TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
{kind=link}
Abstract
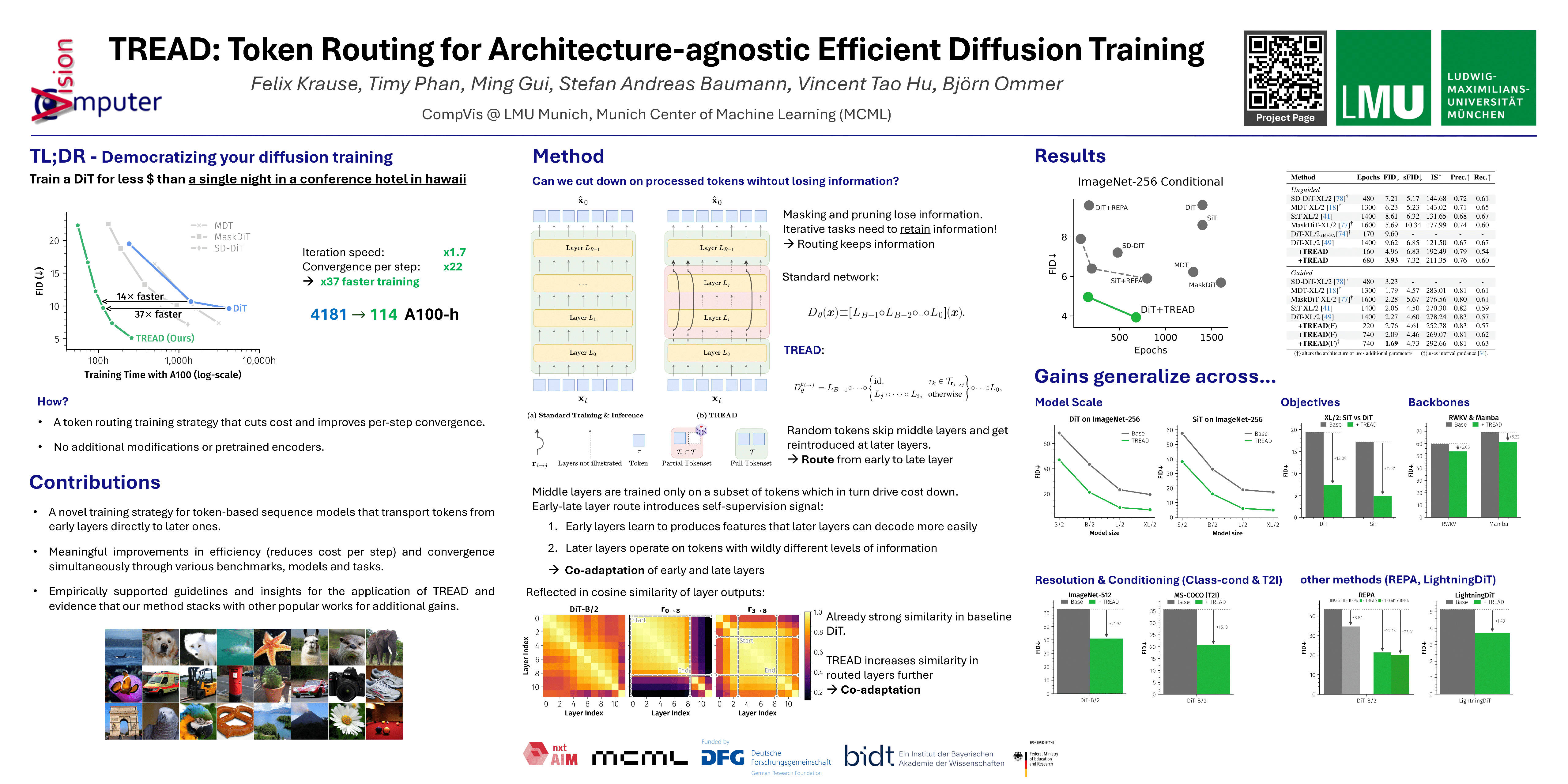
Diffusion models have emerged as the mainstream approach for visual generation. However, these models typically suffer from sample inefficiency and high training costs. Consequently, methods for efficient finetuning, inference and personalization were quickly adopted by the community. However, training these models in the first place still remains very costly. While several recent approaches—including masking, distillation, and architectural modifications—have been proposed to improve training efficiency, each of these methods comes with its own tradeoffs: some achieve enhanced performance at the expense of increased computational cost. In contrast, this work aims to improve training efficiency as well as generative performance at the same time through routes that act as transport mechanism for randomly selected tokens from early layers to deeper layers of the model. Our method is not limited to the common transformer-based model - it can also be applied to state-space models and achieves this without architectural modifications or additional parameters. Finally, we show that TREAD reduces the computational cost and simultaneously boosts model performance on the standard benchmark ImageNet-256 in class-conditional synthesis. Both of these benefits multiply to a convergence speedup of 14x at 400K training iterations compared to DiT and 37x compared to the best benchmark performance of DiT at 7M training iterations. Further, we achieve a competitive FID of 2.09 in a guided and 3.93 in an unguided setting which improves upon the DiT, without architectural changes. We will release our code.