B-VLLM: A Vision Large Language Model with Balanced Spatio-Temporal Tokens
{kind=link}
Abstract
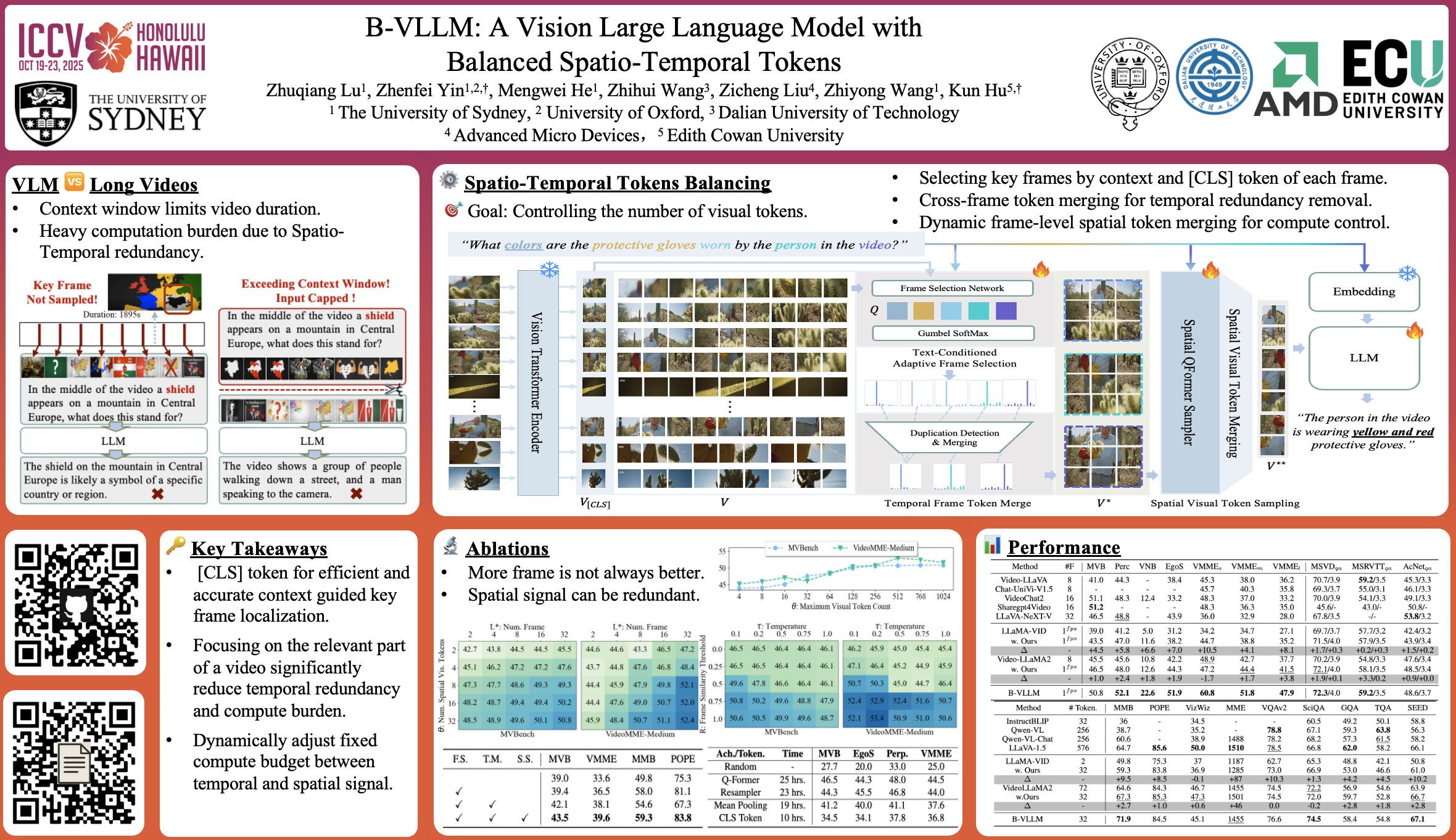
Recently, Vision Large Language Models (VLLMs) with integrated vision encoders have shown promising performance in vision understanding. They encode visual content into sequences of visual tokens, enabling joint processing of visual and textual data. However, understanding videos, especially long videos, remains a challenge as the rapid growth of visual tokens during video encoding risks exceeding VLLMs' context window length and significantly escalates computational cost. To restrict the number of visual tokens, existing VLLMs either: (1) uniformly downsample videos into a fixed number of frames or (2) reducing the number of visual tokens encoded from each frame. We argue that the former neglects temporal dynamics in videos, while the latter fails to preserve spatial details within individual frame. In this work, we propose Balanced-VLLM (B-VLLM), a novel VLLM framework designed to model task relevant spatio-temporal cues, while restricting the number of visual tokens within the VLLM's context window length. Central to our framework is a text-conditioned adaptive frame selection module that dynamically identifies task-relevant frames, which are further de-duplicated with a temporal frame token merging strategy.The visual tokens of these frames then undergo spatial token sampling and an optional spatial token merging strategy for granular control against the token budget. Experiments demonstrate the effectiveness of B-VLLM in balancing the number of frames and visual tokens, moreover, our proposed method introduce 10\% performance gain on MVBench. Our code will be publicly available.