Aligning Moments in Time using Video Queries
{kind=link}
Abstract
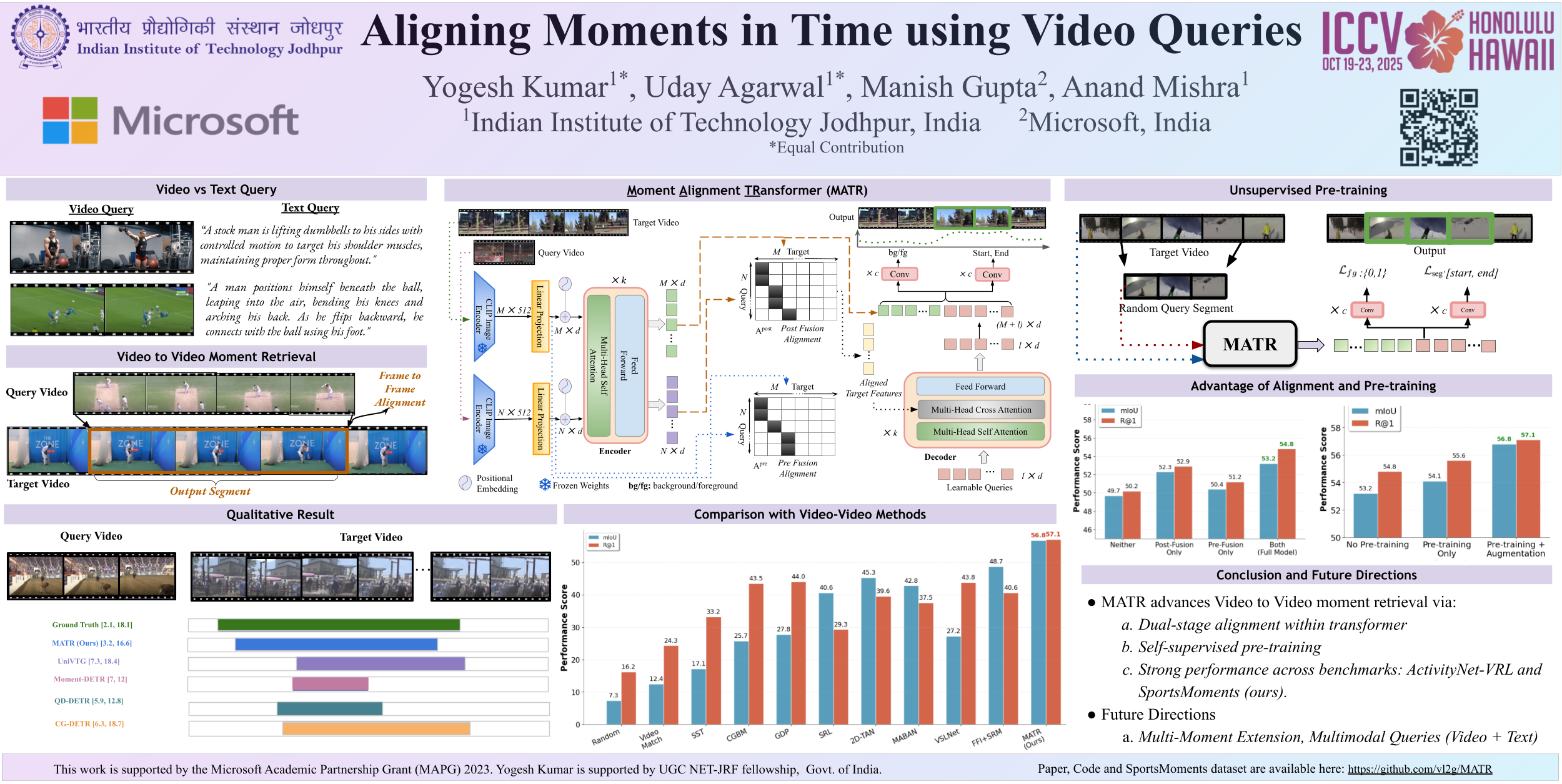
Video-to-video moment retrieval (Vid2VidMR) is the task of localizing unseen events or moments in a target video using a query video. This task poses several challenges, such as the need for semantic frame-level alignment and modeling complex dependencies between query and target videos. To tackle this challenging problem, we introduce MATR (Moment Alignment TRansformer), a transformer-based model designed to capture semantic context as well as the temporal details necessary for precise moment localization. MATR conditions target video representations on query video features using dual-stage sequence alignment that encodes the required correlations and dependencies. These representations are then used to guide foreground/background classification and boundary prediction heads, enabling the model to accurately identify moments in the target video that semantically match with the query video. Additionally, to provide a strong task-specific initialization for MATR, we propose a self-supervised pre-training technique that involves training the model to localize random clips within videos. Extensive experiments demonstrate that MATR achieves notable performance improvements of 13.1% in R@1 and 8.1% in mIoU on an absolute scale compared to state-of-the-art methods on the popular ActivityNet-VRL dataset. Additionally, on our newly proposed dataset, SportsMoments, MATR shows a 14.7% gain in R@1 and a 14.4% gain in mIoU on an absolute scale over strong baselines.