FedVLA: Federated Vision-Language-Action Learning with Dual Gating Mixture-of-Experts for Robotic Manipulation
{kind=link}
Abstract
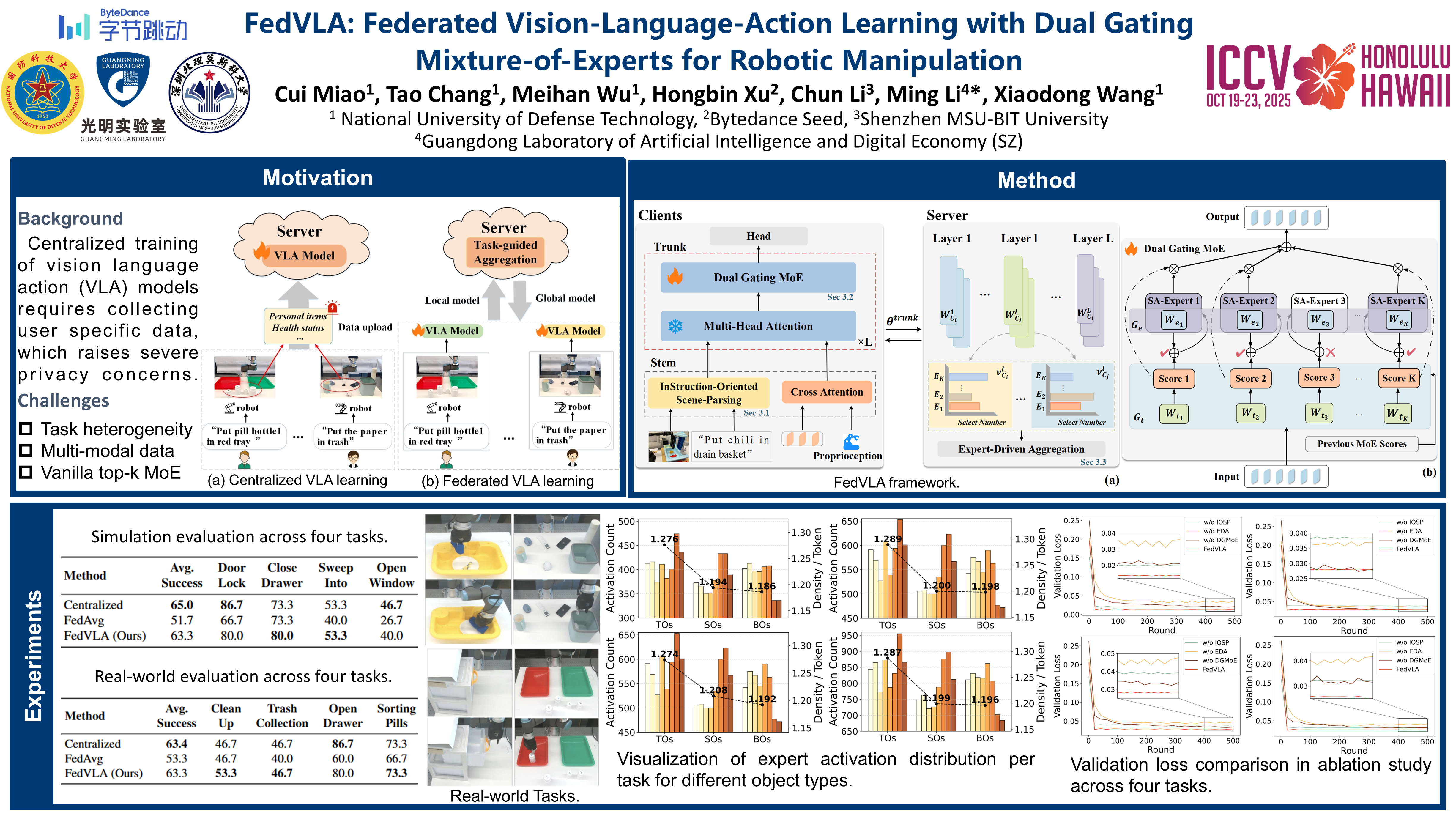
Vision-Language-Action (VLA) models have significantly advanced robotic manipulation by enabling robots to interpret language instructions for task execution. However, training these models often relies on large-scale user-specific data, raising concerns about privacy and security, which in turn limits their broader adoption. To address this, we propose \name{}, the first federated VLA learning framework, enabling distributed model training that preserves data privacy without compromising performance. Our framework integrates task-aware representation learning, adaptive expert selection, and expert-driven federated aggregation, enabling efficient and privacy-preserving training of VLA models. Specifically, we introduce an Instruction-Oriented Scene-Parsing mechanism, which decomposes and enhances object-level features based on task instructions, improving contextual understanding. To effectively learn diverse task patterns, we design a Dual Gating Mixture-of-Experts (DGMoE) mechanism, where not only input tokens but also self-aware experts adaptively decide their activation. Finally, we propose an Expert-Driven Aggregation strategy at the federated server, where model aggregation is guided by activated experts, ensuring effective cross-client knowledge transfer. Extensive simulations and real-world robotic experiments demonstrate the effectiveness of our proposals. Notably, DGMoE significantly improves computational efficiency compared to its vanilla counterpart, while FedVLA achieves task success rates comparable to centralized training, effectively preserving data privacy.