CorrCLIP: Reconstructing Patch Correlations in CLIP for Open-Vocabulary Semantic Segmentation
{kind=link}
Abstract
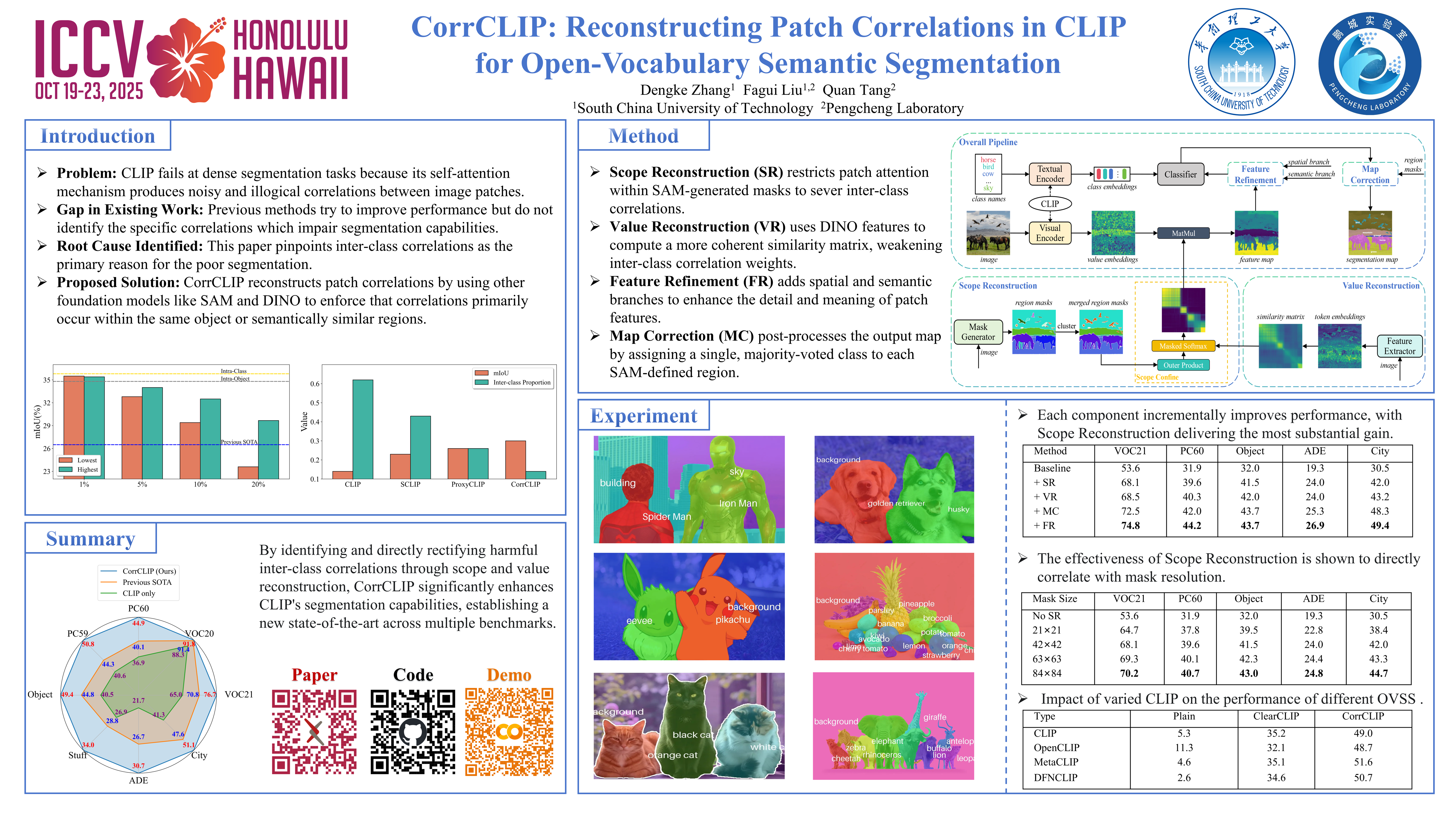
Open-vocabulary semantic segmentation aims to assign semantic labels to each pixel without being constrained by a predefined set of categories. While Contrastive Language-Image Pre-training (CLIP) excels in zero-shot classification, it struggles to align image patches with category embeddings because of its incoherent patch correlations. This study reveals that inter-class correlations are the main reason for impairing CLIP's segmentation performance. Accordingly, we propose CorrCLIP, which reconstructs the scope and value of patch correlations. Specifically, CorrCLIP leverages the Segment Anything Model (SAM) to define the scope of patch interactions, reducing inter-class correlations. To mitigate the problem that SAM-generated masks may contain patches belonging to different classes, CorrCLIP incorporates self-supervised models to compute coherent similarity values, suppressing the weight of inter-class correlations. Additionally, we introduce two additional branches to strengthen patch features’ spatial details and semantic representation. Finally, we update segmentation maps with SAM-generated masks to improve spatial consistency. Based on the improvement across patch correlations, feature representations, and segmentation maps, CorrCLIP achieves superior performance across eight benchmarks.