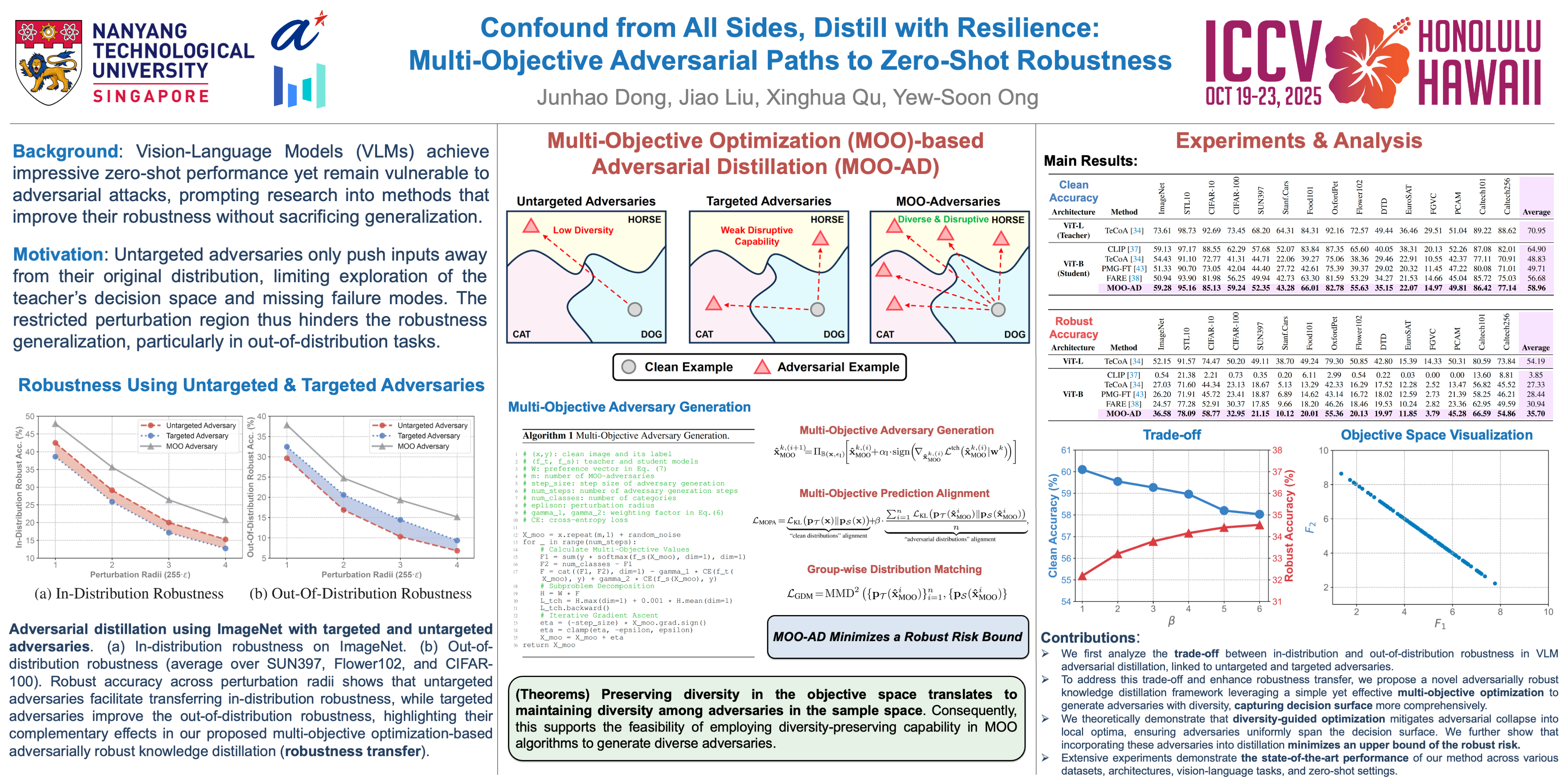
Robustifying Zero-Shot Vision Language Models by Subspaces Alignment
{kind=link}
Abstract
Vision-Language Models (VLMs) enjoy superb zero-shot performance but are vulnerable to adversarial attacks posing security risks. Adversarially robust fine-tuning enhances zero-shot robustness on new datasets while preserving the natural performance of pre-trained VLMs. However, prior methods use sample-wise adversarial fine-tuning, neglecting the underlying second-order statistics that represent entire groups of samples. This leads to a feature-level discrepancy between clean and adversarial samples of their augmented variants. Thus, we propose to represent groups of samples as subspaces to capture distributions and turn the traditional sample-wise adversarial fine-tuning into its distributional counterpart. For each image, we build distributions from (i) a clean sample with its augmentations and (ii) their adversarial counterparts. For text, we build distributions from (iii) a clean prompt and its synonymous prompts and (iv) their adversarial counterparts. We then perform alignment between image and text subspaces, and "adversarial" subspaces are also aligned toward "clean" subspaces. Thus, all samples underlying these distributions (think infinite number) also get aligned, leading to generalizable robustness. Evaluations on 15 datasets are provided.