Capturing head avatar with hand contacts from a monocular video
{kind=link}
Abstract
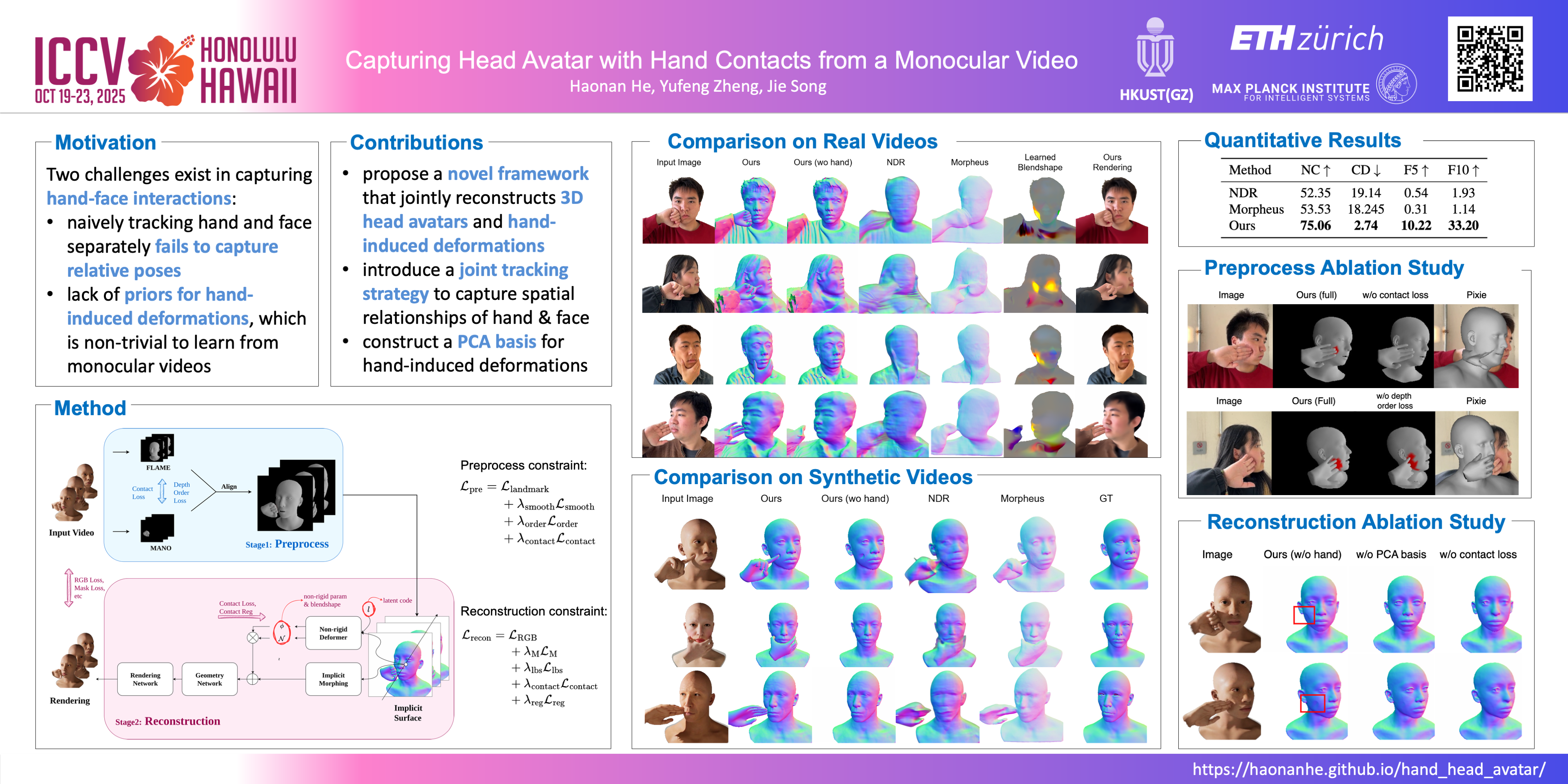
Photorealistic 3D head avatars are vital for telepresence, gaming, and VR. However, most methods focus solely on facial regions, ignoring natural hand-face interactions, such as a hand resting on the chin or fingers gently touching the cheek, which convey cognitive states like pondering. In this work, we present a novel framework that jointly learns detailed head avatars and the non-rigid deformations induced by hand-face interactions.There are two principal challenges in this task. First, naively tracking hand and face separately fails to capture their relative poses. To overcome this, we propose to combine depth order loss with contact regularization during pose tracking, ensuring correct spatial relationships between the face and hand. Second, no publicly available priors exist for hand-induced deformations, making them non-trivial to learn from monocular videos. To address this, we learn a PCA basis specific to hand-induced facial deformations from a face-hand interaction dataset. This reduces the problem to estimating a compact set of PCA parameters rather than a full spatial deformation field. Furthermore, inspired by physics-based simulation, we incorporate a contact loss that provides additional supervision, significantly reducing interpenetration artifacts and enhancing the physical plausibility of the results.We evaluate our approach on RGB(D) videos captured by an iPhone. Additionally, to better evaluate the reconstructed geometry, we construct a synthetic dataset of avatars with various types of hand interactions. We show that our method can capture better appearance and more accurate deforming geometry of the face than SOTA surface reconstruction methods.