, and propose EVDM, a novel Event-based Video Deblurring framework with Mamba. The framework consists of: (1) Motion Clue Extraction Mamba (MCEM), which employs an event self-reconstruction loss to ensure the completeness of details when extracting long-range motion information. (2) Motion-aware Intra-frame Fusion Mamba (MIFM) and Inter-frame Temporal Propagation Mamba (ITPM), which utilize the motion-aware state space to perform cross-modal fusion and inter-frame information exchange guided by motion clues. Consequently, EVDM achieves superior detail restoration in blurred regions while ensuring temporal motion consistency across frames.Additionally, to overcome the limitation of fixed exposure ratios in existing event-frame paired datasets, we introduce T-RED, a high-quality, high-resolution dataset with varying exposure time ratios. T-RED provides more realistic and complex data for event-based video deblurring research.Experiments on multiple datasets demonstrate that EVDM outperforms previous SOTA methods.