Scaling Action Detection: AdaTAD++ with Transformer-Enhanced Temporal-Spatial Adaptation
{kind=link}
Abstract
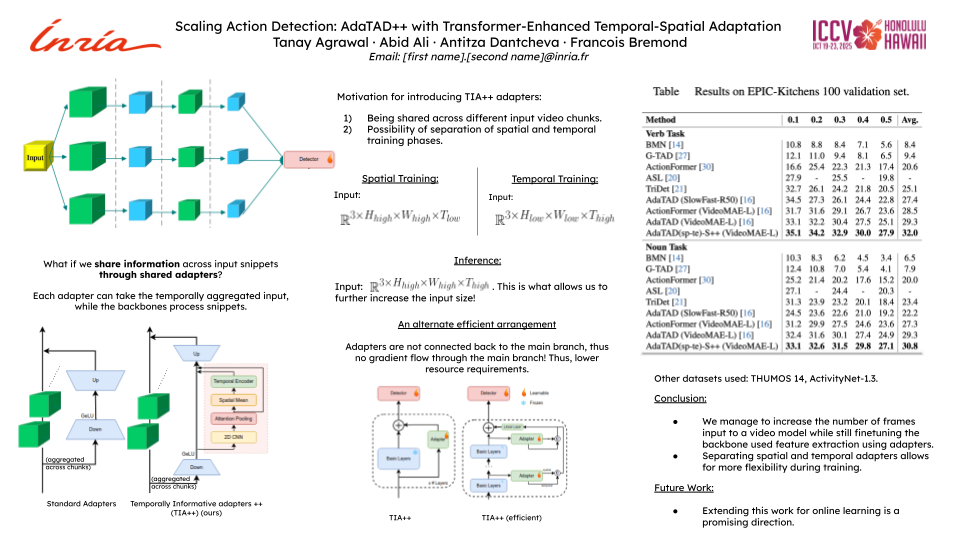
Temporal Action Detection (TAD) is essential for analyzing long-form videos by identifying and segmenting actions within untrimmed sequences. While recent innovations like Temporal Informative Adapters (TIA) have improved resolution, memory constraints still limit large video processing. To address this, we introduce AdaTAD++, an enhanced framework that decouples temporal and spatial processing within adapters, organizing them into independently trainable modules. Our novel two-step training strategy first optimizes for high temporal and low spatial resolution, then vice versa, allowing the model to utilize both high spatial and temporal resolutions during inference while maintaining training efficiency. Additionally, we incorporate a more sophisticated temporal module capable of capturing long-range dependencies more effectively than previous methods. Extensive experiments on benchmark datasets, including ActivityNet-1.3, THUMOS14, and EPIC-Kitchens 100, demonstrate that AdaTAD++ achieves state-of-the-art performance, surpassing existing methods in accuracy and efficiency. We also explore various adapter configurations, discussing their trade-offs regarding resource constraints and performance, providing valuable insights into their optimal application.