Learning Efficient and Generalizable Human Representation with Human Gaussian Model
{kind=link}
Abstract
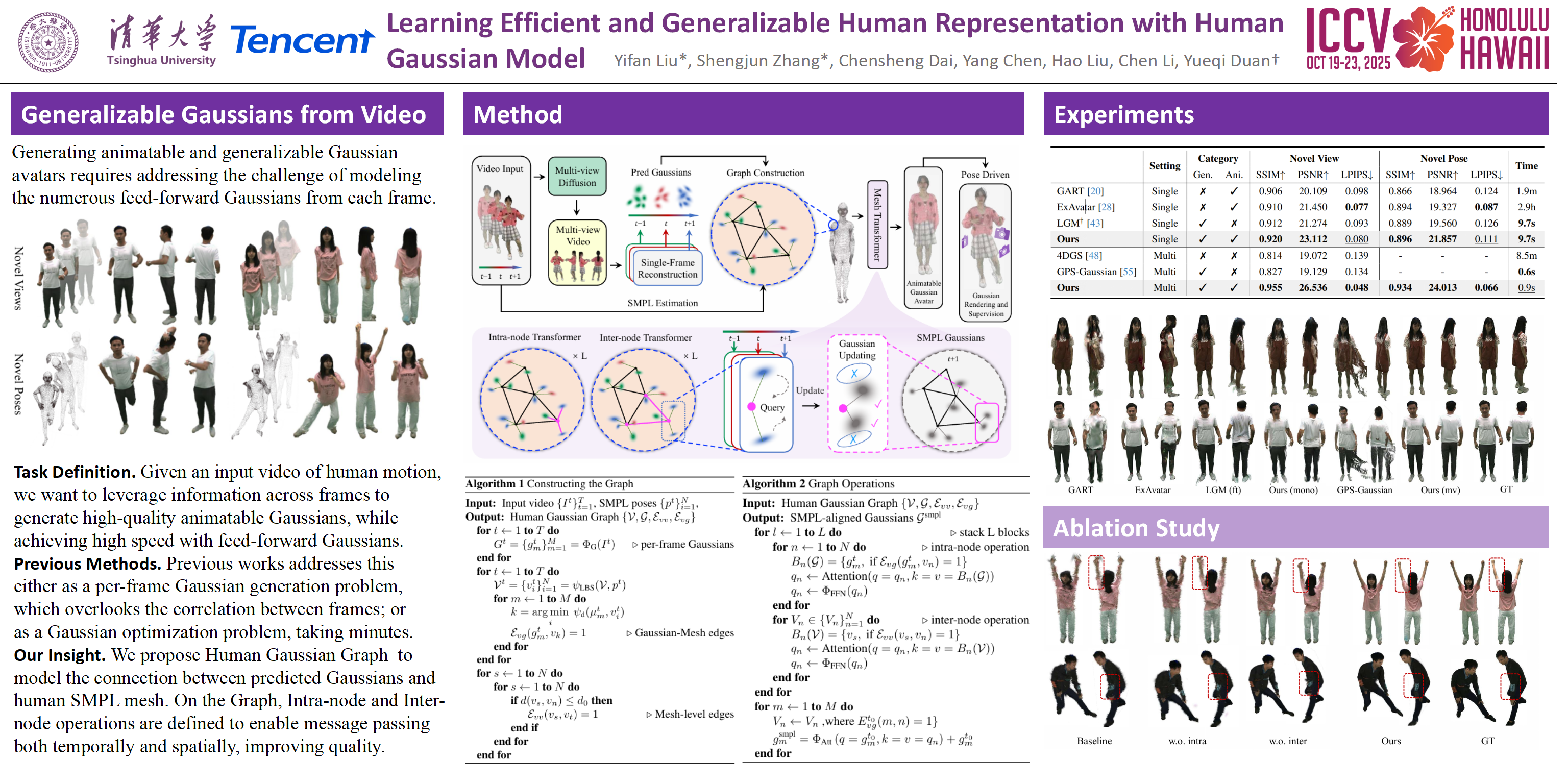
Modeling animatable human avatars from videos is a long-standing and challenging problem. While conventional methods require per-instance optimization, recent feed-forward methods have been proposed to generate 3D Gaussians with a learnable network.However, these methods predict independent Gaussians for each frame prediction without fully capturing the relations of Gaussians from different frames, which are hard to be animated by novel poses. To address this, we propose Human Gaussian Graph (HGG) to generate generalizable and animatable Gaussian representations. Specifically, we construct a dual-layer graph to model the relations between predicted Gaussians from multiple frames and SMPL mesh. We design an intra-node operation to aggregate various Gaussian information at different timesteps to benefit from video inputs. Furthermore, we propose an inter-node operation to support message passing between SMPL vertices. In this manner, we leverage the human structure prior to recover generalizable and animatable Gaussian representations.Experimental results on novel view synthesis and novel pose animation demonstrate the efficiency and generalization of our method.