TokenUnify: Scaling Up Autoregressive Pretraining for Neuron Segmentation
{kind=link}
Abstract
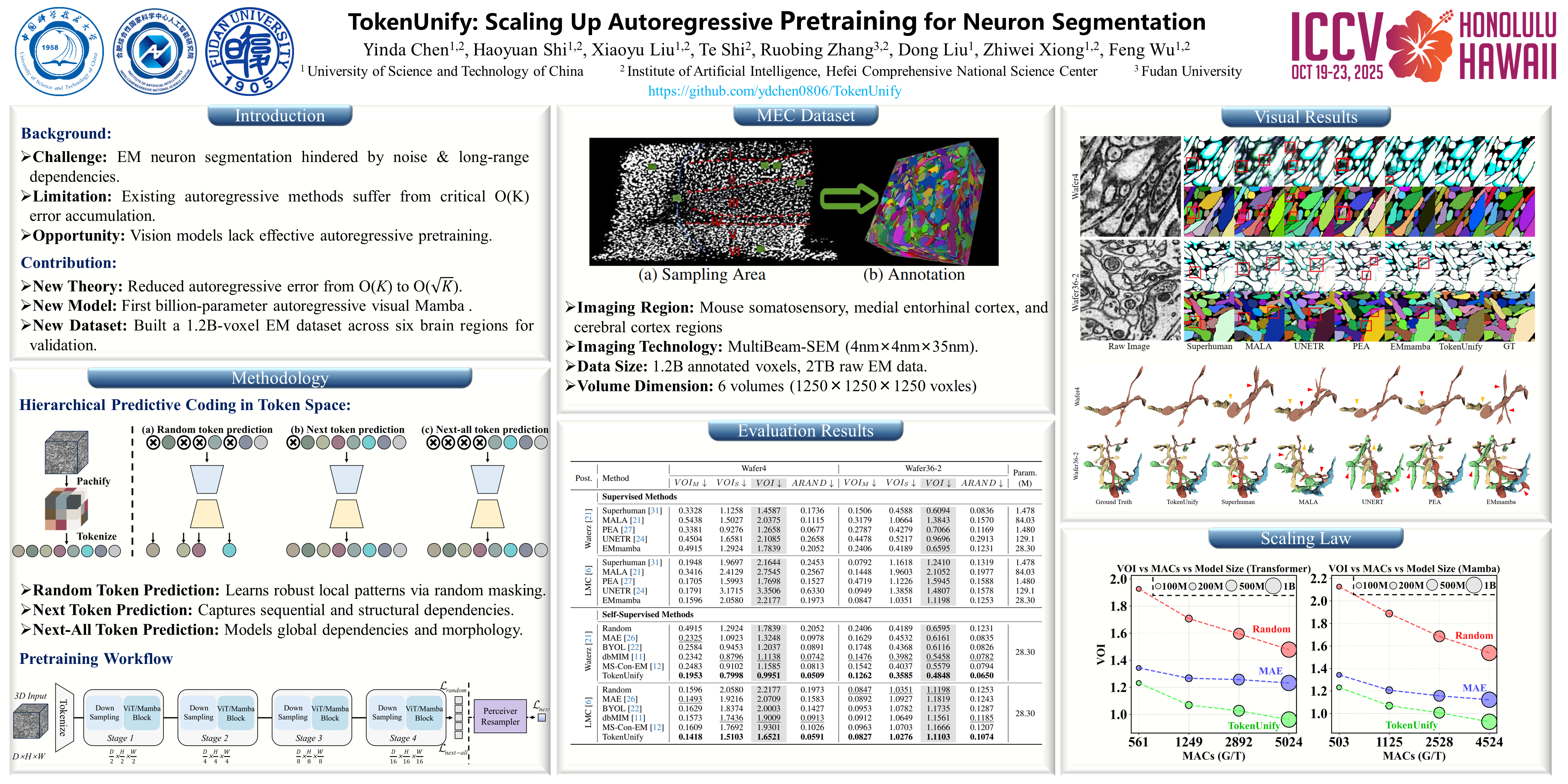
Neuron segmentation from electron microscopy (EM) volumes is crucial for understanding brain circuits, yet the complex neuronal structures in high-resolution EM images present significant challenges. Inspired by autoregressive pretraining in language models, we propose TokenUnify, a hierarchical predictive coding framework that captures multi-scale dependencies through complementary learning objectives. TokenUnify integrates random token prediction, next-token prediction, and next-all token prediction to create a comprehensive representational space with emergent properties. From an information-theoretic perspective, these three tasks are complementary and provide optimal coverage of visual data structure. We also introduce a large-scale EM dataset with 1.2 billion annotated voxels, offering ideal long-sequence visual data with spatial continuity. Leveraging the Mamba architecture's linear-time sequence modeling capabilities, TokenUnify achieves a 45\% performance improvement on downstream neuron segmentation and outperforms MAE by 21\%. Our approach demonstrates superior scaling properties as model size increases, effectively bridging the gap between pretraining strategies for language and vision models.