Free2Guide: Training-Free Text-to-Video Alignment using Image LVLM
Jaemin Kim ⋅ Bryan Sangwoo Kim ⋅ Jong Ye
2025 Poster
{kind=link}
Abstract
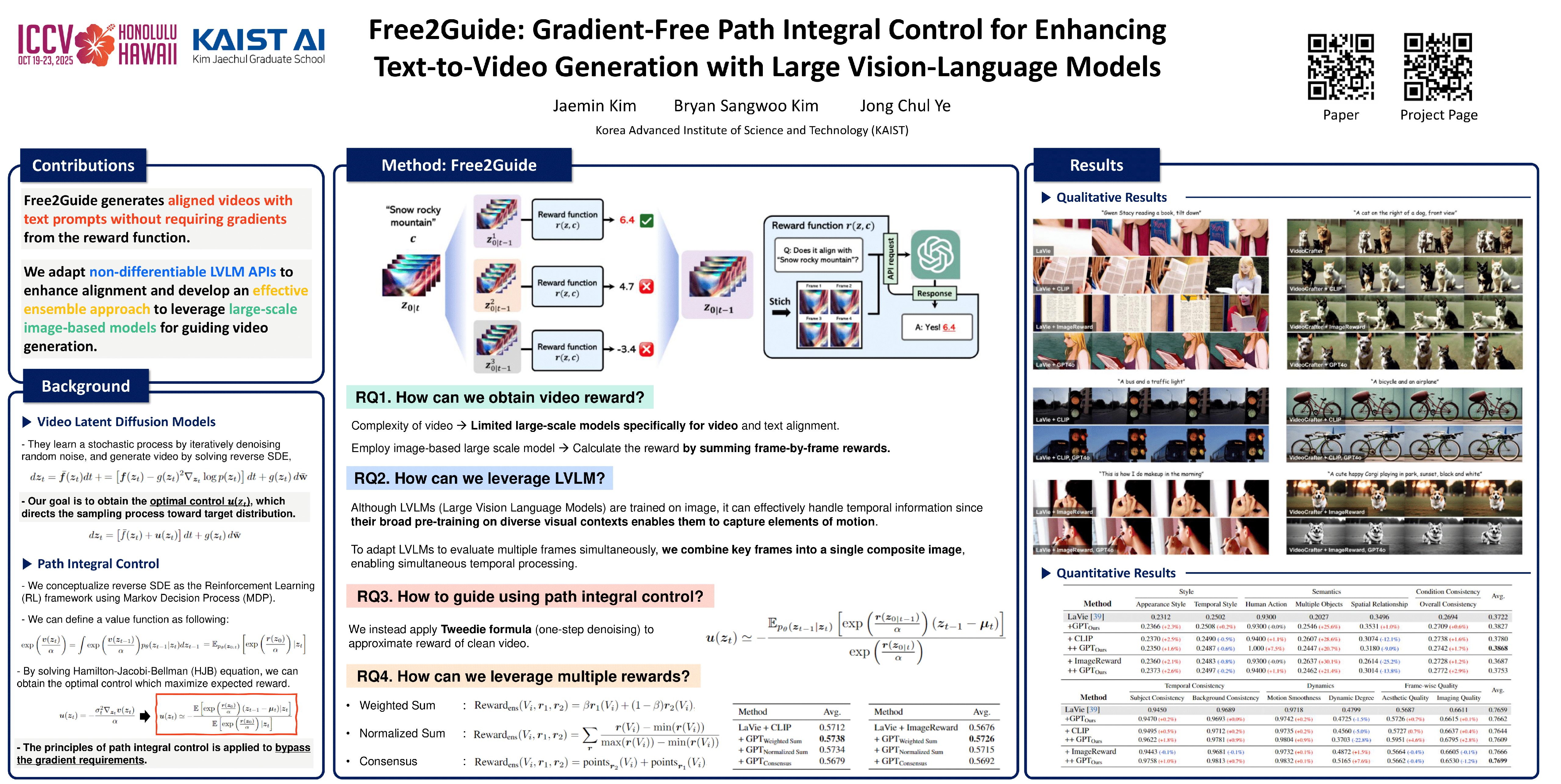
Diffusion models have achieved impressive results in generative tasks for text-to-video (T2V) synthesis. However, achieving accurate text alignment in T2V generation remains challenging due to the complex temporal dependencies across frames. Existing reinforcement learning (RL)-based approaches to enhance text alignment often require differentiable reward functions trained for video, hindering their scalability and applicability. In this paper, we propose Free$^2$Guide, a novel gradient-free and training-free framework for aligning generated videos with text prompts. Specifically, leveraging principles from path integral control, Free$^2$Guide approximates guidance for diffusion models using non-differentiable reward functions, thereby enabling the integration of powerful black-box Large Vision-Language Models (LVLMs) as reward models. To enable image-trained LVLMs to assess text-to-video alignment, we leverage stitching between video frames and use system prompts to capture sequential attributions. Our framework supports the flexible ensembling of multiple reward models to synergistically enhance alignment without significant computational overhead. Experimental results confirm that Free$^2$Guide using image-trained VLVMs significantly improves text-to-video alignment, thereby enhancing the overall video quality. Our results and code are available at https://free2guide.github.io/
Chat is not available.
Successful Page Load