Learnable Fractional Reaction-Diffusion Dynamics for Under-Display ToF Imaging and Beyond
Xin Qiao ⋅ Matteo Poggi ⋅ Xing Wei ⋅ Pengchao Deng ⋅ Yanhui Zhou ⋅ Stefano Mattoccia
2025 Poster
{kind=link}
Abstract
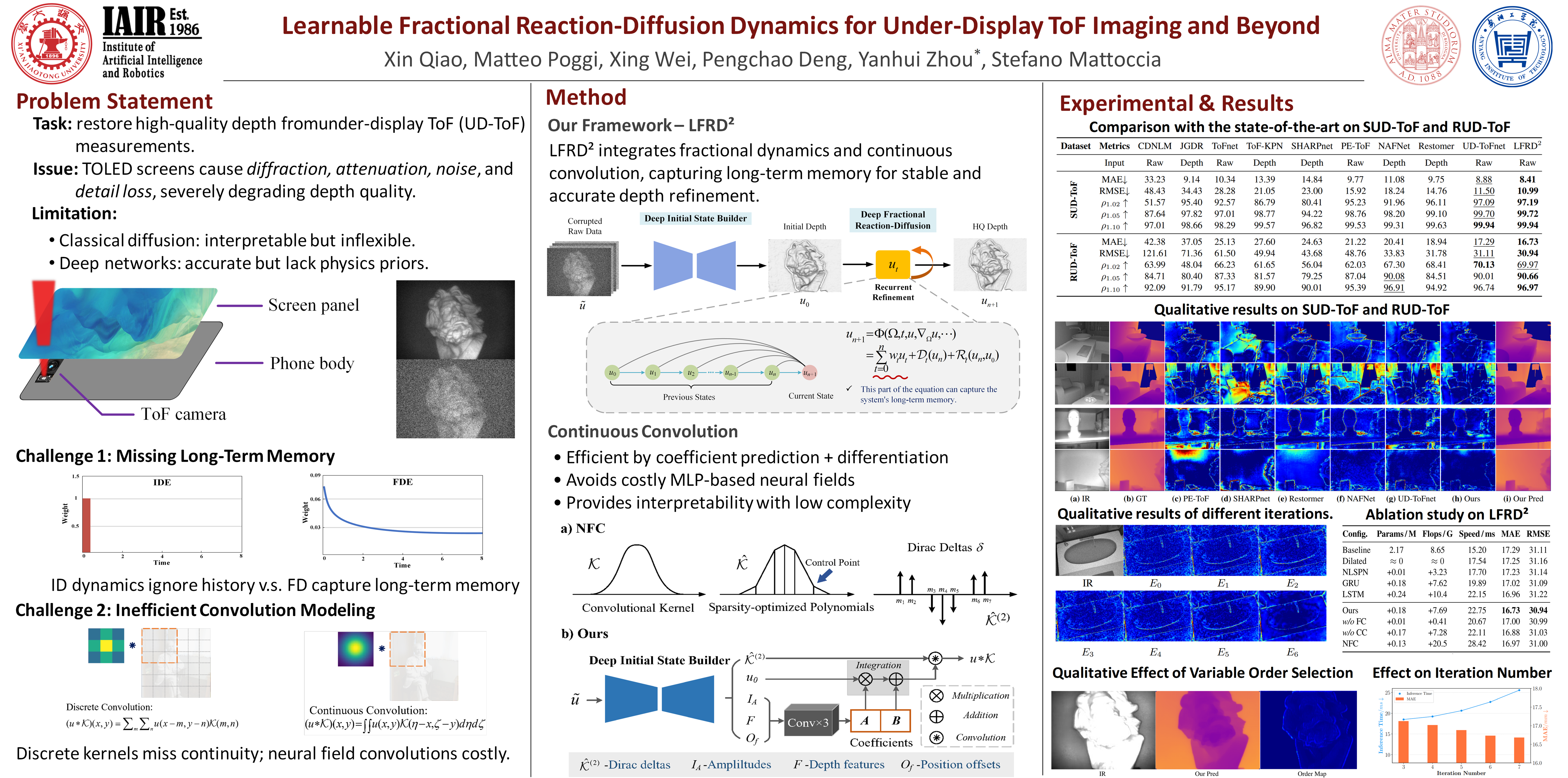
Under-display ToF imaging aims to both achieve precise depth sensing and maximize user experience by embedding a ToF camera beneath a screen panel. However, multiple complex degradations may occur during the imaging process, resulting in significant degradation of depth quality. To alleviate this drawback, we introduce a hybrid framework, named Learnable Fractional Reaction-Diffusion Dynamics (LFRD$^2$), which integrates the robust feature representation capabilities of neural networks with the interpretability of physical models. Specifically, we design a neural module implementing the time-fractional reaction-diffusion equation, which allows for iterative refinement to enhance depth quality, whose differential orders are generated dynamically. This module can correlate the current state of the predicted depth with any preceding states, keeping track of the long-term memory of the system itself. Furthermore, we propose a novel approach to construct an efficient continuous convolution operator based on coefficient prediction and repeated differentiation, further enhancing the final quality. Experimental results illustrate the effectiveness of our framework on four benchmark datasets. The code will be made available upon acceptance.
Chat is not available.
Successful Page Load